
一、引言
经济的长期增长和短期波动是宏观经济学研究的两大主题,前者归结为宏观经济增长理论,后者归结为经济周期理论。经济增长通常是在经济波动过程中所实现的增长。经济周期波动是经济波动的最主要表现形式,这也是经济运行中的普遍存在的现象。经济周期也称为商业周期,是各种社会经济活动的一种综合表现,呈现出经济随时间变化而扩张与收缩的交替变动以及各经济变量在波动过程中的一种统计规律性。由于综合经济活动总是表现出周期性的波动特征,使得对经济周期的研究成为宏观经济学研究的主要焦点。当经济处于繁荣阶段,失业率降低,财富可以得到更有效的分配;反之,经济处于衰退期间,经济增长乏力,产出持续减少,失业率提高。经济周期这种典型特征和经济衰退导致的严重后果,使得经济学家试图寻找经济所处不同阶段的根源以及如何采取有效措施避免衰退的发生。大体上来说,经济学家关心以下两个问题:导致经济周期的原因是什么?政策制定者对经济的周期性波动时如何反应?
然而,对这两个问题的回答一直饱受争议,争议主要来自新古典主义和新凯恩斯主义这两大宏观经济学学派。新古典主义声称自由竞争的市场自有其内在的机制,价格、工资是可以灵活调整的,货币作为名义变量只能影响到价格这样的名义变量,而对产量、就业等实际变量没有影响,即货币是非中性的,供需可以自动平衡,市场能够自发调整到理想的均衡状态,政府无需干预经济,让经济在自由调整过程中长期趋于稳定发展。
新古典主义试图用微观经济学的理论来论证宏观经济问题,从微观经济学的角度看,个人、企业的工资、价格是变动的,坚信市场工资和价格可以自发调节,从而调节需求,直至市场完全出清,自由竞争是供需双方趋于平衡的法宝,市场最终会达到理想状态,从而使得整个社会福利最大化。新凯恩斯主义宣称,在资源未充分利用以及存在就业空间的条件下,可以进行适当的需求调节,也就是说,经济萧条应当酌情采取刺激政策以扩大需求。新凯恩斯主义也考虑到经济的自动调节机制以及理性预期,当有外部冲击时,必须采用经济政策避免冲击带来的不利影响,使总需求保持在充分就业的水平,经济不能避免失业与经济周期,政府进行干预是必需的也是有效的。
自从西方国家开始工业化以来,国家经济就开始明显出现扩张和衰退现象,一百多年来,经济学家就一直致力于研究经济的周期波动特征,经济学家也基本认同经济中存在不同阶段由上升和下降所构成的重复发生的周期性波动,经济周期定期和经济拐点识别也一直是众多经济学者们研究的热点问题。但是对于发展中的中国来说,由于工业化起步较晚,直到 20 世纪 80 年代中期,才开始展开对经济周期的分析,并在 90 年代后期受到经济学家和政府部门的高度重视。
一个国家需要对经济所处的不同阶段进行宏观调控,调控成功与否很大程度上依赖于对经济波动形式的判断。政府经济决策部门希望经济能够长期沿着均衡增长路径发展,因而面对经济出现过热或者过冷的情形,需要采取一种适当的逆周期措施进行调节,以免经济出现大的波动,进而避免或减少各种冲击下经济波动对实体经济造成的不利影响。鉴于此,对经济周期进行定期以及确定经济周期拐点以反映经济周期波动特征具有重要的理论意义和实践价值。经济周期定期的首要内容就是确定景气波动的转折点即峰、谷日期,据此才能将经济周期分为扩张和收缩交替变动的两个不同阶段,进而分析经济周期波动的特征。鉴于经济拐点判别的重要性和复杂性,各个国家都普遍非常重视对经济周期基准周期的确定工作。根据某些代表经济活动总量水平的指标或指数的转折点定义经济周期,是一些国际着名研究机构或组织的核心工作。
美国国家经济研究局(NBER)是美国影响广泛的私立非盈利研究组织,由一批声名显赫的经济学家于 1920 年成立并开创了经济周期的研究。NBER 构建并定期更新经济周期年表,详细记录美国以及一些其他国家的经济周期历史,另外该机构成员还承担许多与经济周期有关的课题研究,其中一个具有里程碑意义的研究就是由 Burns & Mitchell(1946)所撰写的着作 《测度经济周期》,该着作首次记录并分析了有关经济周期的典型特征以及实证情况。对于经济周期的研究,需要强调以下五个关键点:
