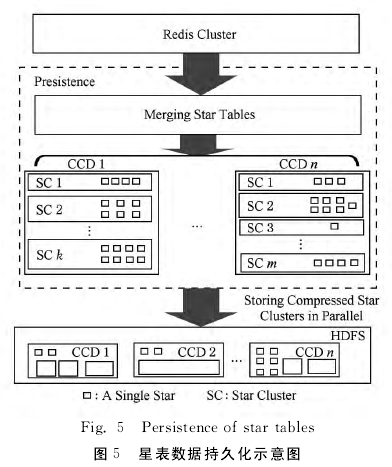
实现上,本文使用Spark[10]和HDFS[11]实现持久化操作。在将星名映射到不同的Hash桶之后,使用Spark对 每 个Hash桶 中 的 星 批 量 从Rediscluster读出,经过Spark sql[12]的建表操作,压缩后写入HDFS.为提高写性能,不同Hash桶的写操作是可以并行执行的。需要注意的是,同一个CCD的星表簇数据需要写入同一个CCD的目录下,以便于快速检索。从本质上看,为了查找某颗星的光变曲线,需要经过两级检索:1)确定该星所在的CCD;2)确定该星所在的星表簇2.4查询操作基于星表簇的存储方式,查询操作并不能直接使用SQL完成,对于某些查询而言需要做一定程度的解析。
查询共分为2种类型:1)返回的结果不需要随时间变化的属性,如查询某位置范围内所有出现的星名;2)返回的结果需要随时间变化的属性,如返回某颗星的光变曲线。通过收集天文查询需求,本文发现天文学家虽然关注光变曲线,如图6,但是锁定查询哪条光变曲线的操作往往集中在不变的属性列上。如查询某个范围内所有星的光变曲线,首先是查询该范围内的所有星名,其次是查询该星的光变曲线。因此,无论结果是否需要随时间变化的属性数据,都需要先查询与时间无关的属性数据。
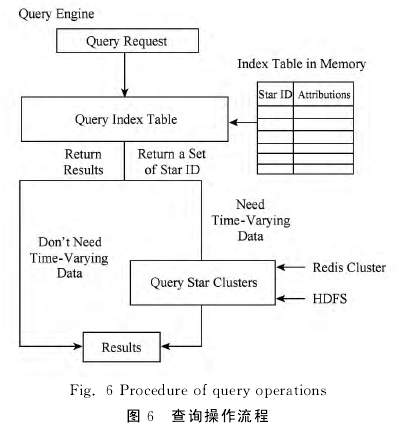
如图6所示,本文合并所有CCD交叉认证时使用的模板表,并加入一些随时间变化数据的统计列,如亮度均值、方差、最大值和最小值等,构成一个逻辑上的索引表,因为该表很小,可以常驻内存。一个查询请求到来后,先判断结果的属性列是否需要随时间变化的属性,如果不需要,查找索引表,直接返回;如果需要,查找索引表,找出满足要求的星名,然后查找原始数据。这样做的好处是:1)对于结果不需要随时间变化的数据,查找索引表能避免扫描原始星表数据,提高查找性能;2)对于结果需要随时间变化的数据,查找索引表能最小化扫描原始星表数据的次数和范围,以提高查找性能。
对于采用缓存架构的本系统而言,原始星表数据存储于二级缓存(Redis cluster)和硬盘(HDFS)上,查找条件有可能涉及到这2个数据源。因此,就查询数据源而言,可分为以下3种策略对原始星表查询。
1)仅从二级缓存查询。查找索引表找出满足条件的星名集合;将该集合传入Redis cluster查询对应星的全部属性列;筛选符合条件的属性列。
2)仅从硬盘查询。查找索引表找出满足条件的星名集合;使用持久化的Hash函数将星名的结果集合映射到星表簇;对同一星表簇的星进行批量查询并筛选符合条件的属性列;对于不同的星表簇可以并行查询;最后合并不同星表簇的结果。
3)从二级缓存和硬盘查询。并行从2个数据源按照上述的策略查询,最终将结果合并。
3系统验证与分析
3.1实验准备
本文在Ubuntu 14.04,Hadoop 2.6.0,Spark1.6.2和Redis 3.2.5平台上建立了验证系统,采用10台物理机构建Hadoop,Spark,Redis cluster和分布式GWAC数据模拟生成器集群。对于Hadoop,Spark和分布式GWAC数据模拟生成器集群都使用相同的物理机作为主节点,剩下的9个物理机作为从 节 点 (模 拟9个CCD),此 外Spark使 用standalone模式进行资源管理。对于无中心结构的Redis cluster,每个物理机上开启4个Redis节点进程,共40个节点,并且另加入8个Redis slave节点作为整个Redis集群的冗余备份。
整个物理集群为同构环境,每台物理机使用英特尔i7-4790处理器、32GB DDR3-1600内存和1块500GB 7200SATA硬盘,节点之间采用万兆以太网互联。





