4 研究一:大学生手机社交媒体依赖问卷的编制
4.1 大学生手机社交媒体依赖结构的初步构想及初始问卷的编制。。
4.1.1研究目的
初步构建大学生手机社交媒体依赖问卷的维度,编制大学生手机社交媒体依赖初始问卷。
4.1.2研究工具
开放式问卷(见附录一)、访谈(见附录二)。
4.1.3研究对象
开放式问卷随机选取重庆地区80名大学生为被试,共回收有效问卷72份,问卷有效率为90%,其中男生41人,女生31人;文科45人,理科27人。访谈从西南大学、重庆大学招募被试,共15人接受访谈,其中女生6人,男生9人;文科7人,理科8人。
4.1.4研究程序
依据访谈结果、开放式问卷以及文献分析,初步构建大学生手机社交媒体依赖问卷的维度并拟出手机社交媒体依赖问卷池(见附录三),问卷池共70个题项,通过邀请心理学的博士生和硕士生审定项目内容,请中文系学生鉴定词语表达的准确性,并请部分学生阅读问卷,找出内容效度低、表达不清楚、意思不明确的题项,初步构建大学生手机社交媒体依赖的基本结构并开始编制初原始问卷。
4.1.5研究结果
4.1.5.1结构的初步构想
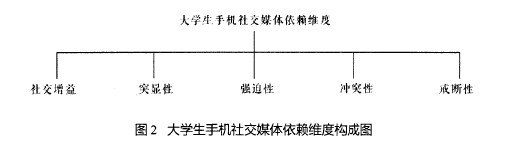
经过以上研究步骤,初步确定大学生社交媒体问卷由7个维度构成,分别是:突显性、强迫性、耐受性、戒断性、冲突性、社交增益、神经性。
突显性是指个体对手机社交媒体的使用已经成为个人主要的想法和行为;强迫性是指一种对手机社交媒体难以自拔的使用渴望与冲动;耐受性是指为获取之前同等的满足感,必须不断延长使用手机社交媒体的时间;戒断性是指当不能使用手机社交媒体时体验到的不愉快情绪;冲突性是指手机社交媒体的使用导致与生活、学习、工作中的其他行为发生矛盾;社交增益是指个人体验到的手机社交媒体的使用对人际关系的改善;神经性是指对手机社交媒体产生的一些精神层面上的错觉或不适。
4.1.5.1初始问卷的编制
初步构想了 7个维度之后,编制出大学生手机社交媒体依赖的初始问卷,问卷由48个题项组成(见附录四),分别为:突显性(8题)、强迫性(6题)、耐受性(6题)、戒断性(7题)、冲突性(8题)、社交增益(8题)、神经性(5题)。
4.2 初始问卷的修正
4.2.1研究目的
通过施测问卷并统计分析,探索验证大学生手机社交媒体依赖的实证结构与理论结构,并以此为基础编制大学生手机社交媒体依赖的正式问卷,为以后的研究提供测量工具。
4.2.2研究工具
大学生手机社交媒体依赖初始问卷(见附录四),其有突显性(8)、强迫性(6)、耐受性(6)、戒断性(7)、冲突性(8)、社交增益(8)、神经性(5) 7个维度,共48题。问卷采用5点记分方式,其中1代表非常不符、2代表不太符合、3代表一般、4代表比较符合、5代表非常符合,每题为单项迫选。
4.2.3研究对象
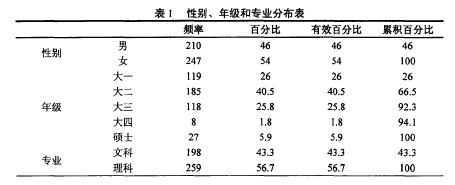
采用随机分层取样的方法在西南大学、重庆大学、重庆工商大学、重庆城市管理学院、重庆信息技术职业学院抽取被试,发放初试问卷520份,回收问卷457份,回收率为87.8%,研究者对问卷回答的完整性与真实性进行检查,剔除废卷,有效问卷中男女比例、年级分配、学科背景见表1:【1】
4.2.4施测过程
问卷由研究者以班级为单位进行集体施测,使用统一指导语,测试时间为15分钟,问卷作答完成后当场收回。
