摘 要: 文献检索系统是图书馆建设的重要组成部分。本文首先对武汉6所高校现有的文献检索系统进行比较, 并详细描述传统检索系统的特点。然后对现有检索系统存在的不足, 引出两种智能化检索方式:语义检索和图像检索, 并对这两种方式进行概述。最后探讨了未来图书馆可行的文献检索方式。
关键词: 文献检索; 语义检索; 图像识别;
Abstract: Document retrieval system is an important part of library construction. Firstly, this paper compares the existing literature retrieval systems of six universities in Wuhan, and describes the characteristics of the traditional retrieval system in detail. Secondly, the shortcomings of the existing retrieval system are pointed out, and two intelligent retrieval methods are introduced:semantic retrieval and image retrieval, and the two methods are summarized. Finally, it discusses the feasible literature retrieval methods in future libraries.
Keyword: document retrieval; semantic retrieval; image recognition;
0、 引言
随着信息技术的飞速发展, 网络成为我们工作和生活中不可或缺的一部分, 网络化也对我们图书管理领域产生了巨大的影响。图书馆在经历了第一代、第二代、第三代的变迁后, 文献检索方式也由最原始的卡片检索、关键词检索过渡到现在的智能检索。如何根据图书馆文献检索的特点和使用需要, 建立适用的检索系统, 是目前我国图书馆界普遍关心和探索的问题[1]。
本文对传统检索方式、语义检索方式、图像检索方式进行简要描述。
1、 图书馆常用传统检索模式
从整体情况看, 这些系统尽管在检索操作上各有特点, 但在检索功能的设置和使用的便利性方面进行了许多努力, 具有以下相同的特点。
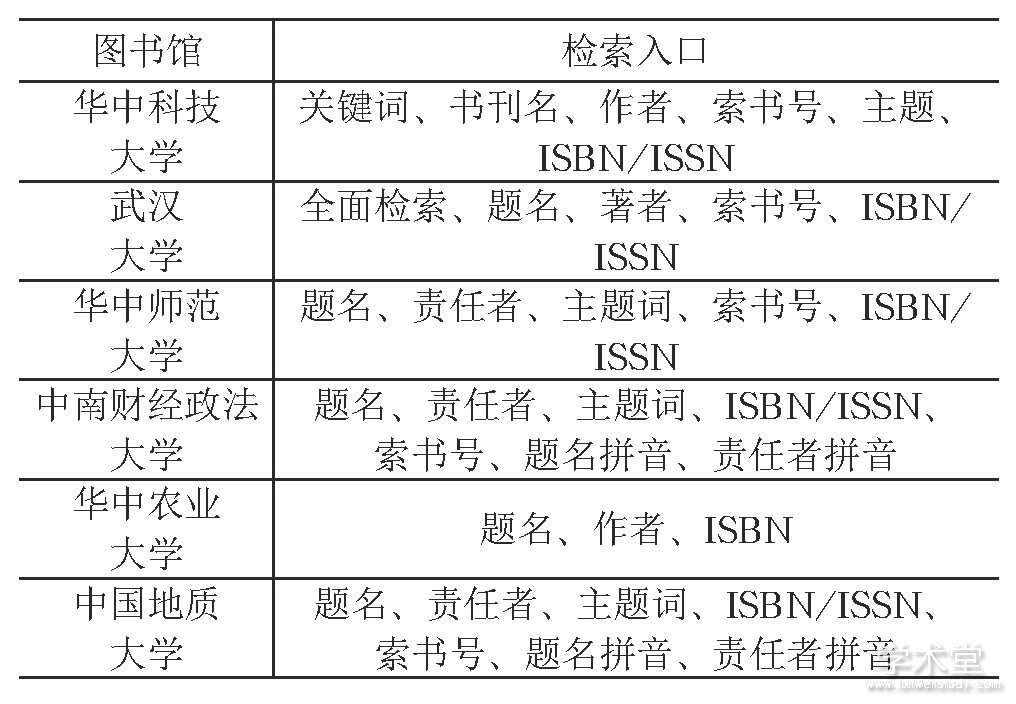
1.1、 提供多功能的检索入口
检索入口的丰富性, 直接关系到系统的检索能力和便利性。多种角度的检索, 方便读者根据自己的需求, 实现个性化检索。从检索入口可以发现, 目前主要的检索字段是题名、责任者、关键词、索书号。武汉大学还提供“全面检索”, 将各种可能的字段检索融合在一起, 实现更加精准的图书检索。

