美军国防语言研究的主要方向和特色
时间:2014-07-22 来源:未知 作者:傻傻地鱼 本文字数:8473字
随着我国综合国力的提升和国家利益的拓展,语言能力日益成为军队实力的重要组成部分。
在情报整编、反恐维稳、国际合作等诸多事务中,语言能力的高低已经成为影响甚至决定军队战斗力的重要因素。作为语言能力建设起步较早的国家,美国在语言政策的制定与实施、语种的统筹和规划、语言人才的储备与管理、语言研究的引导与支持等方面有很多经验值得我们借鉴。然而,以往国内学者在探讨美军语言能力时,主要集中研究美国的国防语言战略,却较少关注语言研究在推动美军语言能力中发挥的重要作用。针对这种情况,本文将通过分析美国军方资助的语言研究项目,梳理美军国防语言研究的主要方向和特色,以期对我军语言能力建设提供借鉴。
一、研究方法
(一)数据来源
本研究所用数据来自于美国国防科技情报中心(The Defense Technical Information Center,简称DTIC)。该中心隶属于美国国防部,是美国最大的国防信息服务机构,其潜在用户为美国国防部工作人员以及与国防部合作的承包商、大学和研究所。该中心收录了与国防科技相关的各类资料和数据,包括技术报告、项目进展报告、学位论文、参考文献等,其中部分非密级信息面向公众开放。通过分析该中心收录的科研项目信息,可以较全面地揭示美军对现实语言需求的认知与把握,以及美军语言研究的主要方向和应用领域。
(二)数据处理
我们以language、linguistic和linguistics作为关键词,在美国国防科技情报中心数据库中检索出所有与语言相关的研究报告,共1990篇。出于保密等考虑,该数据库仅公开其中1000条数据信息。这会在一定程度上影响分析结果的全面性,但并不妨碍我们针对总体趋势进行探索性的分析。
每一条数据信息主要包括以下内容:报告编号(Accession Number)、题目(Title)、报告类别(Descriptive Note)、作者单位 (Corporate Au-thor)、作者姓名 (Personal Author)、报告日期(Report Date)、报告摘要(Abstract)、关键词(De-scriptors)、学科类别(Subject Categories)。我们将以上信息逐条拷贝下来,组成本研究的基础数据。需要指出的是,部分年代较为久远的研究报告,在数据库中仍然以PDF格式存储,需要我们手工将其中的关键信息摘取出来。在数据收集过程中,我们发现1000篇文献有一定的重复。去除重复数据后,共得到821条数据,数据的年代最早是上世 纪60年代,它们组成了本研究的数据来源。
(三)数据分析
本研究主要采用聚类分析的方法,将所收集的文献数据分成若干代表不同研究领域的子集。
在聚类之前,首先对文本进行了预处理,主要包括停用词过滤、词形还原、矩阵生成等步骤。然后,利用CLUTO工具进行自动聚类。参照Zhao &Karypis,本研究采用的是重复二分法(repeatedbisection)和h2判别标准作为聚类分析的基本算法组合。在经过若干次比对后,我们最终将聚类数目定为12。
按照聚类质量由高到低,表1列出了12个聚类的基本信息,分别是聚类编号、文本数目、内部相似度、内部相似度标准差、外部相似度、外部相似度标准差。
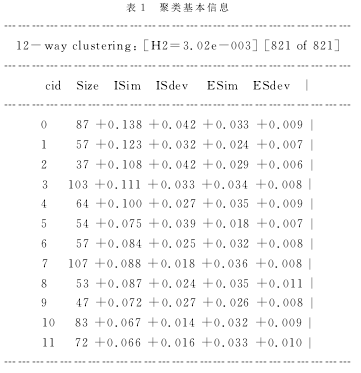
二、研究结果
在文本聚类后,我们对各聚类的项目摘要逐一仔细研读,以总结美军语言研究的主要方向和特点。在梳理过程中,我们发现聚类0和聚类9的研究内容高度相似,因此将其合并。聚类8中的研究项目主要是关于计算机编译语言,我们认为该聚类不属于语言研究的范畴,因此将其剔除。
最终,我们得到了代表以下10个研究方向的项目聚类。
(一)语音识别研究
(聚类0和聚类9)美国军方早在上世纪60年代以前就开始资助有关语音识别的研究。