4.2.5统计分析
回收后的有效问卷采用SPSS20.0统计软件包进行统计处理。
4.2.6分析与结果
4.2.6.1项目分析
项目分析的主要目的在于检验编制的问卷个别题项的适切和可靠程度,项目分析的检验就是探究高低分的被试在每个题项的差异或进行题项间同质性检验,项目分析的结果可作为个别题项蹄选或修改的依据。根据吴明隆(2010),项目分析常用以下几种方法:
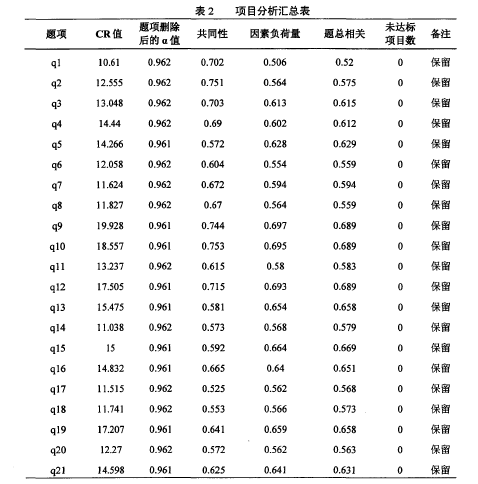
第一,T检验。T检验是指运用独立样本T-test检验问卷总分的高分组与低分组(本研究釆用总人数的27%来划分)在每个题项上的差异,如果题项在高低分组上的差异显着则说明该题项具有较好的鉴别力,本问卷通过T检验显示,49个题项P值均小于0.05,达到了显着性水平,说明问卷题项的鉴别力较好。(见表2)
第二,质性检验一:克隆巴赫a系数检验。该检验旨在检查题项删除后,整体问卷的信度系数变化情况,如果题项删除后的问卷整体的内部一致性a系数比原先的高处许多,则此题项与其余题项所要测量的属性或心理特质可能不相同,代表此题项与其它题项的同质性不高,在项目分析时可删除。本问卷整体a系数为0.962,第29题(q29)的题项删除后的a值为0.964,高于整体值,应予以删除,其余均小于等于0.962。(见表2)
第三,同质性检验二:共同性与因素负荷量。共同性(Communalities)表示题项能解释共同特质或属性的变异量,如将大学生手机社交媒体依赖问卷限定为一个因素时,表示只有一个心理特质,因而共同性的数量愈高,表示能测量到此心理特质的程度愈多;相反,如果题项的共同性低,表示此题项能测量的心理特质的程度少,共同性低的题项与问卷的同质性少,应考虑删除,因素负荷量(Factorloading)表示题项与心理特质关系的程度,题项在共同因素的因素负荷量愈高,表示题项与共同因素(总问卷)的关系愈密切,亦即其同质性愈高;反之,同质性愈低。依据Kavsek,Seiffge-Krenke(1996)法则,题项在提取共同因素的因素负荷量应>0.4,此时题项的共同性为0.16,提取的因素可以解释题项16%以上的变异量。本问卷中第29题和第44题的因素符合量小于0.4,故予以删除。(见表2)
第四,题总相关。如果个别题项与总分的相关愈高,表示题项与总体量表问卷同质性愈高,所要测量的心理特质与潜在行为更为接近。个别题项与总分的相关系数未达到显着的题项,或两者为低相关(相关系数小于0.4),表示题项与整体问卷同质性不高,最好删除。
本问卷通过题总相关显示,第29题(q29)与总分的相关系数为-0.175, p值虽达到显着水平,但两者的相关系数却很低,应予以删除。其余48题的题总相关在0.407——0.820之间,相关度较高。(见表2)【2】

4.2.6.2探索性因素分析
变量间的相关性是进行因素分析的先决条件(余建英,何旭宏,2003),变量间的相关特点用Bartlett球形检验,需达到显着;而KMO系数规定:KMO系数在0.9以上非常适合于做因素分析,在0.800.90之间为比较适合做因素分析,在0.76——0.80之间为可以做因素分析,在0.6——0.7之间为一般,但在0.6以下则不适合做因素分析。
符合进行因素分析的前提后,常用以下原则对因素进行蹄选:
