本篇论文目录导航:
【题目】国内互联网完全问题探究
【第一章】计算机网络安全防范探析绪论
【第二章】以太网及TCP/IP协议介绍
【第三章】网络流量分析系统设计
【第四章】网络安全系统仿真测试与结果分析
【总结/参考文献】计算机网络安全防护技术研究总结与参考文献
第三章 流量分析系统设计
随着全球信息化建设的不断加快,网络安全也随之变的越发重要。网络安全从其本质上来讲就是网络上的信息安全。从广义来说,凡是涉及到网络上信息的保密性、完整性、可用性、真实性和可控性的相关技术和理论都是网络安全的研究领域。
3.1 网络安全防护与流量分析系统的关联性
现有网络防护设备通过系统本身实现对 OSI 全层次的数据处理,包括数据接入、识别、分类以及 data 字段的数据分析,由此极度依赖、消耗硬件资源。而流量分析系统是对现有网络防护体系进行物理上的分离,数据分流设备实现数据 1 到 4 层的数据处理、ip 分片重组、乱序重排等基础功能,服务器实现数据包数据层面的分析与处理。由此,服务器资源将全部释放用于数据的深度处理,从而实现网络安全的整体防护。
3.2 网络流量分析系统部署
众所周知,网络攻击[11]的主要类型有 DoS 攻击、缓冲区溢出攻击、漏洞攻击、欺骗攻击等。总结其攻击方式,均是通过人为研究网络相关协议特性,使网络设备资源耗尽、瘫痪或被欺骗,以此达到攻击、占用网络设备的目的。而网络安全防护通常采用的是防火墙策略,防火墙的作用是通过允许、拒绝和重定向经过防火墙的数据流,防止不希望的、未经授权的通信进出被保护的内部网络,并对进、出内部网络的服务和访问进行审计和控制,本身具有较强的抗攻击能力,并且只有授权的管理员方可对防火墙进行管理,通过边界控制来强化内部网络的安全。但防火墙的本质是通过对已知攻击的了解,做好“防患于未然”,而对未知攻击的防御性,就显得捉襟见肘。
3.2.1 系统网络架构
本文以传统防火墙网络架构为基础,在此基础上添加网络添加流量分析平台,以此与传统防火墙[12]形成二级联动,在防范网络攻击的同时,能够以极快的速度响应新的网络威胁。
网络拓扑如下图 3.1 所示:
如上图 3.1 所示,网路流量通过外网 route_A 到达数据分流设备,数据分流设备将其流量复制一份,经五元组(源 IP,目的 IP,源端口,目的端口,应用协议)ACL[13]过滤,然后通过防火墙进入内网;另复制一份流量按照五元组 ACL 规则对流量进行区分输出至数据分析服务器,数据分析服务器对获取的数据进行人工或已设定条件的程序分析,对数据分流设备生成新的 ACL 规则,以过滤通往防火墙的网络流量,防止内网遭受攻击。
3.2.2 数据分流设备定位
在传统网络中,防火墙对 OSI 的 1~7 层实行全覆盖防御,因此防火墙对未知的应用层攻击无法回应,其次,防火墙的性能指标无法满足日益增长的网络带宽及小字节数据包的网络冲击。OSI 七层模型结构及功能如下表 3.1 所示数据分流设备工作在 OSI 的 4 层结构,通过对数据数据链路层、网络层、传输层的特征值过滤,将攻击流量丢弃。而根据硬件配置的不同,分流设备最高可以提供单端口 100G,总计带宽超过 1T 的数据处理能力。
3.3 数据分流设备功能模块设计
分流设备遵守系统模块化设计原则,按照功能、系统对设备模块进行划分。计算机网络数据通过两级硬件交换实现线速的二三层交换。一级交换在线路接口板的各端口之间;二级交换则在各个线路接口板之间,通过控制交换板来实现数据交换。
3.3.1 系统功能模块
基于五元组的分流设备功能模块如下图 3.2 所示:
分流设备按功能划分,主要包括控制模块、交换模块、包处理及接口模块和电源模块。
控制模块:控制模块由主处理器和一些外部功能芯片组成,实现系统对各种控制应用的处理,比如 telnet,fclp 等? 交换模块:交换模块具有多路高速的双向串行接口,可完成线路接口板之间的线速数据交换。