1974年兰德公司的一份项目报告,就已经对语音识别技术的应用前景表示足够的乐观。1960年代的语音识别研究,主要关注的是语音信号的识别,即语音信号向对应语言符号的转换。研究者从发声学、音位学、声学、听觉语音学等多个角度对英语、俄语、德语、汉语、日语、朝鲜语等多种语言的语音特征进行描述和分析。1970年代,语音识别已经从语音信号的识别发展到语音意义的理解上。自然语言处理技术(如词性标注、句法分析等)开始更多地融入语音识别研究中。
1980年代,正如兰德公司的预测,语音识别技术已经开始应用到诸多军事领域,各研究机构和大学相继开发出涉及语音识别技术的人机交互系统,如IBM公司的MASTOR系统(语音翻译系统)、卡耐基梅隆大学的SPHINX系统、麻省理工学院的VOYAGER系统、SRI国际公司的ATIS系统(Air Travel Information Sys-tem)等。
1990年代,基于统计的方法开始在语音识别研究中广泛应用。2000年以后,几乎所有受军方资助的语音识别项目都与语音数据库建设有关。研究者们意识到,缺乏基础语音数据库,尤其是在特殊条件下或面 向 特殊用 途 的语音数据库,严重制约了语音识别技术的发展。
(二)语言、文化与区域知识研究(聚类1)上世纪60年代,美国国防分析研究院的一份报告论述了美军在越 南 战场上 遇 到的语言问题。
此后20年间,没有在美国国防科技情报中心的公开数据中发现类似的研究报告。
1980年代末至1990年代初,陆军行为及社会科学研究所和陆军战争学院针对军队语言能力建设提出了许多建设性的意见,如提高全体部队人员的语言意识、建立语言学习奖励机制、追踪部队人员语言水平、开展不间断语言评测等。这些建议基本都成为了日后美国国防语言政策的重要组成部分。
2000年以后,“9.11事件”和反恐战争促使美军更加重视军队语言能力建设,同时文化能力被赋予了与语言能力同等重要的地位。
2007年,陆军指挥参谋学院的一份报告指出,国防语言变革路线图(Defense Language Transfor-mation Roadmap)和美国国防部第3000.05号指令(Department of Defense Directive 3000.05)都存在一个重大缺陷,即只注重了文化和语言能力,却忽略了区域知识的重要性。
报告进一步指出语言、文化和区域知识应该三者合一。
2009年以后,美军开始反思现有的国防语言政策。陆军行为与社会科学研究所和兰德公司都指出,语言、文化和区域知识固然重要,但未必需要每一个士兵都具备同等能力。有关语言、文化、区域知识与部队战斗力之间的关系,还需要深入研究。
(三)个体因素研究(聚类2)该聚类所涉及的项目报告数量相对较少
20世纪60年代,兰德公司开展了有关语言相对论的研究,表明美国军方很早就开始关注语言与认知的关系。1970年代,应用语言学中心开展了有关语言学能的研究,目的是能够更准确地挑选出具有语言学习天赋的士兵。1980年代,几乎所有的研究都与语言学习策略相关。
1990年代,研究者开始关注信息整合能力(co-ordinating abili-ty)、方位能力(orienting ability)、交际畏惧心理(communication apprehension)等问题。在这些研究中,语言能力本身并不是研究的直接对象,而是衡量和评估各种认知能力的重要手段。
2000年以后,该领域研究的军事应用性更强,如通过语言分析自动识别潜在敌人的意图、利用话语分析判别高绩效团队、基于语言迁移理论自动侦测受试的母语、飞行事故中语言障碍对飞行员态势觉察能力的影响等。
(四)机器翻译研究(聚类3)
