第五章 基于路径查询的分类故障排除策略
造成网络调试困难的原因有很多方面:(1)网络规模快速增大。保守估计,1 个普通的数据中心包括 1000 多个交换机,1 个校园网拥有 5000 多个用户,1 个 100G 的链路上有 10000个流。(2)网络更加复杂。网络协议征求意见的目录已经超过 6000 个,路由软件有数百万行的代码,网络芯片上含有上亿个逻辑门。(3)硬件兼容性问题。早期路由器厂家出于对知识产权的保护,没有使用统一的标准进行路由器接口开发。SDN 网络管理员使用相同的命令配置不同路由器,得到不同的结果。(4)安全性问题。攻击者使用先进的技术操纵大量主机的进行网络攻击,造成网络拥塞或者瘫痪。
第三章中提到的来源分析适用于流规则冲突方面的检测,直接使用图论方法进行分析,得到错误原因,但是面对例如规则丢失这类的问题,并没有很好的解决方案。本文提出一种基于路径查询的故障排除方案,结合故障排除算法定位链路故障和扩大故障排除的范围,能够有效检测流规则冲突和规则丢失这两类事件,是对来源回溯方案的重要补充。实验测试在Fat-tree 网络拓扑中,通过丢包、环路、拥塞测试 3 种测试环境结果显示距离错误越近的地方,发生故障的概率越大并通过逆向策略检测故障原因。本章 5.2 节介绍了检测网络中有无故障的分类策略,5.3 节提出本章故障排除策略和具体实施方案,5.4 节设计实验进行验证。
5.1 分类策略
本节先介绍互联网中常见的故障类型,总结常见的故障原因。选取其中最常见的故障原因如规则丢失和规则冲突,然后使用路径查询的分类策略确定是否存在类似的故障,通过统计指定数据流在故障链路上的比例利用故障排除算法定位故障。
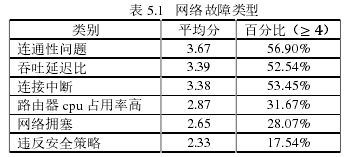
对于北美网络运营商集团常见故障的调查记录[56]总结在表 5.1 中。由网络管理员对所有的故障从 1 到 5 打分,最左边列表示大于 4 的百分比。症状:在六种最常见的症状中,四种类型的故障(吞吐延迟比,连接中断,路由器的 CPU 占用率高,拥塞)通过阳性事件检查效果可能不好。剩下的两种故障(连通性和违反安全策略的情况)需要通过不确定阴性事件进行回溯,以检测控制平面的故障。
网络管理员通过发出路径查询统计数据包从任意交换机 a 进入该网络到交换机 b 离开的所有流量。通过比较这两个数据,操作员可确定数据包在网络中丢失的位置。假设 a 处查询到的数据量为 x,b 处查询到的数据量为 y:
下面再分析一种情况,通过增加查询条件统计从交换机 a 到 b 的流量中包含主机 vm_a到主机 vm_b 的流量的大小,代入公式 5.1 可以得到另外一个结果:m1(vm_a,vm_b)。
如果两个结果相差比较大(如大于 0.5)时,说明在同样网络拥塞的情况下,则认为从vm_a 到 vm_b 的流量在路径 p 上出现故障与网络拥塞有关,相对的结果相差不大,判断故障原因只由于丢包造成的。
考虑到 SDN 网络中依然存在的异质性,网络上数据层的任何改变都很难实现。通过 SDN应用层在策略层面进行编程,使用路径查询的方法间接获得需要的测量值则相对容易。
5.2 分类故障排除策略
在通信网络中,单一的故障可能会导致大量事件传递到网络管理中心。然而多数事件可能来自:(1)故障再次发生(2)多个调用某个故障部件提供的服务(3)设备通过多个事件表示一个故障(4)多个设备同时检测并发出的相同网络故障事件(5)错误传播到其它网络设备使它们产生故障,而且生成另外的事件。典型的网络系统提供充足的必要的信息,以推断存在故障。为了方便解释故障排除方案中可能遇到的难点,下面对故障排除中的常见名词进一步的区分和解释,如错误、症状等专用名词。