第一,特征值(Eigenvalue)大于1。根据Kaiser(1960)年的观点,保留特征值大于1的因素,而特征值小于1的因素包含的信息量较少,故应予以舍弃。
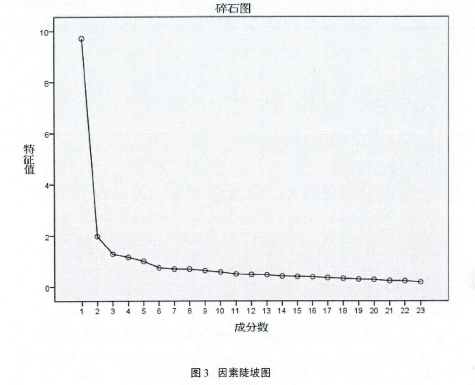
第二,陡坡图检验法(Scree plot test)。根据陆坡图因素变异量递减情形来决定,陆坡图以因数变异量(特征值)为纵坐标,因素数目为横坐标。根据CatteU(1966)的观点:因素数目可以通过寻找连续因素间信息量的突然下降来决定,因此,要保留陆坡图中明显转折左上方的因素。陡坡图发与特征值法结合起来才能产生较精确的因素数目。
第三,方差百分百决定法。方差百分百决定法是当所提取的共同因素所能解释全体变量的累积变量达到某一预设标准值后就停止继续抽取共同因素,之后的因素就不予保留。根据Hair等人(1998)的观点,在社会科学领域中,所提取的共同因素解释变异量在50%以上即可解释。
第四,因素解释率。抽取出的因素在旋转前至少能解释2%的总变异;每个因素至少包含三个条目。
第五,因素比较好命名。因素命名遵循的原则:参照理论模型的构想命名;看该因素的题项主要来自依据理论模型编制的预试问卷的哪个维度;哪个维度贡献的题项多,就以那个构想维度命名;参照题项因素的负荷值命名,即一般根据负荷值较高的题项所隐含的意义命名此外,选取适宜的因素个数m还应满足以下两个条件:①若抽取m-1个因素模型对相关结构的解释度显着下降;②若抽取m+1个因模型对相关的解释度无明显改善。
经过项目分析,剔除鉴别力不合适的题项3个,根据检验结果,KMO系数为0.953, Bartlet球形检验卡方值为12428.6,显着性为0.000,根据Kaiser(1974)的观点,该样本非常适合进行因素分析。对有效的题项进行主成分分析(PFA),提取共同因素,斜交旋转法(Delta=0.3),进行探索性因素分析,求出旋转因素负荷矩阵(见表3)。【略】
4.2.6.3分析结果
根据上述原则,共得到5个因素,结合幵放式调查和访谈的结果,并参照前人己有的有关研究,把先前建构的大学生手机社交媒体依赖问卷的维度进行了修订,认为大学生手机社交媒体依赖的维度主要有社交增益、突显性、强迫性、戒断性和冲突性五种:【3】
根据项目蹄选和因素分析的结果进一步修订原始问卷并专家评定,最后确定初试问卷共33个条目(见附录五)预期维度和观测项目为:社交增益(7题):q23、q22. q21、q25、q24、q4K q42突显性(7 题):q2、ql、q4、ql4、q5、q27、q3强迫性(6 题):q34、q33、q31、q32、q35、q43冲突性(6 题):ql7、ql6、ql8、q20、ql5、q40戒断性(7题):ql2、qll、qlO、q9、q37^ q39、q384.3正式问卷的编制。。
4.3.1研究目的
对修改后的问卷继续进行项目分析和探索性因素分析,优化题项。
4.3.2研究工具
使用大学生手机社交媒体依赖修改问卷(见附录五),包括社交增益、突显性、强迫性、戒断性和冲突性5个维度,共33题。问卷采用5点记分方式,其中1代表非常不符、2代表不太符合、3代表一般、4代表比较符合、5代表非常符合,每题为单项迫选。
4.3.3研究对象
