
日益增长的数字信息资源对知识基础、文化记忆和经济发展产生了重要影响,其内容组织和服务能力的水平构成了一国综合竞争力的重要组成部分.显然,在当前快速变化的数字环境下,确保数字信息资源的长期保存便成为首要任务,这也得到了我国科学研究领域的高度重视[1].但同时,为了确保长期保存任务的实现,也带来了技术和管理上的双重压力,由此催生出了数字策展 ( Digital Cur-ation) .回顾数据洪流 ( Data Deluge) 带来的挑战,对这些挑战的分析有助于我们厘清从数字保存到数字策展的发展脉络,在此基础上展开对未来研究方向的讨论.
1 数据洪流带来的挑战
在数字环境下,信息更多地被称为数据,信息爆炸( Information Explosion) 也被表达为数据洪流,这些术语都是用来暗示信息或数据的海量性和多样性问题以及所带来的影响.从微观层面上看,可用数据的容量增加不仅造成了管理上的日益困难,而且多种数据格式和交流渠道还加剧了这种情况,从而导致了信息过载 ( Overload) 这一我们最为熟悉的负面影响; 相对地,新的信息需求又在不断增长,人们觉得一刻也离不开信息,存在着信息焦虑( Anxiety) 的心理[2].从宏观层面上看,数据洪流使得数字信息资源的空间结构和时间结构发生了大的变化,空间上资源分布更加扁平化和多样化,时间上不同生命阶段的数据之间的内部关联性大大增强,凸显了数据产生的管理( 物联网) 、数据汇集和交换效率 ( 云计算) 以及数据存储 ( 云存储) .
目前,一个崭新的术语 "大数据"被用来描述上述环境.就实践层面上看,大数据所面临的第一个问题就是长期保存,换言之,就是要如何构建新的基础设施.
Google 从 2004 年就开始推进 Hadoop 和 BigTable 分析数据基础设施的构建; Facebook 也致力开发 Apache Cassandra分布式数据库系统; Apple 则通过收购 Topsy 来拥有 Twit-ter 整个发展历程的所有数据以及访问 Twitter 数据的通道.
科研机构和科技管理机构也在大力推进海量数据库集群的构建,推进数据的交汇与融合,如: 科研机构正逐渐接纳科学的第四范式 ( the Fourth Paradigm) ,即数据密集型科学发现,而几乎在每个实验室里,快速增长的原生数据通过文件、表格和数据库的形式存放在硬盘、数字笔记本、网站、博客和维基中,科研人员对这些数据的管理、策展和归档的工作变得日益繁重,这同时也要求开发针对数据密集型研究的类似成本效益的解决方案[3]; 欧洲图书馆、信息和文献联合会 ( EBLIDA) 在 2010-2013 年战略规划中将海量数据保存作为七大战略挑战之一; 美国国会图书馆积极应对 Twitter 现有全部推文 ( Tweets) 的收集,并已开始对多达 1700 亿条以上的推文进行存档和整理.
从根本而言,长期保存只是为丰富且复杂的数据世界提供了可持续性挖掘相对可行的保障,但先存起来之后再说的大数据,一般都会被遗忘.我们管理不了那些无法进行测量的数据,大数据蕴含的力量更离不开人的创造性( Creativity) 和洞察力 ( Insight)[4].单纯依靠类似 PageR-ank、基于用户使用情况的相关性统计不一定会发现所需的知识和情报.利用拥有 "过滤"功能的信息技术工具,将大数据降至可控的小数据,并提供可视化展示服务,可以使得获取创造性和洞察力变得更为容易一些.但总的来说,寻找不同寻常和意料之外的知识和情报在长期保存的体系架构中很难实现,这需要管理上的变革以及新的决策文化,由此便产生了一个新的术语 "数字策展".
2 数字策展的特征与任务
在图书馆员和博物馆员的词汇表里,数字 ( Digital)和策展 ( Curator/Curation) 这些词已经存在了很多年,专业信息人员现在所从事的很多工作也开始被描述成数字策展."策展"一词本身来源于拉丁语,原本主要用于文化遗产领域,有策划、筛选并展示的意思,早期的定义是艺术展览活动中的构思、组织和管理工作.而实际上,数字策展成为热点只是近些年的事情.