错误[36](Error)定义为计算值、观察值或测量值同真值、指定的值或理论上的正确值之间的差异。错误是故障的结果,故障可以导致一个或多个错误,也可能没有导致明显的错误。
错误在外部看起来可能是从指定的服务到服务接收过程中的误差。
症状[36](Symptoms)是故障的外在表现。它们是潜在故障通知,这些通知可以来自管理层中间协议的消息,也可能来自管理系统的网络状态监控程序,还可能是系统对日志文件或显示设备输出的字符流。
精确性[36](Accuracy)是管理员发现故障后,用软件或硬件技术或对故障定位,与实际故障发生位置的偏移量,是对网络可靠性、可用性、安全性对故障定位过程的全面评价。故障排除的精确度计算公式由(A+D)/(A+B+C+D)得出,其中 A+B=100%,C+D=100%.结果得到的值越高。但是在实际的故障排除中,A 类代表系统实际能力的强弱,C 类代表系统的可靠性的强弱,因此更具有参考价值。
5.2.1 故障排除实例
如图 5.1 展示出了一个简单的场景,用来说明流规则冲突的故障排除方法。网络管理员管理的小型网络,其中网络拓扑中包括一台 DNS 服务器、一台 Web 服务器和来自于 Internet互联网的连接。在某些时候,管理员注意到 Web 服务器不再接收来自因特网的任何请求,因此网络管理员怀疑网络中存在某种错误配置,但是根据现有信息无法确定故障,因此属于阴性事件(在服务器上没有 Web 请求事件),也没有明显的起始点进行故障调试。解决方法是手工检查,等待一些阳性事件(如发现请求到达错误的服务器)出现。在图 5.1 中的非常简单的方案中,调试相对容易,但在数据中心或大型企业的网络,可能是一个相当大的挑战。
本文假设网络正常,在不能确定故障是否存在的情况下,如果能够在回溯过程中找到正常状态未发生的原因,则能够从侧面确认网络中存在故障。
5.2.2 故障排除框架
由图 5.2 所示,由路径查询发现网络出现的故障,或者网络管理员怀疑网络出现的故障,需要故障检测算法排除故障原因,定位故障发生的位置,完成故障测试过程。本节使用图 5.2所示的故障排除框架,根据故障发生后网络管理员采取措施的时间顺序,将故障排除的过程分为三个步骤:
(1)故障发现。故障发现主要使用路径查询语言进行数据包捕获后统计分析,在指定的查询位置捕获满足查询条件的数据包,将捕获的数据包交给上层应用进行故障定位或者测试故障原因。因为查询的满足条件决定于运行时系统维护的数据包状态信息,所以故障发现过程既不需要对数据包进行带外的二进制封装,也不需要手动修改交换机的配置文件。
(2)故障定位(也称为故障隔离,告警/事件相关性研究)。通过故障排除算法,对查询到的数据包信息进行统计分析,计算故障链路的权重。在故障定位算法的基础上,基于 Booleantomograph 问题[57]的解决方法,返回的关于最可能发生故障位置的假设,该启发式算法只能尽可能合理地解释观察到的症状,并且相关研究表明这类故障定位问题是 NP-hard[58]问题。
(3)故障测试。一方面鉴于许多可能的假设如规则丢失或者规则冲突,通过逆向策略或者其它测试方法进行数据包回溯,记录测试中止或者数据包被交换机直接丢弃的位置,交由网络管理员进一步分析故障原因。另一方面,在网络管理员尝试对故障修复以后,需要进一步测试故障是否还存在,直到找到真实的故障原因并完成故障修复。
5.2.3 故障排除算法
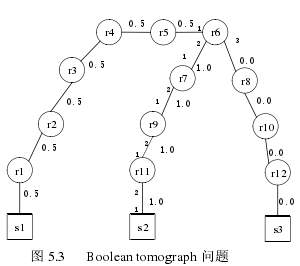
为了判断网络中最可能发生故障的位置,说明解决这个问题的方法,图 5.3 显示的网络


 5.3 故障排除实验验证
5.3 故障排除实验验证
