4.3 字符分割
车牌的字符分割算法是在车牌定位系统中较为简单的部分。字符分割的作用是将定位出的车牌区域中的字符进行分割,作为卷积神经网络识别字符时的输入。字符分割较为简单,只需使用传统图像处理技术进行处理,并且可以获得较高的分割正确率。在字符分割环节没有复杂多变的环境,分割的车牌区域情况较为单一固定,因此没有结合卷积神经网络技术来提高字符分割准确率的必要。本文使用常规的数字图像处理技术来进行字符分割,下面对具体的字符分割方法进行介绍。

根据中国车牌的先验信息可知,车牌的背景为蓝色与黄色,对应的字符颜色为白色与黑色。通过取轮廓的方式进行字符定位与分割无法判断车牌背景颜色,因此在字符分割前,对背景的颜色进行判断。根据判断出的颜色结果,对二值化的参数进行设置,再通过轮廓提取对字符进行分割,如图 4.15 所示为基于轮廓提取的字符分割算法流程图:
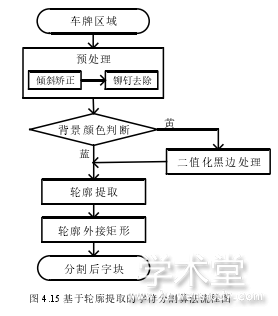
4.3.1 倾斜矫正。
物流园门岗闸道摄像机的设置可能在闸道的一侧,导致获取的车牌图像倾斜,对倾斜的车牌图像在提取轮廓后进行外接矩形选取,会导致标准的外接矩形无法正确地将字符区域截取。因此,需要对车牌区域进行倾斜判断,并进行倾斜矫正。
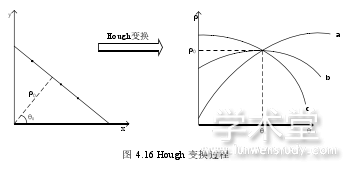
倾斜的车牌进行倾斜矫正时,利用车牌中大量直线型的边缘来判断是否倾斜,并检测倾斜的角度进行矫正。采用 Hough 变换对直线进行检测与处理,下面介绍具体的过程。Hough 变换将直角坐标系与极坐标系两个空间变换中,一个空间具有相同形状的直线映射至另一个坐标空间的一个点上并形成统计峰值。在直角坐标系中的一条直线在极坐标系中的表现为一个点,如图 4.16 所示。假设直角坐标系中的一条直线为y = kx + b,则在极坐标系中表现为一个点,设为表示直线的倾斜角度。直角坐标系中一个点在极坐标系中的表现为一个正弦曲线,所有在直线上的点在极坐标系中表现出的正弦曲线都经过同一个点(0)。对于整个车牌图像,因为二值化的图像中字符的位置的像素值为 1,即白色。
因此遍历车牌区域中所有像素值为 1 的像素点,通过直角坐标系中的坐标计算出极坐标对应的(??,??)值,对所有相等的(??,??)值(设定θ值在±1°内即认为相等)进行统计,最后得到的最多次数的(??,??)值即为车牌区域最长直线的极坐标参数,对应的θ值即为此最长直线特征的倾斜角。选取最多统计次数的(??,??)的原因是本文为了尽可能减少计算资源消耗,只选取车牌区域中最长的直线来检测车牌的倾斜角。已知倾斜角后,对车牌区域图像进行反向θ角度的旋转即可完成倾斜矫正。
4.3.2 铆钉去除。
根据中国车牌的先验信息可知车牌有四个铆钉,铆钉在二值化后显示为白色,而车牌字符二值化也为白色,如图 4.12 所示。所以,铆钉会对提取轮廓造成影响,必须提前对车牌上的铆钉进行处理,将铆钉处的像素值由 1 改为 0 即黑色。由于车牌中字符部分具有较多白色特征,因此对车牌每一行元素进行遍历时,可以通过单行白色像素点的数量判断此行是否有铆钉,若存在白色像素点的数量大于 0 并且少于一定设置好的参数量时,可以判断为铆钉部分。以下为去除铆钉方法的具体介绍:
对车牌区域的二值化图像进行逐行像素遍历,假设车牌区域的高为 h 像素,则遍历的范围为 1-0.25h 与 0.75h-h。遍历范围设定后只需原本遍历所有像素行时计算资源消耗的一半,可以有效提高实时性。具体的方式是,判断每行像素值为 1 的像素点个数,若个数 w 满足条件0 < w ≤ m时,将所有像素值为 1 的像素点更改为 0,即将所有白色像素点变为黑色。m 的取值经过多次不同车牌图像的测试,设置为 30,此时铆钉去除效果最佳。去除铆钉后的效果如图 4.17 所示。

4.3.3 背景颜色判断。
根据车牌定位的结果,提取出原始图像的彩色车牌区域,根据 RGB 信息中的 B 数值判断出车牌颜色是否为蓝色,非蓝色即为黄色背景车牌。判断车牌背景颜色的原因:
