5 大数据在 TC 企业管理中应用效果
5.1 大数据在优化课程产品设置方面的应用。
大数据在企业中的应用一般包括大数据采集、大数据预处理、大数据存储及管理、开发大数据安全,大数据技术、大数据分析及挖掘、大数据展现和应用。语言类教育培训 TC 企业最终选择了市面上比较流行的开源软件 Hadoop,通过 MapReduce 分析 TC 企业中的半结构化日志数据,对课程产品方面进行分析,过程如下。


5.1.1 大数据采集。
语言类教育培训 TC 企业大数据的获取途径可以分为两类:第一种:企业内部大数据,即通过企业自己的相关软件、平台、系统、移动端 APP 等进行收集到的数据;第二种:外部大数据,即非企业内部的数据,例如通过购买、爬虫等方式收集到的百度、腾讯 QQ、新浪微博、微信、淘宝、京东、当当、亚马逊、爱奇艺、PPTV 助力、优酷土豆的数据。以下为 TC 企业内部数据采集所得。
语言类教育培训 TC 企业通过用户在官网、搜课、移动端各个平台的操作,记录到Log 日志中。北京学校存储这些 Log 日志的服务器有 12 台,每台服务器按日存储在一个文件中,每个 Log 日志文件大约为五、六百兆。所以 Log 日志文件在一个月内产生的文件大小共计约为 211 T(12 台服务器*30 天*600M / 1024 =210.9375 T)。我们都知道,之所以使用 Hadoop 来处理数据,首先是因为数据量大,而目前 TC 企业一个月内的 Log日志文件不足以称其为大数据,但是因为所有 Log 日志存放在不同的服务器中,而且 Log日志的格式又属于半结构化,所以只能选择具有分步文件处理功能,而且能处理半结构化数据的大数据处理软件 Hadoop 平台。Log 日志文件的格式如图。
5.1.2 大数据预处理。
因为语言类教育培训 TC 企业在官网、搜课、移动端各个平台上记录 Log 日志格式的统一性,所以对于大数据的数据收集相对简单和容易,只要对数据进行简单清洗的工序,可直接进入数据分析过程。
5.1.3 数据分析思路。
(1)、假设:根据目前 TC 企业英语类班级的 0.2、小语种班级的 0.1 的转化率为基础进行的假设。英语类班级每 100 个点击量会产生 2 个报班名额;小语种类班级每 100个点击量会产生 1 个报班名额;(2)、设定阀值:班级点击量与原班级正常人数之比为 0.5;(3)、按日对未报名记录进行分类操作;(4)、按日对每个班号的 IP 进行去重操作;(5)、按限制时段,如按月或周对每个班号的 IP 进行去重操作;(6)、按月或周对每个班号进行不同 IP 的累计,即统计班级 IP 访问量;(7)、计算:
(7.1)、英语:班级 IP 访问量乘以英语班级转化率,再除以班级正常人数;公式:英语班预报名量 = 班级 IP 访问量 * 转化率 / 班级正常人数;(7.2)、小语种:班级 IP 访问量乘以小语种转化率,再除以班级正常人数;公式:小语种班预报名量 = 班级 IP 访问量 * 转化率 / 班级正常人数;(7.3)、英语班预报名量 <0.5 时,准备调整减少资源(合并班级或取消班级);英语班预报名量 >=0.5 且英语班预报名量 <=1 时,不调整;Int(英语预报名量)>1 并且 Mod(英语班预报名量)>0.5 时,准备调整增加资源(新开班级、增加教师、助理、教室、电脑、桌椅、耳机、教材等,新开班级数量为 Int 取整数值-1 的个数,然后再根据 Mod 取余的值大于 0.5 时+1,否则+0 表示新开班级个数);(8)、根据实际结果调整假设与阀值。又因为语言类教育培训 TC 企业与学生上学周期相关,不能简单的按照环比结果进行调整,还需要多年的数据积累按同比结果进行调整。
5.1.4 MapReduce 课程产品分析。
根据 5.1.3 条中的数据分析思路,使用 Map 和 Reduce 对课程产品数据进行分析,下列提供的是伪代码。说明:每台服务器按日产生的日志文件名称分别为Log1-20170828.log、Log2-20170828.log、……Log12-20170828.log。文件名的开头LogN-XXXXXXXX.Log 中的“N”表示对应着服务器编号,“XXXXXXXX”表示为日志记录日期。为了描述方便,拷贝 2017 年 12 月 29 日、30 日的第 1 台服务器的部分日志,31 日12 台 服 务 器 的 部 分 日 志 进 行 举 例 说 明 , 详 见 附 件 《 Log1-20171229.log 》、《Log1-20171230.log》、《Log1-20171231.log》--《Log12-20171231.log》。