分类故障排除策略的实验基于 Fat-tree[59]三层网络拓扑,通过编写查询策略得到网络中源主机到目的主机流量统计,与所有链路上的流量进行比较分析发现网络故障,然后求出各分段链路权重,得到最可能发生故障的位置。实验中的 Fat-tree 拓扑结构使用 k-端口交换机最多可支持至k3?4 的主机。这种拓扑结构包括 k 个 Pod,拓扑中有(k? 2 )2核心交换机,每个核心交换机连接到一个聚合交换机,每个聚合交换机连接到所有 k/2 边缘交换机,每个边缘交换机连接到 k/2 的主机。例如参数 k=4 的 Fat-tree 物理拓扑,核心层 4 台、聚集层 8 台、边缘层 8 台共有 20 台交换机,网络中包含 16 台主机,可以分成 4 个 Pod 群。
5.3.1 实验方案
实验方案分为丢包、环路、拥塞测试 3 种,分别在 Mininet 网络集成测试环境中对 Fat-tree拓扑进行丢包测试,分别对下面两种对象进行测试。当 k=4、8、10、12、14、16、18、20时每个参数分别进行 20 次求平均值。需要测试的对象:
(1)验证故障发现的正确性
丢包测试方案中分别介绍需要使用的查询语句:
(2)路径查询的效率
使用路径查询语言,需要将查询语句翻译成交换机可以识别的流表项,具体来说,这个过程是由运行时系统动态地将用户编写的正则表达式转换成 DFA[50](Deterministic FiniteAutomaton,确定性有限自动机),通过执行状态的转换、重写、抓取来完成对数据包的操作。
显然,每次路径查询效率同使用的状态的个数应该呈现对应的关系。因为端到端的状态转移在参数 k 确定的条件下,状态个数也是确定的,结果更有参考价值,所以选择测试方案中的丢包测试中使用的状态个数进行记录,分析结果。
5.3.2 实验环境
软件环境:VMware workstation pro 12.0、Ubuntu 14.04.硬件环境:1.90GHzAMD Radeon、6G 内存、镜像 pyretic-0.4.1.实验使用的是 Pyretic 系统,启动 POX 控制器,在 Mininet 命令行中执行 Fat-tree 的拓扑建立脚本,创建好网络拓扑结构。执行脚本命令进行故障仿真,随机选择现两个主机,一个作为服务器,另外一个作为客户端进行测试。
5.3.3 测试和结果
通过编程测试网络性能,例如对两台主机之间的高丢包率进行测试,统计通过指定交换机转发的每个流的数据包数量,找出数据包在传输途中被丢弃的位置。这种调试方法适用于Fat-tree 对称的拓扑结构,因为网络中存在有大量的共享路径路由的流量。
如图 5.5 所示,该实验在 Fat-tree 网络成功完成自动化拥塞测试后,实验结果保存在指定的文件中。通过调整参数可以完成所有测试过程,使用的参数 k 指 Pod 个数,参数 fout 指每个 Pod 中主机个数,参数 s 指网络中交换机个数,其他参数则是用于运行时环境支持的对程序的优化,如参数 c 指运行时系统支持对状态的缓存等。通过扩展程序包 fnss 创建参数为 k的 Fat-tree 拓扑结构,编写 Fat-tree 拓扑结构创建脚本。一种方法是通过 Python 编程语言脚本创建 Mininet 网络测试脚本,对设备链路间的带宽、延迟、丢包率等(如:bw=10, delay='5ms',loss=0, max_queue_size=1000, use_htb=True)进行设置对设备转发起限制作用,另个一种方法则是通过 iPerf 工具来进行测试主机间的性能。