美国军方对机器翻译研究一直有浓厚的兴趣。早在上个世纪60年代,美国国家自然科学基金、中央情报局和军方各部门每年资助的机器翻译项目就超过了13个,金额超过250万美元。受乔姆斯基的影响,整个1960至1980年代的机器翻译系统都是采用基于规则的方法。研究者的主要工作是描述源语言和目的语言的语法规则、制定转换规则和双语词库。1980年代末,人们逐渐意识到基于规则的方法存在覆盖面有限、系统不经济和维护困难等一系列问题。
1990年代,基于统计的方法开始成为主流,并且发展迅速。2000年马里兰大学的一份报告,指出该校开发的基于统计的机器翻译系统的准确率可以达到92%。2000年以后,随着基于统计的方法不断成熟,人们逐渐意识到语言资源(如语料库、本体等)的稀缺是影响机器翻译系统研发的关键因素。因此,如何快速构建本体,以及如何解决小语种平行语料库稀缺的问题,都开始成为该领域关注的焦点。同时,基于统计和基于规则的方法相结合,也被认为是 未来 提高机器翻译系统质量的正确道路。
(五)形式语法研究(聚类4)
该领域的主要研究目的是让计算机能够理解和处理自然语言。早在上个世纪60年代,乔姆斯基的《句法结构的若干问题》就受到了美国军方的资助。受乔姆斯基的影响,语言的形式化分析成为整个1960至1980年代的基本研究范式。
为了让计算机更好地通过形式化的规则理解各种语言现象,研究者们先后推出了一大批语法理论,如依存语法、上下文无关语法、生成语法、关系语法、上下文有关语法、短语结构语法、关联语法、优先语法、扩充转移网络文法、Nigel语法、LALR(1)语法、词汇-功能语法、功能合一语法、广义短语结构语法、LD/LP语法、HNL语法等。
1980年代,研究者们开始意识到单纯依靠语法规则无法有效解决自然语言理解中的诸多问题,而且基于语法规则的系统存在鲁棒性、经济性、可移植性都比较差的问题。1990年代,基于统计的方法开始成为主流,概率(probability)和统计(statistics)成为绝大多数研究报告的关键词。同时,语料库的作用日益凸显。尤其是经过标注的语料库,既可以用于理论验证,也可以用于知识获取。2000年以后,基于规则和基于统计的方法逐渐融合,集中体现在依托形式语法理论开发的语料库上,如树库、依存树库等。
(六)区域研究(聚类5)
该聚类涉及社会学、人类学、语言学、心理学等诸多学科,涵盖的研究问题也比较广泛,但总的来说都与某一地区或国家相关。其中,最为突出的研究对象是前苏联。在前苏联解体之前,兰德公司和联合出版物研究处会定期翻译和整理前苏联本土的出版物,并编写苏联国情报告,涉及政治、经济、社会、军事、文化、科技等诸多方面。即使在前苏联解体之后,原苏联加盟共和国地区的语言、民族和身份认同问题仍然是一部分研究关注的焦点。
此外,该聚类还包括了菲律宾、越南、西班牙、北非以及美国本土的一些民族和社会问题。
(七)信息提取研究(聚类6)
早期的信息提取研究主要采用基于规则的方法,即依靠人工编制的模板提取特定领域的目标信息。这种方法耗时费力,且可移植性较差。上个世纪80年代末90年代初,随着消息理解会议(Message Understanding Conference)的召开,基于概率统计的方法逐渐成为主流,也使得信息提取技术开始成为自然语言处理研究的重要领域。
1990年代,在消息理解会议的推动下,信息提取技术发展迅速,各个研究机构和大学相继开发出各自的信息提取系统,如BBN公司的PLUM系统,SIR公司的FASTUS系统,米特里公司的A-LEMBIC系统,纽约大学的PROTEUS系统,新墨西哥州立大学的Diderit系统等。
1990年代中后期,信息提取的对象开始由命名实体转向更为复杂的语义关系、事件要素、时间序列等。此外,一些自然语言处理技术,如情感分析、语义角色标注、语义推理等,也都涉及了信息提取的问题。2000年以后,研究重心开始转向互联网,尤其是博客等社交网络的信息提取。同时,研究者更加关注如何在资源相对匮乏的领域实现目标信息的提取。
(八)人机对话研究(聚类7)