包处理及接口模块:可以提供一个或多个物理端口,不同的线路接口板可以实现不同速率、不同类型业务的接入。
电源模块:电源模块采用 220V 交流供电或-48V 直流供电,为系统内其他部分提供所需的电源。
数据分流设备通过电源模块对整个设备进行供电,并采用电源的 1+1 冗余备份,保证电力供应。计算机网络数据流量通过接口模块将数据包送入设备进行处理,数据包在此完成物理层及数据链路层检测,包括以太网数据包最小字节检测、jabber 帧检测、接口缓存区溢出检测、线路信号检测等。当网络数据包通过接口模块的预处理后,进入包处理模块进行 3 层及 3 层往上的数据处理,对数据包进行 IP 识别、端口识别,从而进行应用层识别。然后,数据将进入交换模块进行基于硬件的快速转发,当设备判定数据从本板输出时,数据通过一级交换模块直接转发出去,当设备判定数据从跨板输出时,数据将通过二级交换模块转发数据。数据分流设备通过控制模块对本设备主控制器及其他功能芯片进行控制,以此实现对设备的管理操作,例如 telnet、snmp、sflow 等等。
3.3.2 系统工作流程
数据分流系统利用 ACL 规则实现入口的流量过滤,利用链路聚合逻辑端口作为输出端口,通过 redirect、permit、deny 命令分别实现数据流量的重定向、白名单、黑名单过滤。数据分流系统的工作流程如下图 3.3 所示:
网络流量从输入端口进入分流设备,通过 ACL 规则判定是否匹配,若匹配 deny 规则或未匹配规则,则数据直接丢弃;若匹配 redirect 或者 permit 规则则进入下一流程查找输出端口,当查到输出端口时,则通过输出端口输出,若未查到输出端口,则丢弃该数据。
3.4 数据分流设备分流算法设计
基于以太网的流量分析系统核心即是数据分流算法,由本文第二章对 TCP/IP 协议簇的介绍可知,基于 TCP/IP 的以太网络是以层次化模型结构来对数据进行处理的,在传统网络设备当中,交换机基于二层的 mac 地址交换,路由器基于三层的 IP 路由,而数据分流设备分流算法,是基于五元组的 hash 分流算法,本章将详细阐述设计思路
3.4.1 传统网络设备数据转发算法分析
传统二层交换机[14],其进行转发算法的依据就是以太网帧的二层信息。交换机接收到一个以太网帧后,然后根据该帧的目的 MAC,把报文从正确的端口转发出去。
二层交换机算法决定了对于交换机所接收到数据帧的处理方式。当交换机收到一单播帧时,过滤/转发逻辑部分查找交换机内部的一张由两元组(MAC 地址,端口号)组成的表格--MAC 地址表,如果该数据帧的目的地址在 MAC 地址表内,而且在 MAC 地址表内和该数据帧的目的地址相匹配的端口号不同于本交换机接收到该数据帧的端口的端口号,则将该数据帧从 MAC 地址表内和该数据帧的目的地址相匹配的端口号所指示的端口发出;如果该数据帧的目的地址在 MAC 地址表内,但是在 MAC 地址表内和该数据帧的目的地址相匹配的端口号就是本交换机接收到该数据帧的端口的端口号,则丢弃该数据帧;如果该数据帧的目的地址不在 MAC 地址表内,则将此数据帧从除了接收到该帧的端口之外的所有端口发出。
当交换机收到一广播帧时,过滤/转发逻辑直接将此数据帧从除了接收到该帧的端口之外的所有端口发出。
在一般路由器[15]中,其转发算法的依据是三层 IP.当收到一份数据报并进行发送时,它都要对该表搜索一次。当数据报来自某个网络接口时, I P 首先检查目的 I P 地址是否为本机的 I P 地址之一或者 I P 广播地址。如果确实是这样,数据报就被送到由 I P 首部协议字段所指定的协议模块进行处理。搜索路由表,寻找能与目的 I P 地址完全匹配的表目(网络号和主机号都要匹配)。如果找到,则把报文发送给该表目指定的下一站路由器或直接连接的网络接口;搜索路由表,寻找能与目的网络号相匹配的表目。如果找到,则把报文发送给该表目指定的下一站路由器或直接连接的网络接口。目的网络上的所有主机都可以通过这个表目来处置;搜索路由表,寻找标为“默认(d e f a u l t)”的表目。如果找到,则把报文发送给该表目指定的下一站路由器。如果上面这些步骤都没有成功,那么该数据报就不能被传送。如果不能传送的数据报来自本机,那么一般会向生成数据报的应用程序返回一个“主机不可达”或“网络不可达”的错误。