通过分析分类策略的运行时间可以发现丢包测试中运行时间随着 k 值的增加而增大,在k 不在于 20 的范围内呈现大致线性正相关。环路测试过程则需要网络资源比较平均,没有呈现出类似的规律性,但是用时比较平均,由于由于每次测试时占用系统资源都比较多,所以用的时间也是最多的。在拥塞测试过程中,受限于系统内存的大小,实验只能测试出参数 k不大于 10 的结果,从目前的情况只可以看出有限的范围内呈现出同丢包测试相似的规律,仅仅对程序进行优化并不能完成全部测试,因此如果完成全部测试,还需要进一步对运行时系统进行优化。
随着参数 k 值不断增大,可以从图 5.7 看出随着参数 k 值的运行时系统编译正则表达式需要的状态的个数也在增大,总体来看,随着 k 的增大,网络中的交换机的数量的增多,完成对网络中所有交换机进行端到端的丢包测试需要的状态个数当然也会变大,从图中可以看到状态个数变化与 k 值呈线性正相关的关系。
故障定位过程包括三个步骤:(1)找出故障路径(2)计算链路权重,每条链路在故障路径占全部路径的比例(3)权重分析。如图 5.8 所示,粗线表示按照查询结果显示的 h1 到 h5的数据包路径,虚线表示实际用于测试的故障链路。为方便说明,仅考虑采用单路径转发的路由方式,每次测试得到一条从 h1 到 h5 路径上的流量。出现故障的路径用粗线表示,并标记为 R,经过其他 3 个核心交换机的路径标记为 G,根据故障排除算法计算权重后的结果如图 5.8 所示,相等权重下,距离源主机越近,链路发生故障的可能性越大。发生故障被正确排除的概率是 50.0%,未发生故障被错误排除的概率是 100%,根据精确度的定义,因此故障定位的精确度是 75.0%.这种现象可能的原因是越靠近源主机,则链路越靠近错误地点,因此根据经验在网络中发现故障后也是距离错误越近的地方,发生故障的概率越大。
通过对故障定位后,下面说明故障原因的查找方法。假设图 5.8 存在的故障是链路 fd 中断,导致主机 h1 到上 h5 通信中断,以此为例介绍故障排除策略的测试过程。主机 h1 到 h5之间存在四条路径,为了方便说明故障排除问题,假设经过核心交换机 c、f 的两条路径:
a->b->c->d->e 和 a->b->f->d->e,网络未出现故障时数据包的路径是 a->b->f->d->e,出现故障后控制器切换到另外一条路径 a->b->c->d->e.
将回溯结果与未发生故障时进行对比,根据经验可知,使用逆向转发技术得到的结果是e->d->c;f->b 时,这是由于数据包到达交换机 c 后,逆向策略在链路 bc 上没有匹配到转发规则,但是发现链路 bf 上有匹配的转发规则,所以回溯路径呈现两段。显然故障原因是流规则冲突导致的,即 fd 链路断开后,网络管理员设置交换机 b 的流表更新时,误将 b->c->d 的流表规则的优先级低于 b->f->d 的优先级,导致数据包在错误路径上进行转发。当回溯结果是e->d->c->b->丢弃时,可能的故障原因是由于网络时延的问题,交换机 c、d、e 的流规则已经生效,但是交换机 b 更新后的流规则的还未生效,导致回溯数据包在交换机 b 上被丢弃,需要隔一段时间再次进行回溯才能确定这种流规则丢失情况。
5.4 本章小结
本章的故障排除的范围包括阳性事件中的流规则冲突事件,也包括阴性事件中的流规则丢失事件。结合用户体验和 SDN 特性的方案需要软件代理,通过收集器重构出故障路径,然后利用故障排除算法得到故障位置。这种方法的不足是增加交换机流表队列中的数据包处理时间和额外的计算资源。如果仅从错误入手定位故障,在错误不明显的情况下是难以实现的,本章通过基于路径查询的分类策略,将网络中的数据流按查询条件捕获分析以便于发现可能存在的网络故障,提出一种基于路径查询的故障排除算法得出网络中最有可能发生故障的位置,实验结果证明该方案是有效的。通过对故障排除实验结果分析得出网络中发现故障后,根据距离源节点越近,发生故障的可能性越大的结论成功定位故障位置并且验证了故障排除策略的测试过程。