
һ������
����
���������������ڷ�ͥ��ѧ֤�ݼ�������ı��������Ѿ���Ϊһ���dz����ŵĻ��⣬�ܶ�ר�Һ����嶼�Է�ͥ��ѧ֤�ݴ�ͳ�����ϵ����������ʽ���������,�������Dz��ѿ������߶���DNA�ķ�����ϵ�����������з�ͥ��ѧ֤�ݣ�����ָ�ơ��㼣�����ᡢ��ά���ʼ��ȣ��ĵ䷶����Ȼ���Ƽ���1Ҳ�������С�Ŀǰ�����Ƽ��������α��������ڹ���ǹ��ڶ����ڼ��ҵ�����֮�У��������۵Ľ�����Ҫ��Χ�ƻ�����������Ȼ�ȣ�LikelihoodRatio,��дΪLR�������������ʽ�Ƿ����������Ƽ���չ���ġ��������Ĵ����ǵ�Rose��Morrison����Ϊ������������֧�ֺͳ���������LR��ϵ�����Ƽ����е�Ӧ��,��Ӣ����French��Nolan��Foulkes��Harrison��McDougall�Ⱦ��������ҵ��Աȴ��ȷ����������LR��ϵ�����Ƽ����е�ʹ�ã��ᳫ���ð�����Ҷ˹ԭ���ִ�˼���Ӣ������������ʽ,������Broeders�Լ�����Eriksson��ѧ��Ҳ�����˶�ʹ��LR��ϵ�����ǡ�2011��������Ƽ���Э�ᣨIAFPA�����2������ר�������˹���“�ڷ�ͥ��չʾ֤��”������ר�⣬�ź�����֧��LR��ϵ��ѧ�߲�δ�ڴ˻����Ͼʹ˷������¡�������������Ҳ��ר������LR��ϵ�����Ƽ����е�Ӧ������,Ȼ���۵㲢��һ�¡�Ϊ�ˣ����Ľ��ڽ��ܹ���������о��ɹ��Ļ����ϣ�̸̸�Ը������һЩ���������ڼ�������ı�������������ݵľ��巽�����ܲ��ɷֵģ������ȴ����Ƽ����ķ���̸��
�����������Ƽ����ķ���
����
��������ʷ�Ͻ������Ƽ����ķ����������������������ױȶԷ�������ѧ����������-��ѧ������˵�����Զ�ʶ��ȼ��ַ������ܶ�̿���������ж��ж��⼸�ַ�������Ҫ������������ϸ����������������ܡ�
������һ����������
����
�������ڹŴ������ڷ��������ľ��ޣ�˵���˼���ֻ��ͨ���������У���ʱ��˵���˼���Ҳ���ǽ���������ָ�Ķ���֤�ݣ�ear-witnessevidence�����Ӽ����ĽǶȽ�������֤��ֻ�ǻ���֤�˶������ļ�����еġ�Ŀǰ��ʵʩ����������������Ǿ���һ��רҵ������ѧ������ѧ��ѵ�����߱�һ�����������ѧ�ң���/���dz������߱�ʹ�ù������������������ʽ���ʽ����������.