早在上个世纪60年代,美国军方就开始关注人机对话技术在培训、情报系统、指挥控制系统等领域的军事应用价值。早期的人机对话技术主要采用基于规则模板和结构化语料库的方法,如BBN公司开 发的Scholar智能师生教学系 统。
1970年代,随着对人类真实交际过程的研究不断深入,研究者们逐渐意识到共享知识在人机交互系统中的重要作用。如何建构共享知识的计算机表征随之成为重要的研究课题。1980年代,该领域开始关注计算机如何能够根据用户的意图提供个性化的应答。这涉及计算机如何借助共享知识对输入进行深层次的语义推理,同时也涉及计算机如何理解和模拟澄清、纠正、修复、回指等真实言语交际中的现象。1990年代,基于统计的方法开始被引入自动问答系统。同时,研究者开始关注自然语言生成的篇章连贯问题。
2000年以后,口语人机对话系统的开发,以及人机对话系统的鲁棒性、可移植性等问题陆续成为该领域关注的焦点。
(九)认知语义研究(聚类10)
与聚类4相似,该聚类的主要目的也是让计算机能够理解和处理自然语言。但该领域的研究重心是语义的形式表征,而不是语法的形式分析。
研究者们关注的是如何使用计算机可处理的物理符号来表征抽象的语义知识。由于语义的复杂性,该领域是一个涉及心理学、认知科学、计算机科学、语言学、哲学等诸多学科的交叉领域。研究者们大量借鉴相关学科的研究成果,提出了一大批语义表征模型,如1960年代的语义网络模型,1970年代的概念依存语法、优选语义学、个人因果律理论、HOS理论、语言记忆系统形式化模型,1980年代的联通理论,1990年代的结构建造框架理论、模糊语义学,2000年以后的ACT-R理论、社会网络分析、双反应理论等。从研究对象来看,该领域关注各种特殊语言现象的概念表征问题,如隐喻、语用、信念、空间、时间、因果关系、花园路径现象、指示代词、名词短语、动词元语义等。
2000年以后,语义表征的对象开始从语言拓展到图像、事件、人类行为、社会行为、组织演变、动态信息系统等,研究的重心也开始从静态的语言理解向动态的系统模拟转变。
(十)信息检索研究(聚类11)
该领域研究以信息检索为主,但也涉及信息的加工、管理和应用。1960年代,信息检索的对象多是结构化的信息,如某种特定的情报信息、地理位置信息、海军人事信息等。1970年代,在国防高级研究计划局的高级命令与控制结构试验平台项目中,信息处理技术开始应用于海军指挥控制系统。
1980年代,信息检索技术开始应用在一些更加高级的复杂系统中,如麻省理工学院的自动问答系统、杰伊科公司的自动摘要系统、优利国防系统公司的PUNDIT自然语言处理系统、南加州大学的Penn系统等。这些系统融合了信息检索、机器翻译、自然语言生成等技术,目的是为了实现决策支持的快速性和准确性。
1990年代,针对多媒体资源的信息检索逐渐成为热点,如视频信息检索、图片信息检索、电视新闻检索、图表检索等。2000年以后,跨语言检索、多文本摘要、图像自动标注、话题发现与追踪等热点研究都涉及信息检索的问题。此外,信息系统的互操作性、语义网、语义搜索引擎等问题,也开始成为研究重点。
三、美国国防语言研究的特点与启示
(一)紧跟学术前沿
美国军事语言研究的10个领域,均展现出了较为清晰的发展脉络,以及与相关学科领域的紧密联系。这体现出了美国军方对学术前沿的长期关注和准确把握。获得军方资助的很多研究,都属于相关学科领域的标志性成果,例如乔姆斯基的“转换生成语法”、威尔克斯的“优选语义学”、BBN公司研发的世界上第一个智能辅助教学系统Scholar、卡耐基梅隆大学研发的世界上第一个基于统计模型的语音识别系统Sphinx等。同时,相关学科领域的最新研究成果,也不断应用于军事领域。例如,近年来兴起的“大数据”、“社会网络”、“认知计算”等研究前沿在2000年以后军方资助的多个领域都有直接体现。