(1)、分类 Classfication 操作,为了剔除掉已经报名客户的点击记录,只将未报名的客户记录留下,使用 Classfication 操作命令来实现。按日将未报名记录进行分类存放在一个文件中。
Mapper 代码中的 FileName 参数接收的文件名为 Log1-20171229.log。分类伪代码如下:
Class MapperMethod map (FileName, FileContent)for each line in fileContent doitem = getItem (line)caculatedValue = givenFunction (item)emit (caculaltedValue, line)Reduce 代码中的 File 参数输出的文件名为 Log1-20171229- NoEnroll.log。
class Reducermethod reduce (caculatedValue,[line1, line2,……])file = openFile (caculatedValue)for each line in [line1, line2,……] dosaveToFile (file,line)emit (caculatedValue, file)依次对这 15 个部分日志文件进行分类操作,剔除掉已经报名客户的点击记录。
(2)、去重计数 Distinct Counting 操作,是对在一天内访问同一班的相同 IP 进行去重操作。我们假设一个 IP 代表一个潜在客户,而同一天内访问同一班级信息的相同 IP 只能被统计一次。去重计数操作分为两步。第一步,map 函数将每条记录中需要统计的 IP 地址和班级编号属性作为关键字,将 1 作为中间结果值输出,reduce 函数将相同组合去重输出。目的是为了生成不重复的 IP 地址和班级编号记录集。第二步,map函数将被统计的班级编号属性值作为关键字,将 1 作为中间值输出,reduce 函数则将中间结果输出的值序列进行累加给出最终结果。Property1, Property2 分别为统计属性的IP 地址和班级编号。
第一步去重计数设计模式阶段 mapper 代码Class Mappermethod map (fileName, fileContent)for each line in fileContent do<property1, property2> = getProperties( line )emit ( <property1, property2>,1)第一步去重计数设计模式阶段 Reducer 代码class Reducermethod reduce ( <property1,property2> , [count1, count2,…])emit ( <property1, property2>, null)第二步去重计数设计模式阶段 mapper 代码class Mappermethod map ( <propety1, property2>, null)emit( property2, 1)第二步去重计数设计模式阶段 Reducer 代码class Reducermethod reduce (prperty2, [count1,count2,…])emit ( property2, sum([count1, count2,…])(3)、按限制时段,在春季或秋季时段内,对于泡泡幼儿、小学、初中、高中、大学等年级按月对每个班号的 IP 进行去重操作和按月对每个班号进行不同 IP 的累计;在暑假、寒假时段,同样是泡泡幼儿、小学、初中、高中、大学等年级按周对每个班号的IP 进行去重操作和按周对每个班号进行不同 IP 的累计。若对于出国留学相关的考试如托福、GRE、雅思等,在刚刚结束考试后,可按月进行累计;若在这些相关考试一至两个月前,则需要调整为按周进行统计。只要重复第 2 点中的操作,在代码中给出开始和结束日期即可。