通常在科学文献中,讨论较多的是狭义的数字策展,面对的是科研数据和 e-Science 环境.早在 2003 年,由Lord 和 Macdonald 向联合信息系统委员会 ( Joint Informa-tion Systems Committee,JISC) 提交的一份 "e-Science Cur-ation" 的报告中[5],他们认为数字策展是一个相对较新的领域,术语尚不稳定,并从实用性角度对 3 个关键活动"策展" ( Curation) 、 "存档" ( Archiving) 和 "保存"( Preservation) 给出了定义.策展是指在数据产生之时就对其进行管理和促进利用的活动,这一活动要确保数据符合当前的应用目的,并能被发现和重用; 存档是策展的一种活动,它确保数据合理地被选择和存储,能够被访问,并且随着时间的流逝去维护数据在逻辑上和物理上的完整性,包括安全性和真实性; 而保存是存档的一种活动,它的对象是数据的特定部分.
另外比较有代表性的是英国数字策展中心 ( DigitalCuration Centre,DCC) 所给出的定义,它认为数字策展是指在研究数据的整个生命周期内,对研究数据进行维护、保存并且实现增值的一系列活动[6].Abbott 认为数字策展是对数字数据进行管理和保存以使其能够被长期应用的活动,包括从规划数据产生就开始的数据管理,数字化和文档编制的最佳实践,以及确保这些数据的可用性和适用性以便未来能被发现和重用的所有活动[7].
值得注意的是,这些定义对于 "主动参与"和 "未来使用"进行了反复强调,将策展视作与记录生成者之间的主动的潜在的交互过程.强调 "主动参与"可能是为了与被动参与的管理相区别; 强调 "未来使用"也同样是在说明这一问题,因为 "未来使用"是数字保存具有商业价值的源泉.Yakel 就认为数字策展有 5 个核心的概念和特征[8],包括: ①生命周期或持续性的管理; ②信息记录生成者和数字策展工作者的长期主动参与; ③对信息资源的评估和选择; ④提供和发展存取服务; ⑤确保数字对象在保存过程中的可用性和可获得性.
此外,从 2008 年开始,"策展"一词还作为下一波技术趋势开始在众多的社会技术博客中成为流行词 ( Buzzw-ord) ,其中的部分原因是我们无法消费过多的信息以至于信息过载[9].在网络世界里,数字策展和内容策展 ( Con-tent Curation) 、社会策展 ( Social Curation) 等同,不妨称之为广义的数字策展.简单来讲,针对网上内容的策展,Google 是通过搜索算法来帮助精炼和产生相关的结果,但在面对 Twitter 和 Facebook 这样的社交媒体时,则需要更多人类的技能和洞察力去增值."策展的社会内容" ( Cu-rated Social Content) 强调社交媒体网站中用户生成内容( UGC) 的价值以及为找到最好且最相关内容而进行策展的需求.对于社交媒体来说,策展是一种新的组织和增值的交互架构,用以补充传统的搜索和聚合算法,包括编辑数字图像、网络链接、电影文件等.当然,和狭义的数字策展类似,广义的数字策展同样强调 "主动参与"和"未来使用",围绕着增值展开.
3 数字策展的生命周期模型
数字资源的自身特点决定了其容易受到技术变革的影响.Higgins 认为采用生命周期管理有助于保持数字资源的连续性,能确定和规划所有必需的阶段,并以正确的顺序加以实施,从而确保数字资源的真实性、可靠性、完整性和可用性,并保证投资效益的最大化[10].典型的数字策展生命周期模型由 DCC 提出,具体如图 1 所示.该模型以高度概括的方式展现了一个成功的策展所需的生命周期阶段,它作为一种组织规划工具,广泛适用于各个领域,并容许在不同粒度层次上对策展和保存活动进行扩展.模型中,数据包括了数字对象 ( Digital Objects) 和数据库 ( Databases) .其中,数字对象可分为文本、视频、音频、相关标识符和元数据等简单数字对象,以及由不同数字对象构成的复杂数字对象,例如网站; 数据库主要是指计算机系统中的结构化数据记录集合.数字策展涉及三类活动,分别是全程活动、顺序活动和偶发活动.全程活动包括描述和表征信息 ( Description and Representation In-formation) 、保存规划 ( Preservation Planning) 、社群关注与参与 ( Community Watch and Participation) 、策展和保存( Curate and Preserve) ; 顺序活动包括数据概念化 ( Con-ceptualise) 、生产和接收 ( Create and Receive) 、评价和筛选 ( Appraise and Select) 、采集 ( Ingest) 、保存 ( Preser-vation Action) 、存储 ( Store) 、获取、使用和重用 ( Ac-cess,Use and Reuse) 、转换 ( Transform) ; 而偶发活动包括数据丢弃 ( Dispose) 、重新评价 ( Reappraise) 、迁移( Migrate) .