此外,美国军方还通过 设立具有前瞻性的大型项目,如TIP-STER文本处 理计划、惊奇语言计划 (SurpriseLanguage Project)、多语言自动记录分类分析和翻译 项 目 (The Multilingual Automatic Docu-mentation Classification,Analysis and Transla-tion,简 称MADCAT)、下一代航空运输系统(Next Generation Air Transportation System,简称NextGen)等,来引导科研走向、汇聚优势科研力量。对某一领域的持续关注和支持,也使得美国军方的技术优势得以保持。以美国军方近半个世纪以来资助的语音研究为例,涉及的语种包括英语、俄语、德语、朝鲜语、泰语、塞尔维亚语、希伯来语、日语、加泰罗尼亚语、意大利语、马来西亚语、阿拉伯语、汉语等,研究对象包括聋子、婴儿、盲人、失语症患者、自闭症患者,甚至动物。围绕该领域长期积累的原始分析数据,已成为确保美军语音识别技术优势的重要保障。
目前,我国高水平语言研究的资助来源主要来自国家社会科学基金和自然科学基金,但其中能够被军方直接应用的研究成果较少。国家社科基金虽然将军事学项目单列,但其中语言类项目的数量也相对有限,且仅资助军队系统的单位和个人。这体现出军队对语言研究重要性的认识还不足,对语言研究前沿的把握还有待加强。我们建议军方加强对语言研究发展脉络和前沿领域的追踪和研判,并加强语言类科研信息的管理与发布,以确保在主要研究领域内形成技术上的前沿优势和积累优势。
(二)军民融合发展
从各项目承担者来看,非军方单位约占76%,主要包括公司、大学和研究所。这些受资助的地方单位大都在相关领域处于领先地位,如麻省理工学院的语音和句法研究、斯坦福大学的自然语言处理研究、耶鲁大学Haskins实验室的语音识别研究、雷声公司BBN子公司的信息检索研究、谷歌公司的机器翻译研究等。美国军方(尤其是国防高级研究计划局)还通过资助各种评测会议,吸引来自美国甚至世界各地的研究机构参与相关研究。这在信息技术领域体现得尤为明显,如消息理解会议(Message Understanding Con-ference)、文本检索会议(Text Retrieval Confer-ence)、文本检测与跟踪会议(Topic Detection andTracking)、NIST(National Institute of Standardsand Technology)机器翻译大会等。同时,美国军方十分注重与地方研究人员的联络与合作。例如,美国空军通讯局(Air Force CommunicationsAgency)一直通过邮件列表的方式与语言学和信息技术领域的专家保持紧密联系。
美国空军的暑期研究基金项目(The United States Air ForceSummer Faculty Research Fellowship Pro-gram),每年暑假都会面向全国选拔和资助顶尖学者参与为期10周左右的空军科研课题。此外,需要指出的是,美国国防科技情报中心本身就是一个促进军民融合的信息枢纽。美国国防部的潜在合作单位,可以通过该平台获取技术研究、发展和评估的相关信息,以寻找科研机会并减少重复研究。
目前,我国地方大学聚集了很多优秀的语言研究资源。例如,在最近一次外国语言文学学科排名中,北京大学、北京外国语大学、上海外国语大学、南京大学、广东外语外贸大学等地方大学均名列前茅。同时,一些公司,如科大讯飞、外语教学与研究出版社等,在语言研究领域也具备一定的技术与资源优势。我们建议军方应进一步加强与地方院校、公司和科研单位的交流与合作。军队各主要部门可以结合自身需求和实际情况,通过设立语言研究基金或者专项课题、邀请知名学者参与重大科研项目等途径,实现军事现实需求与地方优势资源的良好对接。
(三)注重语言与技术结合