(1) 为使用者提供更多的车牌信息,可以有效区分是蓝牌还是黄牌车牌。
(2) 由于二值化对灰度化后的图像进行处理,若对不同背景颜色的车牌区域进行相同的二值化,会产生不同的结果。若对蓝色车牌使用正确二值化图像的二值化操作,即设置对应蓝色车牌背景的二值化操作参数,对黄色背景车牌进行二值化操作时会得到错误的二值化图像,车牌二值化图像黑色的边框会对轮廓提取造成干扰,导致无法正确对字符进行分割。
4.3.4 轮廓提取。
使用的方法与车牌定位中的相同。虽然对于标准的英文字母与数字不存在单个字符有断点的情况,但是二值化图像可能因为噪声的影响,导致实际情况中单个字符区域有断点情况。因此在轮廓提取时,会因为单个字符区域存在断点,将一个字符区域识别为两个字符区域。为了降低这样原因导致的分割错误率,继续引入车牌定位中使用的膨胀与腐蚀操作,可以通过膨胀操作使分离的单个字符变为一个闭合连通域。膨胀操作时设定的参数远远小于车牌定位中设置的参数,防止膨胀操作导致两两分离的字符重叠变为一个闭合连通域。最后,在膨胀与腐蚀的闭操作后,对车牌区域进行闭合连通域轮廓提取,并对提取出的轮廓取外接矩形,对所有外接矩形进行截取,得到分割后的单个字符块。
在实际的分割操作中,一些特定的字符可能会导致特定的字符分割出现较高的错误率,在字符分割后加入一定的修正操作,尽量减小这种情况引起的分割错误。具体操作是,判断外接矩形的数量,根据车牌先验信息可知,正确的外接矩形数量为 7。(1)若外接矩形数量小于 7,则将宽度最大的外接矩形使用更大的膨胀操作参数进行闭操作,并取轮廓外接矩形,再一次判断外接矩形数量,重复以上操作,直至外接矩形数量为 7;(2)若外接矩形数量为 n 大于 7,则将宽度最小的 n-6 个相连的矩形区域重新进行闭操作,在闭操作时使用更小的膨胀参数,并再次对结果取轮廓外接矩形,判断外接矩形数量,重复以上操作,直至外接矩形数量为 7。通过以上的操作与修正,可以将绝大多数车牌字符准确地分割。
本文通过对车牌区域精确的定位,以及字符分割前充分的预处理,结合有效的字符分割操作与修正,在实际车牌字符分割时得到了高于预期的效果,如图 4.18 所示为分割后的车牌字符块。

在实际的分割操作中,一些特定的字符可能会导致特定的字符分割出现较高的错误率,在字符分割后加入一定的修正操作,尽量减小这种情况引起的分割错误。具体操作是,判断外接矩形的数量,根据车牌先验信息可知,正确的外接矩形数量为 7。(1)若外接矩形数量小于 7,则将宽度最大的外接矩形使用更大的膨胀操作参数进行闭操作,并取轮廓外接矩形,再一次判断外接矩形数量,重复以上操作,直至外接矩形数量为 7;(2)若外接矩形数量为 n 大于 7,则将宽度最小的 n-6 个相连的矩形区域重新进行闭操作,在闭操作时使用更小的膨胀参数,并再次对结果取轮廓外接矩形,判断外接矩形数量,重复以上操作,直至外接矩形数量为 7。通过以上的操作与修正,可以将绝大多数车牌字符准确地分割。
本文通过对车牌区域精确的定位,以及字符分割前充分的预处理,结合有效的字符分割操作与修正,在实际车牌字符分割时得到了高于预期的效果,如图 4.18 所示为分割后的车牌字符块。
4.4 基于 Yolo2 字符识别。
字符识别是车牌识别技术最终的环节也是最重要的环节,字符分割得出的结果作为字符识别的输入。字符识别算法的选取,在本文显得至关重要。传统的数字图像处理技术使用的传统识别算法消耗较小的计算资源,能够达到一定的识别精度,符合过去的计算机性能。而由于现在计算性能的快速发展,可以利用更多的计算资源来对字符识别进行改进。因此,本文选取了基于卷积神经网络的字符识别算法来提高识别的准确率,同时有效地保证识别的实时性。
4.4.1 Yolo2 网络模型。