3.4.2 传统网络设备分流算法的不足之处
在传统网络设备进行流量转发的过程中,其往往是基于一个元素的转发,例如二层交换机是基于目的 mac 地址的数据转发,只有在 mac 地址表中寻到 mac 地址与输出端口的映射关系,则数据包直接从该输出端口发送出去,又例如三层路由器则是基于目的 IP 地址的数据转发,其根据路由表来寻找 IP 地址与输出端口的映射关系,以此进行数据转发,当然,路由器还能进行轮撒转发,其是在两条可行的路由路径上进行数据包的逐一分发。
而由此产生一个问题,所有的数据分析都将在后端分析服务器上进行,而服务器的数据分析是基于软件的,软件分析将消耗极大的服务器资源,当网络攻击产生时,大规模的流量将使分析服务器存在“崩溃”的风险。
3.4.3 数据分流设备 hash 分流算法设计
出于对后端分析系统的考虑,在数据分流设备对设备进行精确的四元组(源 IP、目的 IP、源端口、目的端口)分流,以此按高层应用来区分数据流量,人为控制流量成分,保障后端分析服务器在性能范围内正常分析流量。
Hash 算法[16],即哈希算法,就是把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,而不可能从散列值来唯一的确定输入值。
若结构中存在和关键字 K 相等的记录,则必定在 f(K)的存储位置上。由此,不需比较便可直接取得所查记录。称这个对应关系 f 为散列函数(Hash function),按这个思想建立的表为散列表。对不同的关键字可能得到同一散列地址,
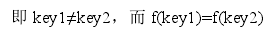
这种现象称冲突。具有相同函数值的关键字对该散列函数来说称做同义词。综上所述,根据散列函数 H(key)和处理冲突的方法将一组关键字映象到一个有限的连续的地址集(区间)上,并以关键字在地址集中的“象” 作为记录在表中的存储位置,这种表便称为散列表,这一映象过程称为散列造表或散列,所得的存储位置称散列地址。
哈希值的随机性是基于流的抽样技术的关键,文献[17][18]分析了 5 种基于 IP 流字段的哈希算法,而使用哈希函数计算哈希值这一方法,哈希函数的选择是保证哈希值随机性和算法高效性的关键因素。文献[19]从理论上证明了位移运算能够提高 hash 值的随机性,提出了基于位移运算的 hash 算法在执行效率和 hash 值的均匀性方面具有良好特性,而数据分流设备 hash算法即是基于位移运算的 hash 算法。
本 hash 算法的设计思路主要是通过 key1 值与 key1 值位偏移的相与,得到一个值 key2,然后通过 key2 的相与并在低位取值,得到我们所需要的 hash 值。具体的实现方式见 3.3.4 节。
3.4.4 数据分流设备 hash 算法实现
数据分流设备 hash 算法的实现主要分为 3 类,第一类是基于源 ip 或者目的 ip 的,第二类是基于源 ip 和目的 ip 的,第三类是基于源 ip、目的 ip、源端口、目的端口的,详情如下:


3.5 本章小结
本章首先阐述了基于以太网的流量分析系统的网络拓扑图,指出数据分流设备在网络中的位置与部署情况。
其次详细介绍了流量分析系统的主设备--数据分流设备的功能模块设计以及其工作过程中的流程切换。
最后介绍了数据分流设备分流算法设计,通过 hash 算法来确认数据的唯一性及随机性,保证数据同源同宿的同时,均匀从端口输出。