1.2 、提供检索条件
根据图书馆实际情况的不同, 还额外提供了个性化检索条件。以华中科技大学图书馆为例, 除表1设定的检索目录, 还提供检索范围, 如东校区图书馆、主校区图书馆、医学分馆;提供语种选择, 如英语、法语、德语、意大利语等;提供图书入藏时间的范围选择。有了这些多种类的检索条件, 就更加方便读者在众多图书中, 根据自己的需要, 检索到目标书籍。
表1 武汉6所高校检索入口对照
1.3 、界面友好功能
目前针对图书检索, 各个图书馆大体都差不多, 但是为了提高用户使用幸福感, 各个图书馆都不同程度地注意使用友好界面, 并提供各种检索帮助。华中科技大学提供检索历史、保存检索页面记录;武汉大学图书馆提供中文与西文的分类统计、通用命令语言、分类浏览、检索历史、上次检索;中南财经政法大学提供导航栏展示图书分类、文献类型、馆藏地;华中师范大学提供检索结果可按照降序或升序排列。
以武汉6所高校为例, 对目前图书馆的常用检索方式汇总如表1。
2 、基于语义检索模式
针对传统图书检索系统只是基于关键字的检索, 无法进行语义扩展, 存在查全率和查准率不高的问题, 出现了基于语义图书检索。读者只需要做一段描述, 或者是提一个问题, 在可以不依赖关键词匹配的情况下, 检索出想要的书籍[2]。
语义检索需要本体构建、实体生成和结果展示三大组成部分[3]: (1) 本体构建。有学者以着录规范MARC为技术设计书目本体, 典型的本体有MarcOnto、Dublin Core及BibTeX等[4,5,6]。这些本体的优点是可以从不同角度揭示书目特征;缺点是只关注书目自身的描述, 缺乏对作者和书目的描述及各类之间的关系的建立。 (2) 实体生成。书目数据的实体来自图书馆质量良好的结构化数据, 实体生成是根据书目本体生成与书一一对应的描述信息。 (3) 结果展示。对语义检索返回的结果, 以友好页面进行展示。增加图书检索的使用幸福感。
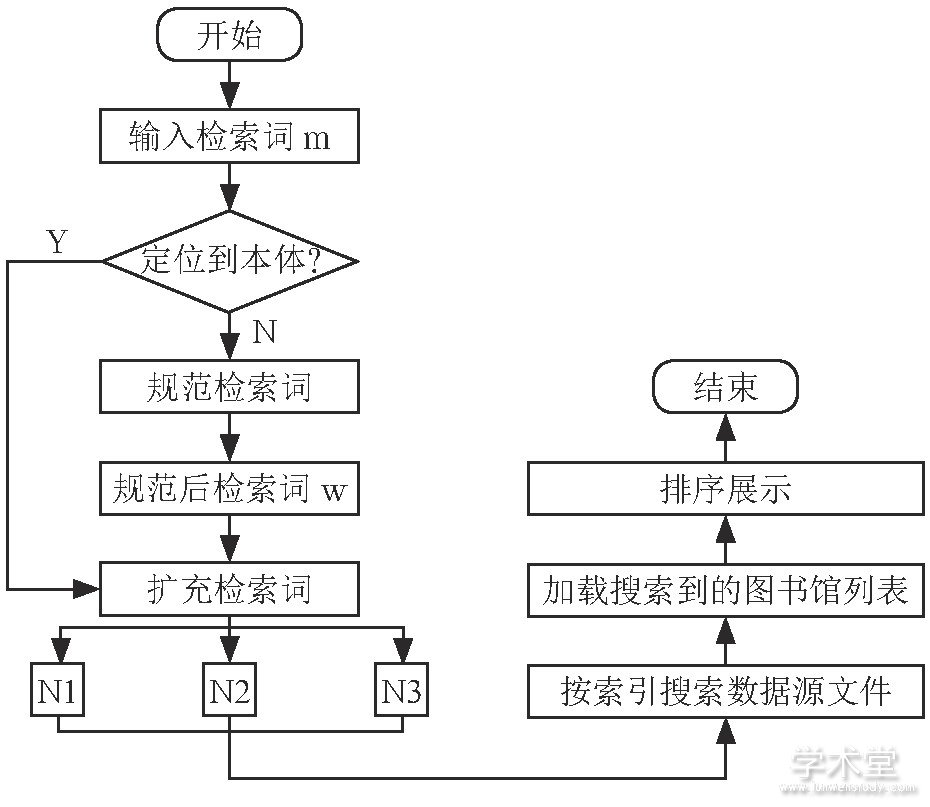
目前语义检索的流程[3]如图1所示。其详细步骤为: (1) 读者通过检索界面输入检索词m; (2) 判断该检索词能够直接定位到本体, 如果能则转到 (4) ; (3) 通过已经建立的本体文件, 对用户输入的检索词进行规范, 得到检索词w; (4) 将传入的词定位到本体文件中, 并进行语义上的扩展, 归类或者关联扩展; (5) 得到扩展后的检索词N1, N2, N3; (6) 通过已经建立的对数据源文件的索引文件, 对扩展后的检索词进行搜索, 得到其路径; (7) 加载搜索到的文件, 将搜索到的个体取出来, 并且按照相似度进行排序; (8) 得到结果。
图1 语义检索流程
3、 基于图像识别检索模式