采用随机分层取样的方法在西南大学、重庆师范大学学院、重庆工商大学、重庆医科大学抽取被试,发放初试问卷560份,回收问卷471份,回收率为84.1%,研究者对问卷回答的完整性与真实性进行检查,剔除废卷,有效问卷中男女比例、学科背景基本持平。
4.3.4施测过程
问卷由研究者以班级为单位进行集体施测,使用统一指导语,测试时间为10分钟,问卷作答完成后当场收回。
4.3.5统计分析
回收后的有效问卷采用SPSS20.0统计软件包进行统计处理。
4.3.6结果与分析
4.3.6.1项目分析
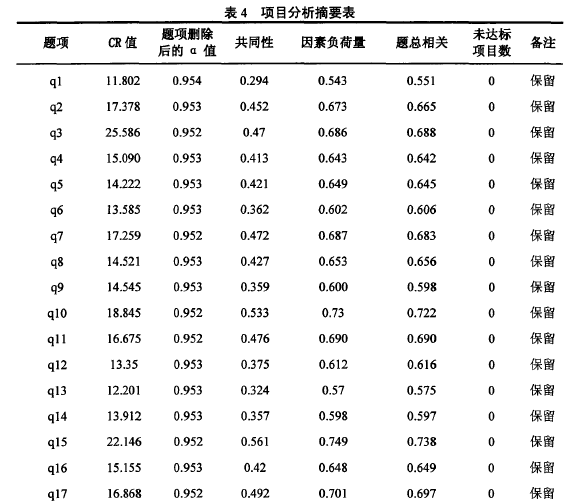
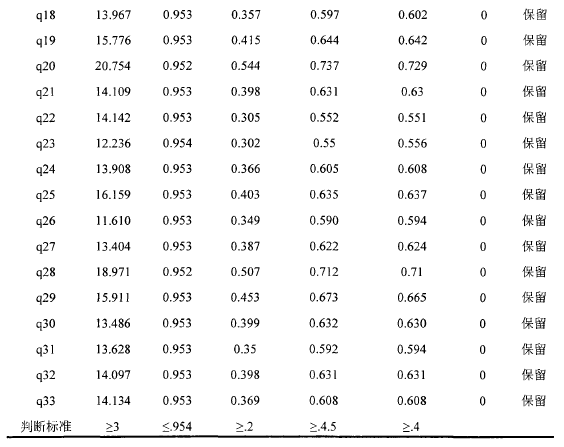
釆用极端组比较的决断值、题总相关、题项删除后的a值、共同性以及因素负荷量来进行蹄选,统计表明,各个题项鉴别力均良好。如表4:【4】
4.3.6.2探索性因素分析
首先,进行样本适当性分析。本研究参与因素分析的变量为33个,变量间的相关特点用Bartlett球形检验,其值为8568.11,显着性水平为0.000,说明变量间内部有共享因素的可能性。KMO检验值为0.950,证明该问卷非常适合做因素分析。
其次,蹄选并确定因素。进行因素数目确定时依据Browne提出的程序:①考虑研究者在理论中是否事先假设了因素个数;②考虑一些简单方法如Kaiser法Scree Test所提供的信息;③考虑由最大似然法所产生的模型拟合度的信息;④根据以上三方面的信息将可能的因素个数压缩到一个比较小的范围内;⑤根据④分别抽取不同个数的因素比较旋转后因素负荷的可解释性以做出最终决定。
确定因素个数常参照以下标准:①因素的特征值大于等于1,即因素的贡献率大于等于1;②因素必须符合卡特尔“陆阶”检验原则;③每个因素至少包含3个以上项目,④因素比较容易命名。最后确定5个因素(见表5、图3):【5】
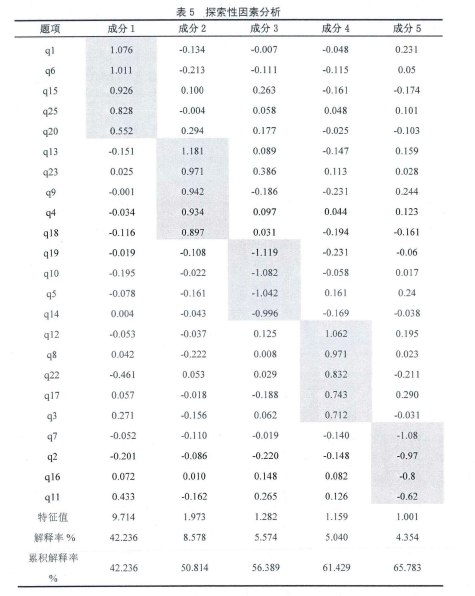
上表显示,5个因素的累积解释率为65.783%,题项的最高负荷为1.181,最低负荷为0.552,对抽取出的5个因素作如下描述和命名:
第一个因素共有5个题项,该因素的特征值为9.714,经最大旋转之后的方差解释率为42.236%,各题项涉及的内容均为大学生对手机社交媒体的使用已经成为个人主要的想法和行为,命名为“突显性”(Salience) 。
第二个因素共有5个题项,该因素的特征值为1.973,经最大旋转之后的方差解释率为8.578%,各题项涉及的内容均为大学生体验到的手机社交媒体的使用对人际关系的改善,命名为“社交增益”(Social Benefit) 。
第三个因素共有4个题项,该因素的特征值为1.282,经最大旋转之后的方差解释率为5.574%,各题项涉及的内容均反映了大学生对手机社交媒体难以自拔的使用渴望与冲动,命名为“强迫性”(Compulsivity)。
第四个因素共有5个题项,该因素的特征值为1.159,经最大旋转之后的方差解释率为5.040%,各题项涉及的内容均为大学生手机社交媒体的使用导致与生活、学习、工作中的其他行为发生矛盾,命名为“冲突性”(Conflict)。第五个因素共有4个题项,该因素的特征值为1.001,经最大旋转之后的方差解释率为4.354%,各题项涉及的内容均为当不能使用手机社交媒体时体验到的不偷快情绪,命名为“戒断性”(Withdrawal)。
4.4大学生手机社交媒体依赖问卷旳验证性因素分析