卷积神经网络中有许多网络模型,例如 AlexNet,VGGNet,GoogleNet,ResNet 等。这些经典的模型虽然可以达到较高的识别率,但是这些模型的都是针对复杂场景并且分类数量巨大,对于车牌识别几十个类别不是很适用。因此,本文使用了基于 Darknet-19 的 Yolo2,此网络虽然在识别率上稍低于 GoogleNet 与 ResNet,但是由于它支持的类别数量在设计时就为几十个,符合本文车牌字符识别的应用场景[62]。同时其轻量化的优点与其所需要的 G-ops(衡量计算机计算能力的指标单位)非常小,仅仅为 5.58,在识别速度上有非常大的优势,这是本文选择 Yolo2 来识别车牌字符的原因。
Yolo2 可以做到目标检测,即在图像分类的基础上做到目标位置的精确标注。利用对图像进行分类的结果,并参考提前设置好的标签,就可以得到车牌的字符识别结果。Yolo2 采用神经网络的结构,具有 32 层。其结构如经典的卷积神经网络一样,只是具有更多的卷积层与池化层,并且在第 25 层与 28 层各加入了一层 route 层,route 层的作用是完成层的合并,例如第 28 层的参数为‘24’与‘27’,其作用是将第 24 与第 27 层合并并输入到下一层。Yolo2 最后一个卷积层的输出大小为 13*13,图片在卷积与池化后变为 13*13 的格,其中一个格的输出数量为 125,每个 13*13 的格对应 5 个边框,如图 4.19 所示,每个边框对应 25 个浮点数,其中20 个浮点数对应不同的 class 其所对应的 probability,即目标为此对应类的可能性,另外 4 个是为了用相对位置来标示边框的位置与大小而记录的信息,最后一个浮点数表示 confidence,标示定位出的边框中有目标对象的可能性,所以最终的输出为 13*13*125。
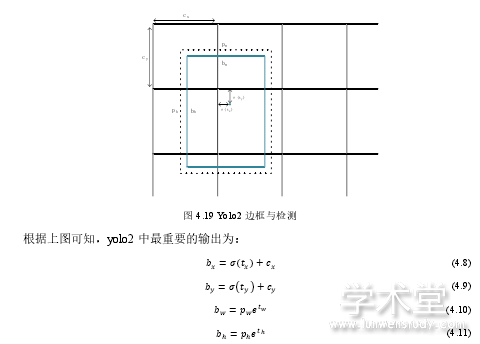
Yolo2 使用相对位置与偏移量的方式来对目标位置进行标示,没有使用绝对坐标来简化标示,这样可以获得更多的空间信息,所以在结构层中没有全连接层。
在标示出可能有目标的区域后,需要对目标进行分类,分类的根据为有真正目标的可能性与目标对应类别可能性的乘积,即 confidence * probability,若乘积大于门限值 0.24,则输出当前 boundingbox 对应的类别,并对此类别的可能性 probability 进行显示。Yolo2 总共会生成 13*13*5 个 bounding box,但根据 probability 判断并过滤,最后预测的数量与结果并不会很多。
4.4.2 Yolo2 模型改进。
车牌识别与 Yolo2 实际要解决的识别问题有较大的区别。车牌识别仅仅需要对简单的字符进行识别,其定位的难度很小,但是对图像分类有更高的要求。同时,Yolo2 的输入数据为已经分割好的字符,不需再判断输入的单个字符图像中是否有真正的字符。Yolo2 是对生活中的图像进行识别与分类,图像的分辨率较高,所以其使用 448*448 的图像作为输入图像,以防止图像经过压缩后过于模糊无法有效提取特征。应用到车牌识别中时,从车辆图像中提取出车牌区域后相当于对原始图像经过了一次压缩,在字符分割后等于完成了对图像的二次压缩,输入的单个车牌字符区域图像的分辨率已经很小,因此对于预输入的图像不需要这么大,可以减小分辨率以提高实时性。所以本文对于 yolo2 的模型针对本系统作出了以下的改进:
(1) 将 Yolo2 原始 448*448 的输入标准尺度改为 224*224,即变为原来的四分之一,并且对应地修改每个层网络的特征平面大小。
(2) Yolo2 输出的 5 个浮点数中,4 个为 boundingbox 的相对位置信息,另一个为 confidence值,即目标区域中有真正目标的可能性。根据有效的字符分割,可以认为输入的图像所得到的 boundingbox 中有接近 100%的含有真正目标的可能性,因此将 confidence 的值设置为 1,默认不计算可能性,以减少计算资源消耗,提高实时性。