为了更好的理解上述操作后的效果,基于提供的 15 个日志附件,将每个 Log 文件的半结构化数据转换成结构化数据,如《日志整理 终-郭丽梅-20180227.xlsx》中的“汇总(942)”页签,总计有 942 条记录。经过第一阶段的分类操作,每个日志文件去除掉已报名数据形成新的文件,将半结构化数据转为结构化数据,如《日志整理 终-郭丽梅-20180227.xlsx》中的“未报名(906)”页签,是按每个日志文件删除掉已报名信息后,只有未报名信息的数据,剩余 906 条记录。经过第二阶段的去重操作,通第一步的 Mapper、Reducer 代码将每个文件中访问班级的信息加上 IP地址作为一个记录即访问数量记为 1,等整个文件将所有信息记录完成后,如《日志整理 终-郭丽梅-20180227.xlsx》中的“按日去重(899)”页签,总计有 899 条记录;经过第二步的 Mapper、Reducer 代码将课程信息相同,且 IP 地址相同的数据跳过不累计。经过第三阶段的操作,将 29、30 日的 2个文件与 31 日的 12 个文件中所有课程相同且 IP 地址相同的信息删除后,剩余信息转成结构化数据,如《日志整理 终-郭丽梅-20180227.xlsx》中的“按时段去重(893)”
页签,总计有 893 条记录;去重后对每个班级数据统计后的结果见《日志整理 终-郭丽梅-20180227.xlsx》中的“统计”页签;(4)、对于通过 MapReduce 统计出的班级与 TC 企业北京学校数据库中的班级设置表中进行比对。根据班级属性区分是英语类还是小语种类,分别进行计算。计算公式如5.1.3 小节中第 7 点计算方法进行计算,然后进行班级合班、取消班级或增设同类班级等工作。
根据《日志整理 终-郭丽梅-20180227.xlsx》中的“统计”页签中每个班级访问的次数进行计算。以访问次数最多的班级“初一提高英语寒假班(预报班)”为例,3 天部分日志统计后的访问次数为 55 次。此班为 K12 的英语类班级,班级类型为大班课程 25人班。又因为此班级是为寒假设置的班级,所以以七天为一个周期进行统计。29 和 30日只有 1 台服务器的部分文件,而 31 日虽然有 12 台服务器的文件,但是每个日志文件都是晚上 20 点以后的内容,因为日志提供量的限制,所以将已有日志访问量作为半天数据的访问量进行假设,那么七天总的访问量为 55 * 2 * 7 = 770 次。根据以往的 0.2转化率计算,770 * 0.2 ≈ 16 人,也就是说将要报此班的学员可能有 16 名,达到班级设置的最大人数 25 人的一半,可以开班。安排班级占用 25 人的大班教室,而富裕的配套设施可供其它班级借用。假设根据访问量计算出此班学员为 13 人时(超过班级设置人数的一半可开班),可调整为 12 人的中班教室,增加一套配套设施即可。
根据日志访问量的数据可以提前预测每个班级将要报名的人数,管理人员可以提前做出相应的准备工作,而不至于在开课前临时调整而产生大量的沟通或管理成本,提高了工作效率。
(5)、通过上一次或上几次的班级预调整数值与实际结果的比对,调 5.1.3 小节中第 1 点的假设值和第 2 点的阀值。希望通过几年的同比数据和环比数据将阀值调整到最理想的范围内。
5.1.5 课程设置数据比对。
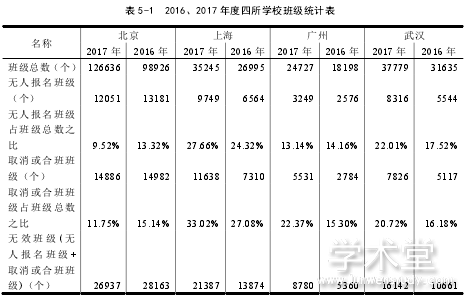
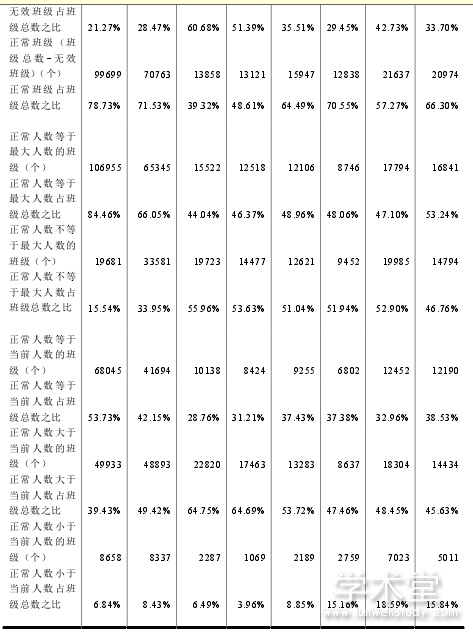

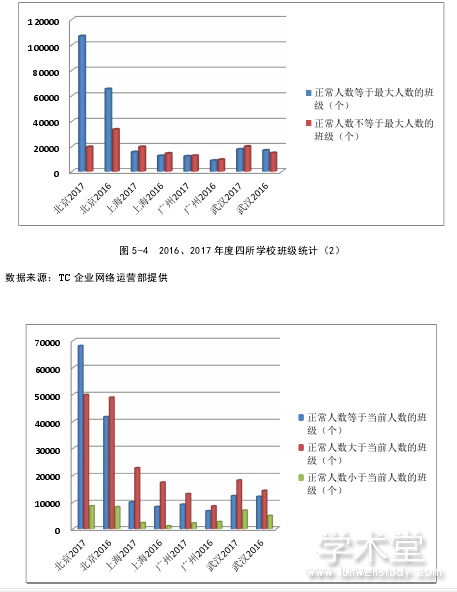
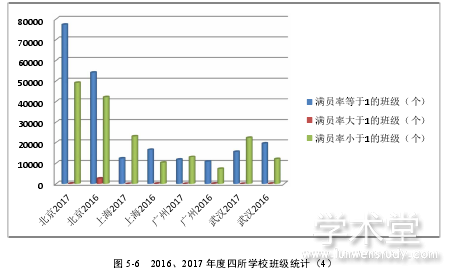
26 个增加了 98926个班级。在增加了将近十万个班级的情况下,无人报名班级由 2016年的 13181 个减少到 12051 个,不但没有随着班级设置量的增加而增加无人报名班级个数,反而有所减少。在未使用大数据技术的上海、广州、武汉三所学校中,2017 年度设置班级数量比 2016 年度也都略有增加,在没有辅助工具和统计数据的帮助下,随着设置班级数量的增加,无人报名班级数量也随着增加。北京学校总班级数量、无人报名班级数量、取消或合并班级数量、正常人数与最大人数是否相等班级数量、正常人数与当前人数是否相等班级数量、班级满员率的各项统计数据,有力的证明了大数据技术对日志数据分析后的班级相关预测数据的正确性。
5.1.6 分析。
虽然通过运用日志大数据前后两年的数据比对证明运用日志大数据分析后,对于设置课程产品的班级容量和班级个数有明显的提升,但是只一年的数据还不足以充分证明目前的假设和阀值是永远正确的、一成不变的,要根据多年的数据跟踪和实际情况的反馈进行调整,以至于使得预测数据越来越接近真实数据,这样才能使得大数据理论和技术在 TC 企业中发挥真正的优势和作用。