����
����������������auditoryapproach����Ҳ����������ѧ��������auditory-phoneticapproach��������-��֪��������auditory-perceptualapproach�����÷������Է�Ϊ���壨holistic����֪�ͽ�����analytical����֪�������棬���к���Ӧ�ø�Ϊ�ձ顣�����֪����Ҫ���о������ط���������������������Dz���һ����˵�ģ�������Ŭ��ȥ���ɷַ������÷��������ڷ�רҵ��Ա���е�˵���˼����������֮�£�����ר�ұ���ͨ�˾��и�������ơ��������֪�෴��������֪��Ҫ���������Ͻ��гɷַ���������ͨ�����Դ����β��棨segmentallevel���ͳ����β��棨supra-segmentallevel������������У���ʱ��Ҫ�漰��һЩ��������ѧ����ϵѧ�ķ�����ѧ������non-linguisticfeatures����
����ʵ���У��������ȴӳ����β���Է������ʣ�voicequality�������������¹���Ӣ���ļ���ר��ͨ��ʹ��Laver�����ɤ��������ܶ������ķ������ͣ�����ɤ�������������ֲ�ɤ���ͼ����ȣ����������ʹ�֣�����Ӣ��JPFrenchAssociatesʵ���ҵ�ר���ڼ����п��ǵ�ɤ���������38άȻ��Ҫ���������ϵ�����ģʽ�����ٺ�������ص���м��顣����Ӣ���в���������ģʽ�ͺ�����ͨ��˵���˲���������ģʽ�ȡ����β���ĸ�֪��Ҫ����Ԫ�����������ľ���ʵ�������������Ա����Ҫ���ݼ�ģ�����������������ϵ��ȥ�����ͱȽ�ij��������/���صĸ��ֱ��壬����ʱ����Ҫʹ�ã���ʽ�ģ��������������������ͼ�¼��ͬʱ��������Ա��������������һЩ��̬�ص㣬��˵�����������������Ƿ����ͬ���������������������֮�⣬˵���������������ȱ�ݣ���ڳԣ������ԡ�����������������ķ������ʻ�ѡ���ʹ�á�����ģʽ�������ǣ���“��”��“��”��“��”��“�Dz���”�ȣ�ʹ�õ�Ƶ�ʺͷֲ�������ת����ͣ����Ϊ������������ͣ�١�ͣ�ٵ�ʱ����λ�á�ͣ��ʱ�������Ǹ�������û�г������Ż����ǻ��ȣ����ص��ϵľ������Ҳ�DZ���Ҫ�����ģ�������˵��ʱ������ʶ�����Լ���������Ƶ��ص㣬��������ʶ���ˣ��ܴ�̶���Ҳ���Ʋ��ˣ������ʵ�ʼ����У���Щ������ʱ�������Ե����ã���������������������Ҫ����һЩ������ѧ���������������������ɤ�����ࡢЦ����ģʽ�ȡ������ܶ�����Ҳ����ѧ���������ݣ�����������ҲӦ�ý���ǰ�ڵķ��������������ַ��������IJ��ص㲻ͬ��
�������������ױȶԷ�
����
�������ױȶԷ���spectrographic/voiceprint/voicegramapproach���IJ���������20����40�����������ʵ���ҵ�һ����Ҫ����---�����ǣ�Sonagraph�������������Խ������ź�ת���ɿɼ������ԣ�visiblespeech��������������ͼ��spectrogram,����ά��ͼ---������ʱ�䡢Ƶ�ʺ������Ϣ������ʽ���ֳ�����
�����������������ͼ����˵���˼������DZ���ʵ���ҵĹ���ʦL·G·Kersta,����˵���˼�����ָ�Ƽ�������ȣ���Ϊ�����������������ж�һ����������uniquefeatures��---���ۼ���spectrographicimpression������˵���˼�����������ָ��֮��������Ե�����ǰ����˵���˷������ٽṹ�ͷ���ϰ�ߵļ�ӷ�ӳ�����кܴ������ԣ��ȶ���Ҳ����Զ��Ե�5,��������ָ����Ƥ�����Ƶ��ܳƣ�����������������Ļ������ԣ����ڷ����ر��ε�ָӡ��ָ�������Ӵ����µ�ӡ����һ���������ȶԵķ�ʽ���м�����Ȼ������Ϊ����ʦ��Kersta��û�������ʶ����һ�㣬�������������ף��ƣ��ȶԷ���ȷ�ʸߴ�99%,Ҳ�мᶨ��֧����,���Ǹ÷��������ܵ��ܶ�ר�ҵ������������Ե����ۿ��Բμ����������й��ڸ÷�������ϸ���ܲ�������������������ֻ��������ͼ����������ģʽƥ�䣨pattern-matching��,���ڸ÷�����������ͼ���������Ե��Ӿ��ȶԣ�����������������������������ı仯���ԣ�����Ч�ԺͿ��ظ��Խϲ2007��IAFPA����и���ͨ�����鹫�����ʽ��Tosi�ᳫ�����ף��ƣ��ȶԷ����ԣ�“�÷�������˵���˼��������������Եأ�����֮�ǽ����Եأ��Ƚ�����ͼ�ף�����ͼ��ģʽ�뷢����������ѧ��ӳ�������ṹ֮��Ĺ�ϵȱ������ͽ��͡���Э�ῼ�ǵ��÷���ȱ����ѧ��������Ϊ����Ӧ�����ڼ���ʵ����”
����ֵ��һ����ǣ�20����70��������������ױȶԷ�����Աע�����������˵���˼�����Ҳ�к���Ҫ������,�㿪ʼ��ֻע�������Ӿ��ȶԣ���չΪ“����”��ϵķ�����aural-spectrographicapproach�����������������Ӿ��ȶ����ַ������ã��÷�����ͬ������-��ѧ����������������ģ������ɷ��϶������ױȶԷ���������˵�����Ǻܴ�Ľ������������ѧ��������û�еõ���ȫ�Ͽɣ�1979���һ�ݺ���Ӱ�����Ŀ�ѧ���棨Ҳ��Ϊ“Bolt����”����ָ����“ίԱ���Ѿ�ע�������-����������ɤ��������ʵ���������£����Դﵽ�ܸߵľ��ȡ��ڿɿ��ƵķǷ�ͥ������£�����ʿɵ͵�1-2%……���ͬʱ��ίԱ���Ѿ�ע��˿�ѧ���Ƕ��漰��ͥ�����µ�ɤ�������ھ�ȷ�ȵĹ��Ʒ���ܲ�һ�¡�Ŀǰ�й�����ʵ�ʵ�����֤��������������Խ��ٵġ������ġ�����֮�䲻��������Щʵ��������ƾ��Щ������ܶ�ʵ���о��������ġ����������µ�����ʽ��й��ơ�”
��������Ĺؼ����ڣ�������ν��“����”��ϵķ��������Ƕ�����ͼ��ģʽ���������Ե��Ӿ�ƥ���������Ե�����ӡ��֮��Ľ�ϣ����ǽ����Եķ���,���Ҳû�еõ�ѧ������ձ��Ͽɣ����������ɽ�“����”���������ױȶԷ���Ϊͬ�����ʡ�IAFPA�ڹ�������Ȼ�ر��˶Դ�����Ŀ�����ֻ�Ƿ��˶�ͼ���е����Ӿ��ȶԵķ��������Ƿ�“����”����7.���ڸ÷�������ϸ�Ľ��ܣ����Բμ�.
����ʵ���ϣ������������֣�FBI����1979��“Bolt����”������Ľ���ʮ������һֱʹ��“����”��ϵ����ױȶԷ�����������ֻ�������Ŀ�ģ�������������Ϊ֤���ڷ�ͥ��ʹ��,ͬʱ�����IJ���˽��ʵ����Ҳ����ʹ�ø÷���,�������ױȶ�֤������������������Ȼ�ǿɲɵ�,��������˾����Ըü���������ѧ�����Ļ��ɣ����ױȶԼ����Ĵ�ҵ��Ա��ԭ��������ʮ��ή����ֻ�д�Լʮ����.����Ԥ������“����”��ϵ����ױȶԷ������ڶ����ڲ������˳���ʷ��̨������������������μ����ף���
���������ڸ÷����������������“���Ƽ�������”��������һ���Ĺ����ԣ�����б�Ҫ������ǣ�Ŀǰ�ҹ����Ƽ��������ķ������ǵ�������е������ͼ�ȶԣ���������ѧ������������-��ѧ����������ͬʱ���ɷ��ϣ����ѧ�����ƣ�ѧ����ڲ�ͬ�Ĺ۵㣬���ǰ��չ��ڷ�ͥ��ѧ�ж��ѧ�Ƶ�����ϰ�ߺ��ص㣬�ҹ�ҵ�ھ�����������Ų�������“���Ƽ���”һ��.