1. 总体经济波动
宽泛的说,经济周期反映的是总体经济的波动特征,而非简单考察单个经济指标 (比如 GDP) 的波动,当然单个指标也许可以反映整体经济情况,但考虑其他更多经济指标的波动对宏观经济政策的制定也是非常重要的,比如失业率、金融市场中的指标等。
2. 扩张和收缩
图 1 描绘了一个典型的经济周期示意图,总体经济呈现下滑的时间段内意味着经济收缩或衰退,衰退如果很严重就意味着经济萧条,当经济达到衰退的最低点波谷(Trough)以后,经济开始逐渐恢复,在经济呈现上升的一段时间内经济处于扩张或者繁荣,直到达到波峰(Peak),之后经济又开始衰退。整个历史过程中,经济由波峰到下一波峰,或者由波谷到下一个波峰就代表一个经济周期。图 1 表明,经济周期纯粹是对经济长期正常增长路径的暂时偏移。
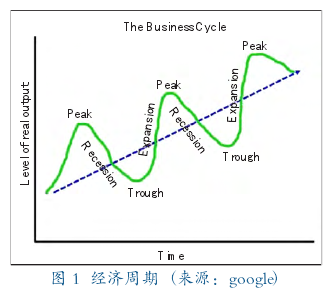
经济周期中的波峰和波谷统称为经济拐点,由于总体经济波动一般不能简单通过单一经济指标的波动特征来度量,因而没有简单的公式可以算出什么时间经济会达到波峰或波谷,在美国,NBER 经济周期委员会的成员会定期达成共识经济拐点的发生时间,该机构对经济拐点的判断具有巨大的影响力,从 1929 年开始一直以来是美国商业经济研究和经济政策制定者的重要参考。
3. 经济的协同变动
经济周期的发生不仅局限少数几个部门或者经济指标,事实上,在同一时间段内许多经济活动都会经历经济的扩张或收缩,诸如价格、生产率、投资、进口、政府购买等在经济周期的阶段内,会具有一种规则的或可预测的行为模式,众多经济变量的这种可预测的协调变动趋势特征称为协动性。
4. 非定期循环
经济周期不是定期发生,意味着不同周期阶段的持续时间是不同的。但经济周期一定是周而复始的,即经济周期在经济系统内部会按照收缩→波谷→扩张→波峰的标准模式一次又一次再现。
5. 持续性
一个完整的经济周期持续时间是不确定的,会是一年或十年以上不等,因而对经济周期的预测是十分困难的。然而,一旦经济出现收缩,一般要持续一年或者更长一段时间,对于经济扩张,也同样如此,这就是经济周期波动的持续性。由于经济的持久性使得经济学家对经济中拐点尤为关注,因为拐点正确识别能够了解总体经济的变动方向,从而为经济政策制定者提供依据。
上述对经济周期的描述可以总结为以下两大主要特征:首先,经济周期在交替循环变化的过程中各种主要经济变量的协同变动(Comovement)以及不定期重复出现,但节点、持续时间以及振幅并非周期变化,对这一特征的描述目的是寻求经济周期波动过程中各经济变量之间的相互影响关系;其次,经济周期在波动的演变过程中呈现出非线性或非对称性特征,对这一特征的研究有助于判断经济周期进入扩张或衰退的时期。
从上世纪 90 年代开始,国内一些学者开展了对我国改革开放以来经济周期波动的实证研究,特别是刘树成教授对我国经济周期阶段的具体划分进行了系统的跟踪和研究,但总体而言,我国对经济周期问题的研究不够深入,缺乏一定的权威性,目前尚未有专门机构对经济周期年表进行发布。鉴于此,文章结合国内外相关文献,依据经济周期定期方法的研究脉络,对主流的方法进行评述,并对我国经济周期定期进行展望,以期能为相关研究机构和人员提供借鉴和理论支撑。
二、经济周期定期及拐点识别方法
1. 趋势周期分解方法