Athena 研究中心在 2007 年成立了数字策展部门( Digital Curation Unit,DCU) ,提出了解读数字策展相关过程的另一种视角,即维护数字资源的真实可信,针对数字资源开展组织、归档、长期保存和增值应用服务,并应将有关情境的信息资源考虑在内.Constantopoulos 等认为需要针对生命周期模型进行增强性改进 ( 如图 2 所示)[11],主要措施有 3 点:

1) 在全程活动中增加 "知识增强" ( Knowledge En-hancement) 环节,将 "策展和保存" 阶段扩展为 "保存、策展和知识增强".在科学研究和专业实践中,会逐渐产生许多涉及真实世界的实体、情景和事件的新知识,它们会以数字资源的形式表达出来.采用语义网技术,新知识可能以注释、规则和本体等形式进行编码和组织.进一步地,可以采用具备语义推理功能的智能代理来开发和利用新知识.每个新知识关系到一种不同的解释或适用的角度,也代表着将已有资源和先验知识进行解读或结合的新途径.同时,新知识也可能自我演化.
2) 在全程活动中 "描述和表征信息" 应包含权威性的机制环节.领域模型对本领域的概念、属性、关系和规则进行了定义,但是有相当一部分本领域的专家知识是根据相关概念、属性、关系和实例的传统表述得来的.当领域知识的主体部分发生重大改变时,其权威性必然随之改变.于是,必须采取相应措施保证在采集专家知识过程中数字资源的质量,比如: 全面性、特有性、连贯性、一致性和成本效益.因此,扩展的 "描述和表征信息"阶段,要增加主要实体、概念、关系和实例的相关信息.
3) 在顺序活动中增加 "记录和维护用户体验信息"( User Experience) 环节.在 Web 2. 0 下,用户交互频繁,不断涌现出新的用户社群,快速产生和更新大量信息资源,而用户体验信息又可以通过社会标签、注释等 Web2. 0 技术进行呈现.用户体验信息关系到特定情境下内容的演变,因此需要在 "获取和重用"阶段之后新增 "记录和维护用户体验信息"阶段.
总的来看,生命周期模型及其扩展模型能将数字策展涉及的活动纳入进一个统一并兼具扩展性的流程中.值得注意的是,扩展模型中的 "知识增强"环节将保存和策展联系的更加紧密.若将 "信息生命现象"和 "信息价值老化"这二者联系起来考虑的话,信息可简单分为两类: 其一是,信息产生之后其内容就不再发生变化,绝大多数信息都是如此,典型的如专利和论文; 其二是,信息产生之后其内容会不断得到更新,即信息的产生和利用之间没有明显的界限,典型的如维基百科条目、不断完善的新闻专题[12].显然,对于前一类信息,就需要 "知识增强"环节作为负熵的流入,促使信息价值增加,从而在信息价值实现过程中,实现增值的目的.
4 策展与保存的联系与区别
从数据洪流带来的挑战来看,可以明显发现有着强烈的从数字保存到数字策展的变革需求; 而从数字策展的特征和任务以及所实施的生命周期管理来看,保存和策展也有着紧密的联系.因此,有必要厘清两者的联系和区别.
加利福尼亚大学的数字策展中心 ( University of Cali-fornia Curation Center,UC3) 所构建的整个基础设施框架包含了 4 个服务层次共 12 项微服务 ( Micro-services)[13],如表 1 所示.虽然这些微服务分属策展和保存两大类模式,也有着不同的聚焦点,但实际上,它们在全生命周期管理中有着广泛的适用性.

保护层 ( Protection) 中的标 识 ( Identify) 和 存 储( Storage) 服务是整个微服务架构的基础.标识服务是一种可以明确并持续对给定策展内容单元进行区分和引用的手段.存储服务为内容的持续管理提供了一个安全的环境.固定 ( Fixity) 服务是对所管理的内容在 bit 级别上的完整性进行检测的一种手段.而复制 ( Replication) 服务是对内容副本的备份.需要注意的是,保护层中的这 4 个组成部分是在不对内容进行任何理解的情况下去管理内容所处的状态 ( State) .而策展的内容所处的情境 ( Con-text) 则由解释层 ( Interpretation) 去管理.其中,库存( Inventory) 服务要为保护层所管理的内容维护一个全面的、与架构无关的元数据目录; 表征 ( Characterization)服务则要为所管理的内容提供一种可自动检查并提取格式化字节流属性的手段,而这对于进行策展和保存的相关分析、事前规划和及时干预都非常重要.