4.4.1研究目的
形成大学生手机社交媒体依赖问卷的验证性因素分析。
4.4.2研究被试
将测试回收的有效问卷中按单双号随机分组,其中400份用来对正式问卷(即根据探索性因素分析结果保留下的题项)进行验证性因素分析。
4.4.3统计工具
AMOS 20.0 for windows
4.4.4结果与分析
验证性因素分析(Confirmatory Factor Analysis,CFA)是探索性因素分析基础上发展起来的,是对已由理论模型与数据拟合程度的一种验证。运用验证性因素分析模型的适合性,一方面通过外因潜变量和观测变量之间的相关和负荷反映各因素之间的路径;另一反面,通过拟合指标反应模型的拟合程度。在实际运用协方差模型(SEM)进行分析时,常用的模型评价指数及其标准如下:/(chi-square)检验。研究者已发现x 2值受样本规模的影响较大,因而一般用卡方值与自由度之比(//df)作为替代性检验指数。其理论期望值为1,//df越接近1,表示协方差矩阵和估计的协方差矩阵之间的相似程度越大,模型的拟合性越好。实际研究中//df接近2,则认为模型拟合性比较好。在样本容量大的情况下,//df在5左右即可接受。
拟合指数。常用的拟合指数有拟合优度指数(goodness-of-fit index,GFI)、调整拟合优度指数(adjust goodness-of-fit index, AGFI)、标准拟合指数(normal fitindex, NFI)、非标准拟合指数(non-normal fit index, NNFI)、相对拟合指数(comparative fit index, CFI)、递增拟合指数(Incremental Fit Index,IFI)。这些指标的值均在0?1之间,越接近1越好,指数在0.95以上表示模型拟合很好,而在0.90以上就表示模型可以接受。近似均方根误差(RMSEA)小于0.05表示模型拟合很好,而在0.05?0.08之间表示模型拟合较好,在0.08?0.10之间仍可接受,但如果大于0.10,则表明这个模型拟合不佳。残差均方根RMR (Root Mean Square Residual),也是检验模合性的一个指标,其值越小越好。
此外,在考虑模型适合度时,还要看解答是否恰当,各参数的值是否在合理范围之内。基于上述考虑本研究选择了 >c2/df、GFI、AGFI、NFL CFI、IFI、RMR、RMSEA几个指数来对模型的适合度进行检验。运用AMOS 20 forwindows统计软件包对400份大学生手机社交媒体依赖问卷的结果进行验证性因素分析。采用极大似然估计检验五个因子的拟合程度,见图4。【6】
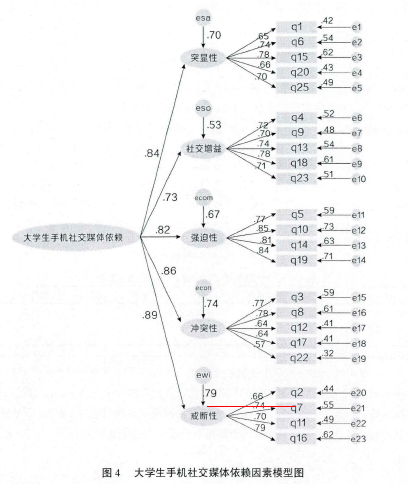

在表6中,所有指数都在合理范围,因此大学生手机社交媒体依赖问卷模型对数据拟合较好,验证性因素分析的标准化解的路径如图4所示。
由此,经过项目分析、探索性因素分析、验证性因素分析,形成了包括5个维度,共计23个题项,采用五点计分的大学生手机社交媒体依赖问卷的正式版(见附录六)。
4.5正式问卷的信效度分析
4.5.1问卷信度分析