在本研究梳理的10个研究方向中,有7个都与自然语言处理研究紧密相关,这体现出美国军方尤其注重语言研究与计算机技术的结合。2008年空军战争学院的一份报告明确提出,解决美军不断变化的语言需求,不仅需要招募(recrui-ting)和培训(training)语言人才,也需要语言技术(technology)。2010年,海军陆战队大学的一份报告指出,机器翻译等自然语言处理技术的发展,将是缓解长期以来美军所面临语言问题的重要途径。
对语言技术的重视,使得美军方资助的语言研究中普遍存在着符号化的研究范式,即用计算机可处理的符号系统来表征语言现象和语言知识。形式化的分析对象,既包括语言自身的语法和语义,也包括语言的认知和神经处理机制,甚至语言的社会应用。新世纪以来,随着基于统计的方法不断进步,语言与技术结合的另一个体现是语料库研究。在语音识别、机器翻译、信息检索等多个领域,研究者们达成的一个共识就是,语言资源的稀缺是阻碍自然语言处理技术提升的关键因素。为解决该问题,美军方不仅设立了惊奇语言计划、多语言自动记录分类分析和翻译、全球自动语言开发(Global Autonomous LanguageExploitation,简称GALE)等涉及语言资源建设的项目,还参与资助宾夕法尼亚大学成立了语言数据联盟 (Linguistic Data Consortium,简称LDC),并呼吁北约成员国之间共享语音数据(South 2000)。
在某种意义上可以说,语言资源已经成为一种重要的战略资源,是“自然语言处理战略目标转移的重要标志”(冯志伟2005)。
自然语言处理技术的发展历程,证明了语言与技术结合是推动语言研究工程应用化的正确途径。军事语言研究者应培养形式化的思维方式,努力用计算机可处理的方式描写和分析各种语言问题。同时,要注重发挥语言本体研究的优势,通过探索和破解自然语言的规律和奥秘,为自然语言处理研究提供新的思路和理论支撑。另外,要注重语言基础资源建设,尤其是大规模标注语料库建设,为自然语言处理研究提供丰富的语言实例和知识来源。
四、结语
语言存在于人类生活的方方面面,军事领域也不例外。凡是涉及语言使用的军事活动,均存在着语言处理或使用的问题。例如美军语言研究的领域就涉及航空对话、轮船目击报告、事故故障报告、作战报告、非正式会议录音、电话录音、邮件列表、团队对话、外文科技文献、士兵演讲等。在某种意义上可以说,对语言文字的处理水平就代表着军队信息化建设的水平。军事语言研究者应善于捕捉军事领域的语言问题,并以提高军队战斗力为核心目标,使语言研究更好地服务于军队语言能力的建设。
作为一个探索性研究,本研究的不足之处在于仅仅使用了国防科技情报中心的公开数据,且未对聚类分析的效果进行深入考量。但总的来说,本研究对10个研究方向的划分和分析具有一定的合理性,所得结论对于军事语言工作者具有一定的借鉴价值。
参考文献:
[1]文秋芳,苏静.军队外语能力及其形成———来自美国《国防语言变革路线图》的启示[J].外语研究,2011,(4).
[2]文秋芳.美国国防部新外语战略评析[J].外语教学与研究,2011,(5).
[3]文秋芳,张天伟.美国国家外语能力建设模式分析[J].外语教学与研究,2013,(6).
[4]王建勤.语言问题安全化与国家安全对策研究[J].语言教学与研究,2011,(6).
- 相关内容推荐
- 国外教育语言学现今的研究应用领域及不足2014-08-25
- 我国对中外外语教育的对比研究2014-09-16
- 店名的语言学分析与用字规范2015-07-22
- 利用认知冲突理论实施应用语言学教学的策略2015-09-24
- 从认知语言学视角看语言翻译的不可译2014-09-09
- 提高少数民族学生汉语教学效果的方法2014-11-10
- 英汉翻译软件在大学生学习中的应用及其问题与建议2014-11-10
- 徐嘉瑞文学翻译的内容、语言及功能2016-01-14
- 上一篇:隐喻与思维认知的相互作用
- 下一篇:应用翻译学的体系及其特点