这类方法建立在非平稳时间序列模型基础之上,主要是借助变量消除趋势后的二阶矩来描述经济周期的波动性、持续性、协动性等特征,将序列分解为趋势成分和周期成分,根据所获得的周期成分通过构造整体经济景气合成指数,以此指数作为反映经济波动综合特征,进而确定周期拐点并对经济未来走势进行预测。由于大部分宏观时间序列具有非平稳的性质,因而基本存在着随机趋势,随机趋势由随机扰动项中的长期冲击所构成,周期成分由随机扰动项中的短期冲击所构成,趋势和周期成分都被事先指定为服从某一过程。文献中主要有两类趋势周期分解方法,一类是基于状态域的分解方法,这类方法中比较典型为 UC 分解法和 BN 分解法;另一类是频域分解方法,这类方法是基于谱分析,其中比较典型是 HP 滤波法和 BP滤波法。HP 滤波类似于一个高通滤波器,而 BP 滤波是带通滤波,这两种滤波的理论基础时间序列的谱分析。谱分析的基本思想是将时间序列看作互不相关的周期或频率分量的叠加,通过分析各分量的周期变化揭示时间序列的频域结构,进而得出主要波动特征。这两种滤波方法可以看作是基于频域选择滤波,从而将原始时间序列中的趋势成分和周期成分分离出来。下面简单介绍一下这几种方法的原理。
UC 分解法也称为不可观测成分分解法,将趋势成分和周期成分看成不可观测成分,依据经济理论建立模型进而估计趋势和周期成分。随机趋势成分可以是一个带漂移的随机游走过程,同时这种向上的趋势可能会随着时间而改变,此时趋势成分可以被扩展为一个局部线性趋势。给定趋势成分为局部线性趋势,给定周期成分为 ARMA 模型,记序列为 yt,则有:




滤波的目的在于将周期成分、趋势成分以及不规则成分尽可能完全的分离出来,理想的滤波可以保留所有周期波动,而将其他所有波动消除,包括小于六个季度的高频波动以及超过八年的低频波动。Stock & Watson (1999)认为 BP 滤波是理想滤波的最好近似,最简单的一阶差分可以消除趋势即低频波动,但加剧了高频波动。HP 滤波仅过滤掉低频的趋势成分,而把剩余成分作为周期成分,BP 不仅过滤掉低频的趋势成分和高频的季节波动以及不规则波动,而且还考虑到时间序列数据的平稳特征,因此分解出的周期成分相对要客观和准确。
2. NBER 经济周期定期
美国国家经济研究局(NBER)成立于 1920 年,是美国影响广泛的私立非盈利学术研究组织。自从 1978 年以来,NBER 经济周期决策委员会就开始对经济周期进行定期,委员会中由一批杰出的学者所构成,他们定期会晤共同讨论近期的数据并且不时发表声明在过去的一个特别时点经济出现衰退或经济衰退结束,这个时点就是经济的拐点,声明一旦被决策委员会认可,拐点时期就会确定下来,不会再做后续更改。NBER 对经济拐点的宣布受到社会各界的广泛关注,但也同时招致一些批评声音,首先由于经济周期决策委员所提出的经济拐点是各个委员相互妥协而达成的共识,每个委员对拐点的判断以及分析方法可能存在巨大差异,具有很大的主观性,因而定期方法不透明也不具有复制性。其次,NBER 对经济周期拐点的定期一旦确定,不情愿更改,不管统计数据是否有变动,这样就无法保证定期的准确性;再次,NBER 委员会为了保证周期拐点发布的可靠性,其往往会滞后一段时间宣布在某个时点经济进入衰退或扩张,比如 1991 年 3 月和 2001 年 11 月的经济周期谷底直到事实被认定两年后才宣布。2007 年美国爆发金融危机,受此影响,美国经济周期在 2007 年 12 月进入衰退的拐点,而这个时点直到 2008 年 11 月 28 日才宣布。Chauvet & Piger(2005)评论说,NBER 委员会经济周期拐点定期实质上是对历史数据的归纳和分类处理,不适用于作拐点预测。因此,对经济拐点的识别需结合数据引入规范的算法和统计模型。
3. 非参数 BB-HP 方法
NBER 的 Bry & Boschan(1971)提出了一种非参数的确定拐点方法,该方法是基于一些识别准则和程序而设计的,由于该方法相比 NBER 定期委员会的周期定期具有透明性和可复制性,受到了业内的好评,随后被许多国家的经济学家所采用以分析经济的波动特征以及对经济拐点进行识别。该方法对周期的检测和描述是通过对序列中潜在的拐点进行分离然后依据以下三个准则划分出扩张期和收缩期:一是确保波峰和波谷能够交替