随着智能手机的普及, 图片获取与阅读已经成为人们消费互联网信息的重要方式。图像识别是通过计算机模拟人类对图片的分类理解, 自动地把图片归为不同的语义类别[7]。目前图像识别在众多领域都有广泛的应用, 比如公安系统的人脸识别、网上购物的物品识别、公路系统的车牌识别等。
图书馆应该顺势为读者提供更加便捷的文献检索方式, 因此提出图像检索。因为图像检索需要对数据集有一定的要求, 因此暂时还没在图书馆推广使用, 但这必将是一个趋势。
文献图像检索系统, 采用B/S三层架构模型, 有效地对生命周期进行管理[8]。
第一层为数据层:数据层主要使用MySQL集群存放图书图片信息数据, 这些数据的获取主要是馆员录入, 网上获取, 读者上传。
第二层为业务逻辑层:主要包括数据交互、内容识图系统模块和上层数据分发模块。
第三层为展示层:将匹配检索出的结果, 展示成原始的HTML页面。
图像识别检索的优点是快捷方便, 尤其是对于年龄较大不方便打字的人群。现在智能手机的普及和拍照水平的提高, 更加方便读者使用图像检索。图像检索的缺点是前期图片集的采集、图片预处理与特征提取, 需要较大的工作量;现有的图像识别算法支持向量机、卷积神经网络、深度学习等, 这些算法对于设备的计算能力有一定的要求。
4 、结论
本文主要从三个方面概述现有的文献检索系统。近几年, 各大高校图书馆纷纷推出移动端文献检索, 这种方式更加便捷。但是移动终端的检索只局限于传统的检索方式, 因此借助智能移动终端结合新技术, 有望实现更加便捷的检索方式。
文献检索是图书馆数字化发展的重要体现, 是图书馆建设的关键环节。虽然在现阶段的应用还存在一定的局限性, 但是图书馆应跟随现代技术的步伐, 不断探讨、不断尝试, 这样才会有新的突破。
参考文献
[1]马张华.我国大型图书馆机检系统检索特点研究[J].中国图书馆学报, 2003 (4) :55-58.
[2]本刊讯.谷歌发布“与书对话”检索引擎, 实现句子层级的图书检索[J].数据分析与知识发现, 2018, 2 (4) :80.
[3]张萍, 罗军, 程正椿, 等.基于本体的图书检索系统的研究[J].广西民族大学学报 (自然科学版) , 2012, 18 (2) :53-56.
[4]白海燕, 乔晓东.基于本体和关联数据的书目组织语义化研究[J].现代图书情报技术, 2010 (9) :18-27.
[5]宋琳琳, 李海涛.大型文献数字化项目图书书目本体的构建研究[J].图书馆建设, 2013 (12) :19-25.
[6]郭振英, 赵文兵, 魏育辉.轻量级书目本体关联数据建设实践[J].现代图书情报技术, 2015 (Z1) :139-143.
[7]闫河, 王鹏, 董莺艳, 等.改进的卷积神经网络图片分类识别方法[J].计算机应用与软件, 2018, 35 (12) :193-198.
[8]谢彦.基于内容的图像识别搜索系统的设计与实现[D].武汉:华中科技大学, 2016.