因素分析结束后,需进一步了解问卷的一致性与稳定性,要做信度检验。所谓信度,就是问卷的可靠性与稳定性。常用的检验信度的方法为LJ.Cronbach所创的a系数。a系数值介于0到1之间。学者DeVellis (1991)认为:a系数值如果在0.60~0.65之间最好不要;a系数值在0.65~0.70之间为最小可接受值;a系数值在0.70~0.80之间相当好;a系数值介于0.8~0.9之间非常好。此外,分半系数(Guttman Split-Half系数)也是测量信度的重要指标,所谓分半信度是指将问卷的题目分成两半,根据被试在两半题项上所得的分数计算两者的相关系数。
估计内部一致性系数,用a系数由于分半系数,因为任何长度的测验都有多种分半方式,相同数据的不同分半方式求得的系数会存在一定差异。
考察本问卷的信度,主要采用内部一致性系数和分半信度两种方法。【7】

从表7可以看出,大学生手机社交媒体依赖问卷各因素的内部一致性系数(Cronbach's Alpha 系数)在 0.8060.897 之间‘各因素的分半系数(Guttman Split-Half系数)在0.739~0.874之间,整个问卷的内部一致性系数为0.937,分半信度为0.925,由此说明手机社交媒体依赖问卷具有良好的信度。
4.5.2问卷效度分析
考察测验效度的方法是多种多样,且各有其适应范围”本研究对问卷效度的考察主要采用了内容效度、结构效度和效标关联效度。
4.5.2.1内容效度(Content Validity)
内容效度是指一个测验实际测到的内容与所要测量的内容之间的吻合程度。
估计一个测验的内容效度就是确定该测验在多大程度上代表了所要测量的行为领域。
本研究内容效度的确定方法主要采用逻辑分析法,即请有关专家对测验题目与原定内容范围的吻合程度做出判断。问卷的题项来源于文献分析、开放式问卷调查、半结构化访谈以及相关测验中的一些题项来初步拟定的72道题项(见附录二),再请有关心理学专家、博士研究生、硕士研究等对问卷进行评定,转据专家意见,修订出54个项目之后,邀请50名本科生对问卷的表达明确性、通俗易懂度进行5点评分,踢出得分较低的5题后,发现其余题项的得分均在4.19以上,表明问卷题项通俗易懂、意思明确。以上程序保证了本问卷良好内容效度。
4.5.2.2结构效度(Construct Validity)
结构效度是指一个测验实际测到所要测量的理论结构和特质的程度,或者说它是指测验分数能够说明心理学理论的某种结构或特质的程度。分析结构效度的常用方法是因素分析法。通过探索性因素分析本研究得出了大学生手机社交媒体依赖由五个因素构成,即突显性、社会增益、强迫性、冲突性、戒断性,这与最初的理论构想基本一致,初步表明结构效度良好。
根据因素分析的理论,各个因素之间应该呈中等程度相关,若相关过高则说明因素之间存在重合;反之,相关过低则说明可能测量到的是与所想要测量的是完全不同的内容。
本问卷进行相关分析显示:各因素与问卷总分的相关系数在0.770—0.836之间(pO.OO,而各因素之间的相关系数为0.443—0.618之间(pO.Ol)。相关数据见表8:【8】
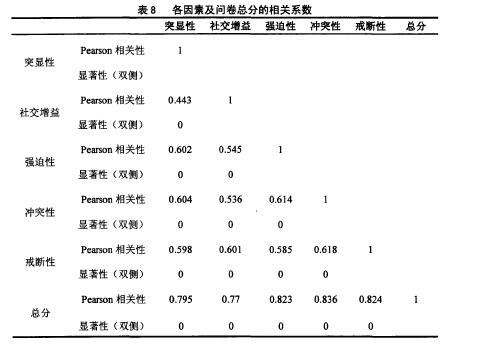
上表可以看出,问卷各个因素之间相关均达到显着性水平,这表明各因素构成了一个有机联系的整体。问卷的总分与各因素指教相关较高,而因素间相关为中等程度,说明因素之间具有一定的独立性,并且各因素又较好地反映了问卷所要测量的内容。因而本问卷具有良好的结构效度。