周期定期可靠性。由于 Hamilton 的机制转换模型只适用单变量的时间序列数据,可以很好的刻画经济周期扩张和收缩阶段的非线性特征,因而忽略的经济周期的协动性。Kim & Yoo (1995)等将 Hamilton 的模型推广到多变量的框架上来,较好地刻画了经济周期的非线性以及协动性特征。然而这一推广使得模型中的待估参数倍增,因而在实际操作中不可能纳入较多的变量。
鉴于 NBER 对经济周期定期时非常重视经济变量的协动性,Stock&Watson 受 Sargent&Sims(1977)动态因子可以解释美国季度宏观经济变量大部分的方差变动成分这一发现的启发,试图重新对 NBER 经济周期的基准周期进行定期,以使得对经济周期的定期能够建立在统计理论基础之上。他们利用动态因子模型从经济活动中的大量变量中提取共同因子来替代 NBER 的一致经济指标来对经济周期进行定期。Stock & Watson(1989)将动态因子模型用在美国的月度经济数据,结果表明,对提取的共同因子的自回归模型拟合,在周期频率上很好地吻合和美国 GNP波动特征。动态因子模型由于考虑到更多经济变量对整体经济波动的影响,因而此模型可以解决单变量识别经济周期存在的缺陷,然而,动态因子模型无法刻画出经济周期的阶段性变化以及经济在扩张和收缩时期的非线性特征。Stock & Watson 在对动态因子模型重新审视后,发现模型不能识别出周期波动的非线性特征的原因在于模型本身所施加的线性约束,这一发现表明,为了准确识别出经济的波动特征,需要及时识别出那些可能引起经济非对称波动的某些异质性冲击因素,比如经济政策变化对经济波动冲击所造成的时变特征。
考虑到动态因子模型和机制转换模型各自优点,Diebold &Rudebusch(1996)通过运用马尔科夫机制转换模型对商务部的一致指数以及相应的分指标拟合将这两种模型结合到一起,构建一个统一框架来分析经济周期的波动特征,因子结构用来刻画经济的协动性,而机制转换用以刻画动态因子的非线性特征,他们的实证结果表明机制转换动态因子模型是合适的,同时也说明模型的经济含义与宏观经济理论的吻合性,但是他们限于理论的局限,未能对该模型做出完全估计。依照 Diebold &Rudebusch(1996)的建议,Chauvet (1998)重新构造一个新的统计模型能同时刻画经济波动的非线性以及协动性特征并且对该模型进行了完全的估计。在估计时,将 Hamilton(1998)中的算法和Kim(1994)中所提出的离散形式的卡尔曼滤波方法结合到一起,采用极大似然法对所构建的模型进行估计。模型的构建过程如下:考虑 N 个时间序列,令第 i 个序列的对数一阶差分形式为


Chauvet (1998)使用美国的 4 个宏观经济指标估计上述马尔科夫动态因子模型,结果显示经济处于衰退期的转换概率要比经济处于扩张期的转换概率大,即经济衰退的持续时间要比经济扩张的持续时间要长,这与 NBER 所宣布的扩张与衰退阶段特征是一致的。Mariano & Murasawa(2003)在 Stock & Watson(1991)基础上,提出了能够综合利用月度数据和季度数据混频数据模型,并利用美国的四个月度一致指标和 GDP 季度环比增长率,构造了能够度量经济周期波动的一致指数。在此基础上,Camacho & Perez(2010)在综合利用月度和季数据的同时采用DFMS 模型刻画了经济周期的阶段性变化,成功识别了经济扩张和衰退的拐点,这样可以扩充信息容量,减少识别经济周期阶段时的测量误差,因而更加有效的捕捉到经济变量之间的协同变动。Chauvet & Piger(2008)将 DFMS 模型方法与上述的非参数 BB-HP 方法进行对比来评价实时表现力。两种方法虽然都能比较准确的识别出 NBER 实时样本内数据的周期定期拐点,没有出现不一致识别情况,并且比 NBER 更能及时地识别出经济周期的波谷,但相比来说,马尔科夫动态因子模型在识别NBER 经济拐点时要更加准确,所有估计结果都比较稳健 。