保护层和解释层通常是在后台的保存模式 ( Preserva-tion Mode) 中运行的,由知识库管理员直接管理.而面向用户的策展模式 ( Curation Mode) 则是由交互层 ( Intero-peration) 和应用层 ( Application) 提供的.应用层为信息生产者和消费者提供服务 ( Service) .其中,采集 ( In-gest) 服务通过手动或自动的工作流接口,将新的内容加入到策展环境中; 索引 ( Index) 和搜索 ( Search) 服务支持基于内容和元数据的搜索、浏览和检索; 转 换( Transformation) 服务为采集标准化、保存迁移、交付衍生产品等将内容转码为所需形式.交互层通过消费者驱动的使用方法来对策展的内容进行增值 ( Value) .其中,通知 ( Notification) 服务将新获取的可用性内容通知给用户社群; 注释 ( Annotation) 服务则要为策展者 ( Curators)和消费者提供一种能描述所管理内容的重要属性的手段.
从上述实践经验上可以看出,数字保存主要是在后台运行,属于一种 "黑箱存档" ( Dark Archive) ,只有少数得到授权的用户可以访问,从而保证真实性和完整性[14];而数字策展则要面对用户,焦点集中在服务和价值上.张智雄等还从两个概念的历史形成方面进行了对比[15],具体如表 2 所示.这一对比结果有意识地放大了数字保存和数字策展之间的区别,但从生命周期模型和具体实践经验上看,数字保存是数字策展的前提和基础,数字策展是数字保存的变革和升华,包含的内容更加宽泛和全面.
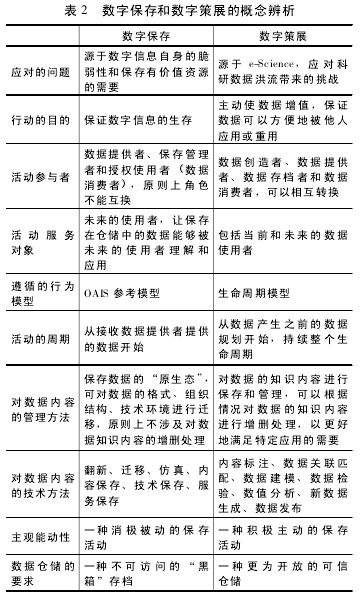
特别的,在两者遵循的行为模型上,开放档案信息系统 ( Open Archival Information System,OAIS) 模型是由美国空间数据系统咨询委员会 ( CCSDS) 制定的标准,并在2003 年最终作为 ISO 的标准 ( ISO 14721: 2003) 予以颁发,目的是维护信息系统中数字信息的长期保存; 而数字策展包含的所有活动都可以被定性为与保存相关,也包括了数字对象在生命周期的所有方面,因此从这个意义上讲,生命周期模型可以看成对 OAIS 模型的有益补充[16].
5 对变革走向的若干思考从数字保存到数字策展的变革不是单纯的理论问题,也不是单一的对策问题,而是面向 "大数据"的知识组织与服务创新的现实问题.从宏观上看,"大数据"环境带来了一场信息社会的革命.科研项目产生了大量的研究数据,需要大学图书馆和计算中心通过建立各种协作数据仓储 ( Collaborative Repositories) 来帮助科研人员保存和使用这些数据,这一过程需要不断提升数据质量,并对数据进行验证、聚合、挖掘和再利用; 而对企业而言,数据是其竞争优势的体现,也是其收入来源之一,尤其是与用户交互产生的数据中蕴含着巨大的商业价值[17].在这种转变中,应当从管理机制和技术路线上加以探索和创新.
1) 管理机制: 数字资源的产生和使用方式.为了达成保存和策展的工作目标,DCC 的生命周期模型有助于搭建起有效的基础设施平台.就一些具体的实践案例来看,国外大学已经将科研数据管理作为图书馆服务的一项内容,以机构仓储和数据门户方式对数据进行组织和利用[18]; 而国内也开始逐步探索,比如: 复旦大学就建立了国内第一个社会科学数据研究中心[19].但总体来看,"主动参与"依然不够,还停留在被动的数字保存阶段.由于策展服务要面向用户,因此在生命周期的早期阶段就应当考虑清楚用户是如何创建、使用以及重用数据.相对于数字保存来说,数字策展需要侧重到对数据交换模式、知识交流方式、用户需求和行为等相关方面的研究.