(3) 由于将 confidence 值修改为 1,因此 confidence*probability 的值也会相应增大,所以将threshold(可以将结果输出的门限值)由默认的 0.24 提高到 0.42。
(4) 车牌字符由汉字,字母,数字组成,其中汉字有 31 个,字母有 24 个,数字有 10 个,总共有 65 个类别,而 yolo2 不支持直接对 65 个类别进行分类。因此,本文将字母与数字一起,汉字分开,分别训练两个模型。解决了过多类别无法分类的同时,又提高了识别的准确率,在识别率提升的情况下,牺牲了一点在可接受范围内的计算资源消耗。
Yolo2 网络在使用 Titan x 作为 GPU 加速时的识别速度可以达到 40-90FPS(每秒处理图像数),由于车牌识别时输入的数据是已经分割后的字符,且图像大小很小,因此本文在实际字符识别时,单个字符可以达到 10ms 的识别速度。
4.4.3 Yolo2 网络训练。
基于卷积神经网络的车牌字符识别算法,有一个优秀的预训练模型非常关键。Yolo2 自带了 VOC2012 数据集预训练的模型,但是由于 VOC2012 数据集中的 20 类目标都是人或者物,而本文所需针对的目标是车牌字符,由 Yolo2 提供的预训练模型无法满足本文的需要。因此,对于车牌字符识别需要自己设计识别的方式,并且需要准备针对车牌字符识别的数据集进行训练。由于汉字与数字和字母分别进行识别,需要准备针对汉字的训练模型与针对数字和字母的训练模型。
数据集准备字符分割得到的字符图像,加上网上寻找的车牌字符组成本文的数据集,数据集由汉字数据集与数字字母数据集组成。其中,汉字数据集由 12400 个字符图片组成,平均每个字符有 400 个样本。数字和字母数据集由 14400 个字符图片组成,平均每个字符也有 400 个样本。
在训练模型时,数据集由训练数据与测试数据组成,其中 80%的字符图像作为训练样本,其余 20%的字符图像作为测试样本。部分训练用数据集中样本如下图 4.20 所示。


整理好所有数据集中的图像与标签后,制作成 chinese.data 与 character.data 数据集。本文在实验室中,使用带有双路 Titan x 的电脑进行训练,通过 GPU 进行加速,可以有效提升训练的速度。在对模型进行训练时,本文对参数的设置也经过了针对性的修改,下面介绍 Yolo2模型训练中几个关键的参数。
true positives:识别的目标被正确的识别出类型。
true negatives:非需要识别的目标,没有对其识别。
false positives:识别的目标与其对应的真实目标类型错误。
false negatives:非需要识别的目标,并且将其识别为错误的类别。
recall:召回率,是指被正确识别出的目标类别数量与图像中实际包含的目标类别数量的比值,

在GPU加速的情况下,将数据集输入Yolo2网络中进行多次迭代,直至达到设定的阈值,得到针对汉字与字母数字的两个预训练模型。
Yolo2 网络分类Yolo2 在识别图像时,不需要对输入的图像进行归一化处理,只需将字符分割时第一个得到的图像输入网络,使用汉字预训练模型进行分类。字符分割得到的后六个分割后字符图像输入网络,使用字母数字预训练的模型进行分类,得到数字与字符的分类结果。最后,对分类结果组合输出,且只针对得到最高 probability 的结果进行输出。同时,将字符分割时对车牌颜色的判断结果进行显示,显示内容为“蓝牌”或者“黄牌”。
4.5 总结。
本章主要对物流园中管理系统所需要的车牌识别技术进行了研究设计,提出了优化后的基于卷积神经网络的车牌识别方法,针对车牌识别中的车牌定位、字符分割与车牌字符识别三个环节进行分别分析与设计。在基于矩形匹配的车牌定位算法的基础上,提出了优化的基于卷积神经网络的矩形匹配车牌定位算法;详细阐述了基于常规的数字图像处理技术的字符分割;对 Yolo2 网络模型进行针对车牌字符识别的改进并对分割后的字符进行识别,同时阐述了本文的预训练模型训练方法。