Chauvet & Piger(2008)在其文中运用 Kim & Nelson(1998)所描述的Gibbs 抽样方法用以估计 NBER 模型以及衰退概率,Gibbs 抽样产生状态变量 St以样本内所有数据 ΨT为条件的后验分布,后验分布的期望与衰退概率 P(St=1|ΨT)相对应,我们通过这些衰退概率来获取经济周期的拐点日期。
以上分析介绍了几种主要的经济周期和拐点的定期方法,当然也并不局限以上几种,也有研究在以上方法的基础上或者采用其他方法对经济周期的波动特征以及拐点识别进行研究,Simpson 等 (2001)与 Moolman (2004)利用时变机制转换马尔科夫模型分别考察英国和南非的周期波动并进行拐点识别。Joakim& Timo(1999)应用具有连续性机制转换特征的非线性平滑转换自回归模型(STAR)来分析瑞典经济周期。
在经济周期的相关研究中,还涉及到对经济转向衰退的概率进行量化,Birchenhall 等(1999)通过构造合成一致指标并运用Logistic 分类方法来预测经济周期转换,Estrella & Mishkin(1998)将一些金融指标纳入 Probit 模型来考察美国经济衰退概率的样本外预测效果。后来,还有许多学者对 Probit 模型进行研究和扩展,如 Chauvet & Potter(2005) 采用更加一般的 Probit 模型设定来考察经济衰退概率,比如允许扰动项存在自相关结构以及存在多阶段转换的经济周期特征,Silvia, Bullard & Lai(2008) 纳入更多的经济指标通过分步回归方法来预测,结果表明通过Probit 模型能够显着提高模型的预测能力。受此启发,Chen 等(2011)采用 Probit 动态因子模型来预测美国经济的衰退概率,原因在于动态因子可以反映经济系统中基本面信息,从而可以进一步提高预测能力。虽然这些方法不能直接用来对经济周期进行定期,但可以为找寻新的定期和拐点识别方法提供一些思路和借鉴。
三、我国经济周期定期研究
经济周期研究需要解决的一个关键问题是对经济拐点进行确定。我国经济周期的具体划分方面,刘树成基本依据 GDP 增长率对我国经济周期问题进行了系统的跟踪和研究;董进(2006)比较了几种滤波等方法,对我国 1952-2005 年的数据进行分析来确定经济拐点;王建军(2007)运用修正后的马尔科夫机制转换模型,对我国 1953-2005 年的年度实际产出增长率的数据进行了拟合,发现该模型较好地刻画了我国实际产出增长的周期性变化;陈昆亭、周炎、龚六堂(2004)从现代经济周期理念出发,在详细比较了各种滤波算子的基础上,利用 BK 滤波对 1952-2001 年的 10 多个宏观经济时间序列进行消除趋势,然后考察了新中国成立以来我国经济周期的波动性、持续性、协动性等现代周期特征;刘恒和陈述云(2003)选择反映生产规模、市场环境和开放度为主的宏观经济指标,构造了一个能综合反映经济周期波动的短期指数并以此为依据分析了我国经济周期的周期波动特征;王金明和高铁梅(2006)利用动态马尔可夫机制转换动态因子模型,构建了刻画我国经济协动性和非对称两大特征的经济景气指数来判断经济的波动特征;陈磊和孔宪丽(2007)基于月度宏观经济指标,采用一致合成指数的转折点,以及在 Bry & Boschan(1971)的基础上,采用改进的非参数方法来确定经济周期波动的转折点,同时考察滞后和先行合成指数,以进一步确认重要周期转折点和预测未来经济走势;郑挺国和王霞(2013)构造一种能够综合利用我国季度数据和月度数据的经济周期计量模型,即混频数据机制转换动态因子模型来识别我国 1992 年以来的经济周期态势,并在搜集宏观经济实时数据的基础上,对我国 2005 -2011 年间经济周期的识别及测定进行实时分析。
四、对我国经济周期定期的进一步研究设想