2) 技术路线: 数字资源长期保存的技术挑战.长期保存数字资源所带来的技术挑战有很多.其中首先要面对的问题就是数据老化,它包括了介质老化、语义老化和文化老化 3 个层面[20].由于软硬件技术的不断进步,备份数据变得简便,介质老化也随之淡化起来.但是和以前手写记录一样,随着数据格式的不断变换,以及用于解释数据语义的知识的不断消亡,数字内容的语义老化会浮现出来,最终形成文化老化.随着文化老化,社群会对老化的这部分数字内容失去兴趣,不再检索相关文档,也不再引用相关数据.针对语义老化带来的问题,图 1 中是通过数据迁移 ( Migrate) 来解决的.目前语义网技术可以用来支撑数据迁移,这就是 "知识增强"要涉及的问题,但是依然存在很多挑战,比如,本体长期变化的模式识别、对本体使用情况的长期观测.
此外,在数字策展生命周期模型中的每一个阶段,知识库管理员都会对数据对象执行某些操作,并且维护这些操作的有关信息.这些信息包含了数据对象和相关的元数据,它们会被提交存档.而当数据对象从存档状态中被检索并交付给数据请求者时,相关的事件和变化必须加以记录.为了完成这一目标,需要探索技术解决方案,并整合入数字策展生命周期的各个阶段.
参考文献
[1] 叶继元 . 图书情报与档案管理学科未来五年重点研究领域与选题[J]. 中国图书馆学报,2012,38 ( 1) : 105-112.
[2] BAWDEN D,ROBINSON L. The dark side of information: o-verload,anxiety and other paradoxes and pathologies[J]. Jour-nal of Information Science,2009,35 ( 2) : 180-191.
[3] BELLl G,HEY T,SZALAY A. Beyond the data deluge [J].Science,2009,323 ( 5919) : 1297-1298.
[4] MCAFEE A,BRYNJOLFSSON E. Big data: the managementrevolution [J]. Harvard Business Review,2012,90 ( 10) : 60.
[5] LORD P,MACDONALD A. E-Science Curation Report,Datacuration for E-Science in the UK: An Audit to Establish re-quirements for future curation and provision [EB / OL]. http: / /jisc. org. uk / media / documents / programmes / preservation / e-sci-encereportfinal. pdf.
[6] Digital Curation Centre ( DCC) . What is Digital Curation?[EB/OL]. [2014-03-21]. http: / /www. dcc. ac. uk/digital-curation / what-digital-curation.
[7] ABBOTT D. What is Digital Curation? [EB/OL]. [2008-04-02]. [2014-03-21]. http: / / www. dcc. ac. uk / resources / brie-fing-papers / introduction-curation / what-digital-curation.
[8] YAKEL E. Digital curation [J]. OCLC Systems & Services,2007,23 ( 4) : 335-340.
[9] LIU S B. Trends in distributed curatorial technology to managedata deluge in a networked world [J]. The European Journal forthe Informatics Professional,2010,11 ( 4) : 18-24.
[10] HIGGINS S. The DCC curation lifecycle model [J]. Interna-tional Journal of Digital Curation,2008,3 ( 1) : 134-140.
[11] CONSTANTOPOULOS P,DALLAS C,et al. DCC&U: an ex-tended digital curation lifecycle model [J]. International Jour-nal of Digital Curation,2009,4 ( 1) : 34-45.
[12] 望俊成 . 信息老化的新认识---信息价值的产生与衰减[J]. 情报学报,2013,32 ( 4) : 354-362.
[13] ABRAMS S,KUNZE J,LOY D. An emergent micro-servicesapproach to digital curation infrastructure [J]. InternationalJournal of Digital Curation,2010,5 ( 1) : 172-186.
[14] HIGGINS S. Digital curation: the emergence of a new discipline[J]. International Journal of Digital Curation,2011,6 ( 2) :78-88.
[15] 张智雄,吴振新,刘建华,等 . Digital Curation 和 DigitalPreservation 之概念辨析 [J]. 现代图书情报技术,2014( 1) : 4-13.
[16] GRACY K F,KAHN M B. Preservation in the digital age[J].Library Resources & Technical Services,2012,56 ( 1) .
[17] MARCHIONINI G. 科研数据管理: 保障数据质量,促进iSchools 新科学研究 [J]. 图书情报知识,2013 ( 4) : 4-9.
[18] 李晓辉 . 图书馆科研数据管理与服务模式探讨 [J]. 中国图书馆学报,2011,37 ( 5) : 46-52.
[19] 殷沈琴,张计龙,张莹,等. 社会科学数据管理服务平台系统选型研究---以复旦大学社会科学数据平台为例 [J].图书情报工作,2013,57 ( 19) : 92-96.
[20] SCHLIEDER C. Digital heritage: Semantic challenges of long-term preservation [J]. Semantic Web, 2010, 1 ( 1 ) :143-147.





