摘要:物联网应用发展迅速,已经与互联网技术相互融合。针对搜索引擎广阔的应用前景以及分析国内外搜索引擎的发展现状,根据搜索引擎系统的工作原理设计一种基于物联网技术的搜索引擎。对搜索引擎进行了相关的研究。一个搜索引擎由搜索器、索引器、检索器和用户接口四个部分组成。搜索器的功能是在互联网中漫游,发现和搜集信息。索引器的功能是理解搜索器所搜索的信息,从中抽取出索引项,用于表示文档以及生成文档库的索引表。检索器的功能是根据用户的查询在索引库中快速检出文档,进行文档与查询的相关度评价,对将要输出的结果进行排序,并实现某种用户相关性反馈机制。用户接口的作用是输入用户查询、显示查询结果、提供用户相关性反馈机制。结合搜索引擎发展现状分析了搜索引擎的系统功能需求,并进行了可行性论证,进而提出了基于java的技术方案,明确采用jsoup、elasticsearch、jfinal等相关开发技术;然后通过网络爬虫抓取数据下载到本地,建立索引;在系统实现环节,重点对需求分析中确定的主要功能模块进行代码编程、修改及优化;最后,设计了若干具体测试用例对系统进行了较全面的测试,验证设计效果。
关键词:物联网;搜索引擎;网络爬虫;索引器;jsoup.
随着信息技术与物联网技术的不断发展和融合,越来越多的产业与行业广泛应用了物联网技术,如工农业、智能家居、快递物流、设备监控等,物联网中包含很多实体,这就意味着海量的实时数据需要传输、存储及有效展示。面对越来越多的传感器及其所产生的数据,只有结合智能的物联网搜索,才能最大限度地实现这类数据的价值。
1 模块设计。
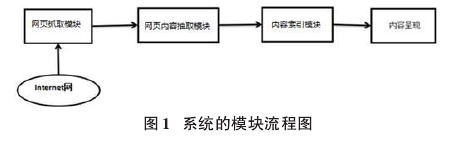
本搜索引擎由四个模块组成,主要包括网页抓取模块,网页内容抽取模块,内容索引模块和内容呈现模块。系统的模块流程图1如下:
1.1 网页抓取模块。
网页抓取模块主要完成对指定站点进行网页的抓取并将所抓取的网页保存到本地数据库。
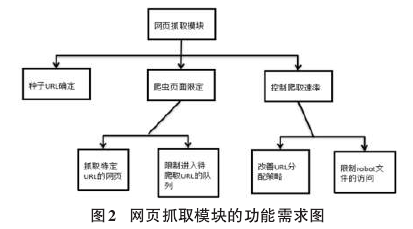
本系统是从凤凰、腾讯、网易、搜狐新闻网上爬取相关的网页,输入凤凰、腾讯、网易、搜狐新闻网的页面的URL作为种子URL.通过分析凤凰、腾讯、网易、搜狐新闻网的网页URL的格式,对网络爬虫抓取和分析网页的行为进行一定的控制,限定应抓取的网页的URL格式以及限定能进入待爬取的URL队列的URL的格式。提高网络爬虫爬取速度可以通过改善URL的分配策略,使网络爬虫的并发线程增多。通过限制对Robot文件的访问,也是提高爬虫爬取网页效率的一个方法。网页抓取模块的功能需求如图2所示:
1.2 网页内容抽取模块。
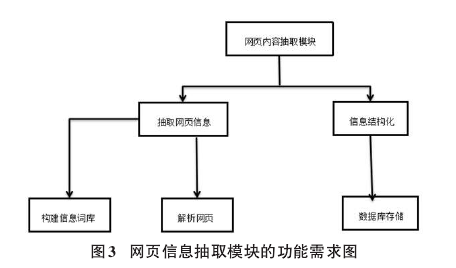
网页内容抽取模块主要负责从本地文件所存储的网页中按照某种抽取规则抽取所需信息,并将所得到的信息按照特定的格式保存到数据库中。
通过对具有代表性的目标页面进行分析,制定信息抽取规则,实现对网页上各种内容的定位,抽取网页文本内容。构建网页信息词库,通过分词器解析抽取出所需网页信息内容,并将其写到指定词库文件中。将提取的网页非结构化信息转化成结构化信息存储到数据库中。
网页内容抽取模块的功能需求如图3所示。
1.3 内容索引模块。
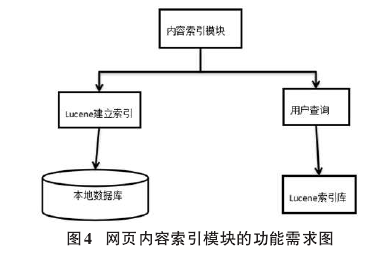
利用Luence索引工具对数据库中结构化信息建立索引文件,然后把创建好的索引文件保存到磁盘中,根据用户输入的查询条件在索引文件中进行查询,最终查询结果按照一定的顺序进行排序返回给用户。
网页内容索引模块的功能需求如图4所示。
1.4 内容呈现模块。
通过jsp技术,以Web的形式展示用户界面,当用户在此界面输入关键词时,根据用户的关键词从数据库中匹配相关网页,把相关网页根据一定的排序规则返回显示在用户界面。