从以上分析可以大体看出,国内外文献中对经济周期定期和拐点识别,大致存在两种主流方法,第一种方法归功于Burns & Mitchell(1946),首先针对一组大量经济指标分别采用Bry & Boschan(1971)的算法对经济拐点进行识别,然后根据这些拐点总体分布确定一个共同的时期作为经济拐点,Stock &Watson (2014)称之为 Date-Then-Average 方法;另外一种方法恰恰相反,使用 Bry & Boschan(1971)的算法对若干经济活动的加总指标进行拐点识别,比如 NBER 经济周期委员会一般采用五种高度加总序列,即实际季度 GDP 和四个月度序列包括实际个人可支配收入、限额以上零售业贸易总额、工业增加值增速和非农就业总人数。可以利用其他一致合成指标来识别经济拐点,这些指标可以看成一些月度综合指标的加权平均,也可以运用 Stock & Watson(1989)的动态因子模型提取一个动态因子作为体现综合经济的一个一致合成指标,这种方法 Stock &Watson(2014)称为 Average-then-Date 方法。从现有文献中看,目前 Average-Then-Date 方法由于其可操作性强显得更加流行,但与 Date-Then-Average 方法相比,这种方法是否更加适宜确定基准周期的拐点?Stock & Watson(2010)重新仔细审查这两种方法并利用美国 1959-2010 年的 270 个月度数据进行了实证分析,发表了一些基准周期拐点识别的前期结果,总体经济拐点的最终确定通过所有单个序列拐点的无调整均值得到,Stock &Watson(2014)进一步采用另外两种统计量 (众数和中位数) 并且通过考虑简单随机抽样和分层抽样两种抽样方法对数据的不规则性进行调整,实证分析和对比结果表明,Date-Then-Average方法,由于包含了基准周期拐点的置信区间,更能对确定基准周期年表过程补充有价值的信息,通过众数所估计出的拐点与Burns & Mitchell(1946)和早期 NBER 学者紧密相关。众数相对均值和中位数来说具有更明显的集中趋势并且对异常值不敏感,因而在拐点估计时显得更为可取。
总体看来,我国经济周期定期的研究还不够深入和系统化,由于目前尚没有权威机构对我国经济周期进行实时监测和发布,因而在划分经济周期和拐点识别时,往往局限于一种方法,不同方法有效性的比较缺乏一个基准参考。采用年度、季度和月度宏观经济数据以及金融市场的一些更高频的金融指标由数百个变量所构成的混合数据集,通过借鉴 Stock & Watson(2014)的研究方法,对我国经济周期波动的阶段特征和周期拐点进行研究,将是一个具有挑战性且非常有意义的工作,这将是我们努力尝试的方向,希望在我国经济周期定期的研究中填补一点空白。
【参考文献】
[1] Chauvet,Marcelle,and Jeremy Piger. A comparison of the real-time perf-ormance of business cycle dating methods [J].Journal of Business Econom-ics and Statistics,2008,26:42-49.
[2] Chen,Zhihong,Iqbal,Azhar & Lai,Huiwen. Forecasting the Probabilityof US Recessions:A Probit and Dynamic Factor Modeling Approach [J].Canadian Journal of Economics,2011,Vol.44,May:651-672.
[3] Hodrick,Robert J. and Prescott,Edward C.. Postwar U.S. Business Cyc-les:An Empirical Investigation [J].Journal of Money,Credit and Banking,1997,29:1-16.