������������ѧ������
����
������ѧ��������acousticapproach����Ҳ����ѧ����ѧ��������acoustic-phoneticapproach������ָ����������������ض�������Ԫ����ѧ���Խ��ж��������ķ���������������������������ѡ�������ء����ڡ����ɶ������ӵ��ض���������Ԫ��������Բ���������Ԫ��Ƶ�ʡ�ʱ����/���������Ϣ��ʵ���г��õ���ѧ���������кܶ࣬���Ƶ�ľ�ֵ�������λ������������Χ����ʱ��Ƶ�ֲ������������Ƶ�ʡ��켣�Ķ�̬���Լ���ʱ�����ķֲ�������������������ṩ˵���˵ĺܶ������ϵģʽ��ϸ����Ϣ������˵���˼��������dz���Ҫ����������Ƶ��ά�ȵ���Ϣ֮�⣬һ�㻹Ҫ����ɤ����ʼʱ�䣨VOT����������Ԫ����Ԫ���������ȣ���ʱ������ʱ�����������������ϵķ������ʵȡ��ڷ��������в������漰����ѧ���������ͳ�Ʒ����֪ʶ�����ҳ��������õ��ܶ��ִ������źŴ����ļ�������Ƚϳ��õ�����Ԥ�⼼����LPC���Ϳ��ٸ���Ҷ�任������FFT���������������̶���Ҫ�������˹���Ԥ��һ��������Ҫ���ѽϳ���ʱ�䡣ֵ��ע����ǣ���ѧ���������ױȶԷ�����ͬ,ǰ���ǽ���������������������“��ʽ��”ʽ���������������ͬʱ����ѧ���������ų���������ͼ�����������������ܶ�����£�����ͼ������ȡ������ѧ�������繲��壩��˵�Dz��ɻ�ȱ�ġ�
�������ģ�����-��ѧ������
����
��������˼�壬����-��ѧ��������auditory-acousticapproach��11��������������ѧ�������ַ����Ľ�ϣ�֮�����ڴ˽��䵥����������������Ϊ���ַ�����ʵ�����ܲ��ɷ֣�����Ŀǰ����“���”ʹ�õķ��������緶Χ�ڵõ��˹㷺�Ͽɡ�����ר���ᵽ��“����ѧ������”,��������ݰ������������������ױȽϺͶ����ȶ��������棬��ʵ�������ѧ���ᵽ������-��ѧ��������һ�µġ�
����������ʱΪ���������㣬��������������ѧ�����ֿ���������ʵ��������֮���ǹ����ġ������Ĺ�ϵ,���ַ����ܹ�����������������Ϣ���в��ص㣬���ܻ��������������ʵ�ʷ��������������ǽ�����С�ѭ��ʹ�õġ����������������Խ�ǿ���ܶ����ݻ������漰��������֪�����⣬��ѧ����һ�������Ϊ�������������Ľ���ṩ������֧�֣���һ���滹�����ṩ�µ�������ʵ��֤�����������κ�һ�ַ������Dz���ȡ�ģ����ַ���ͬ����Ҫ�������ɻ�ȱ,��һ���Ѿ���Ϊ���������Ƽ�����ҵ�ߵ�һ��������ʶ����ѧ�������ܵ������У����ɺܼ��������б�Ҫ����¼�����ж����������������������ݣ��ڴ˻�����ѡ����ͬ�ķ�������������ͬ��ϵ��������ͬ�����е���ͬԪ�������н�һ���ıȶԣ�������������ѧ������ǰ�ᣬ���û����������������ѡ��Ϳ��ƣ����������ϵ���ѧ��������̸��.��Ӣ��������Ϊ“���������ϵ���ͬ������ָ����������ȫ��ͬ�����ڡ����嵽����ʵ���о����˶�����ʶ���������кβ�ͬ�����ڡ���Ϊ����ĿǰΪֹ����û�з��ֱ��˶����ܸ��õı�������.”��Щ���������ϵ���ͬ����Ӧ�ó�Ϊ��ѧ�������ص������һ���棬���ۺ����ϻ��ڣ����ڶԼ����������������������ѧ�����Ľ������������ȫ��ͬ���ڶԲ������з�����ʱ�����������Ľ�����ɻ��ṩֱ�ӵ���֤��
������������Ƽ���ʵ���и÷���������ռ������λ�ģ�ŷ�����������Ĵ������������ר�Ҷ�ʹ�ø÷�����IAFPA�ľ��������ԱҲ���ڸÿ���¹���,���ڵ�����������.ֵ��ע����ǣ��÷����ȷ����������뵥���Ӿ��ȶ���ʽ�����������ļ���ӣ����“����”�����ʽ�����ױȶԷ�������ԭ�����ڸ÷�������ע�ش���������ѧ�϶��������н���ʽ�ķ�������δ�����������Ե�“��ͼ”�����ϡ�ֵ��һ����ǣ�Jessen�����������ȶԣ�forensicvoicecomparison����ʹ�õķ�����Ϊ“������”��“���������”�������棬����ΪӦ���ۺ�ʹ������������ķ��������ǽ���ʹ��“����”����ķ���.��ȷ�����Dz�Ӧ����Ϊ���ױȶԷ����������µ�“��ʽ��ʽ”����������Ĵ���ӡ��һζ���ų����е������Է����������Ͼ��ۺ����ø��ַ��������ǵ�ѡ��
�������壩˵�����Զ�ʶ��
����
�������ܹ����˵�����Զ�ʶ������automaticspeakerrecognition�������ݵ�20����60��������Ǹü��������Ƽ��������Ӧ��ȴֻ��10�����ҵ�ʱ�䡣�÷�����ͬ�ڴ�ͳ���������˹�ʵʩ����ѧ�������������Զ���ɵģ������ԭ���ǣ��������źŴ�������ʦ���һ���ij�����㷨����������˵���˵���������������ȡ��Ȼ�����������������ģ�ͣ����о�����㣬���ȷ��������Ϊ�ӽ���һ����֪˵���˵�����ģ�͡�Ŀǰ����õ���ѧ������������������ϵ����MFCC��������Ԥ���ϵ����LPCC������õ�����ģ���Ǹ�˹���ģ�ͣ�GMM����˵�����Զ�ʶ�����ŵ����Զ����̶ȸߣ���Ҫ���ٵ��˹���Ԥ��һ�������Ƚ�ʡʱʡ����ȱ���Ǿ����������������ѧ�Ϻ��ѵõ����ͣ����Ҹ�Ϊ��Ҫ���ǣ����ܽ������÷����Ѿ�ȡ���˺ܴ���������ٹ��ҵ���鲿���Ѿ�������������������������Ǹü������ʵ�ʰ�������ȷʶ���ʻ����Ǻܸߣ�Զû�дﵽ����Ϊ��ͥ�ṩ�ɿ�֤�ݵij̶ȣ�����Ŀǰ��������������˵�����Զ�ʶ������շ�չ���ƻ�����Ҫ����������ר�ҷ������ϣ��γɰ��Զ��ۺ�ʶ��ķ�����
�������������ַ����ڼ����е�Ӧ��
����
���������Gold��Frenchͨ����5����13�����ҵ�36λ���Ƽ���ר�ҽ�����һ���й�˵���˼����Ĺ��ʵ���,���鷢�֣����ͼ����������ԣ���2�˵���ʹ��������������Լռ6%����1�˵���ʹ����ѧ��������Լռ3%����25��ʹ������-��ѧ��������Լռ71%����7��ʹ��˵�����Զ�ʶ���˹������ķ�����ռ20%����û���˵���ʹ��˵�����Զ�ʶ��ķ�����ռ0%��.�����Կ��Կ�����Ŀǰ����-��ѧ�����������緶Χ��ʹ����㷺�ķ���������Gold��French�ڵ����в�û�н����ױȶԷ�������Ϊ�����ѡ����Dz�����ζ�Ÿ÷�����ʵ�����Ѿ���ʧ�ˣ�ֻ�����÷������Ѳ��Ǽ������������������������䵮�����������ݱ�����֪���ҹ���½������չ���Ƽ���ҵ��ļ���������Ҫʹ������-��ѧ��������ӵ���Զ�ʶ��ϵͳ�ļ��������ཫ��ʶ������Ϊ�ο�ʹ�ã���������������Ҳ��ʹ��˵�����Զ�ʶ������Ϊ��Ҫ����������16,Ŀǰȱ�����Ƶ�ȷͳ�ơ�
���������������Ƽ�������ı�����ʽ
����
����Gold��French������Ҳ�Բ�ͬ����/ר�ҵ����Ƽ�������ľ��������ʽ�����˵��飬������ֲ�ͬ����/ר�ҵı���������ںܴ�����ؿ�ѧ����ʹ�����Ĺ۵�Ҳ�ܲ�һ�¡����鷢��13�����ҵ�36λר��ʹ�õ����������ʽ��Ҫ������5�֣���Ԫ�о���ʽ��binarydecision��������Ŀ����Եȼ���ʽ��classicalprobabilityscale����������Ȼ����ʽ��numericalLR�������ֱ�����Ȼ����ʽ��verbalLR����Ӣ������������ʽ��UKPositionStatement��������5�����������ʽ�ֱ��У��������й��������Ĵ����ǡ��µ������������¹�����������������䡢Ӣ���������������Ĵ����ǡ��¹�����������������������������������ͣ��¹����������������䡢Ӣ�������������ҵĴ�ҵ��Ա��ʹ�á��������������ʽ�����ļ�������������أ���Ҳ����һһ��Ӧ��������ʹ������-��ѧ����������25λר���У�����10��ʹ�þ���Ŀ����Եȼ�������10��ʹ��Ӣ������������ʽ��2��ʹ�ö�Ԫ�о���ʽ��2��ʹ�����ֱ���LR��ʽ��1��ʹ������LR��ʽ��ͬʱʹ�þ�������Եȼ�������14λר���У���1��ʹ��������������10��ʹ������-��ѧ��������3��ʹ���Զ�ʶ����˹������ķ���������Ը������������ʽ���н��ܣ�
������һ����Ԫ�о���ʽ
������Ԫ�о������ڱ������ʱֻ������ѡ��Ҫô�����϶���Ҫô���Է�û���м�ѡ�
��������������Ŀ����Եȼ�������ʽ
��������ר����������-��ѧ����������������������Ҳ���ٲ���ר�ҵ���ʹ���������������Զ�ʶ����˹������ķ��������м��飬ͨ���Ƚϼ�ĺ������������������ֱ�������Ϻ���ѧ�϶���Щ��������֮���������/�����Խ����жϣ�������������������������Ͻ����ۺ��������ڳ�ֿ��������������������ƵĻ����ϣ��ó�����ר�ҶԼ�����������������Ƿ���ͬһ����˵��ȷ�ų̶ȡ�ͨ������ȷ�ų̶��ɲ�ͬ�ȼ��Ŀ����������������ܲ�ͬ����/ר�һ��ֵȼ����������ܲ�ͬ����5����11�����ȣ�������з�Ҳ�в��죬���ǻ���ԭ����һ����.����侯����Ƽ�ʹ��9���ȼ��ķ�����ϵ:
����+4���֧�ּ���ӽ�ȷ����supportthehypothesiswithnearcertainty��
����+3�����ǿ��֧�ּ��裨stronglysupportthehypothesis��
����+2���֧�ּ��裨supportthehypothesis��
����+1�����ij�̶ֳ���֧�ּ��裨supportthehypothesistosomedegree��
����0�����inconclusive��
����-1�����ij�̶ֳ��ϲ�֧�ּ��裨contradictthehypothesistosomedegree��
����-2�����֧�ּ��裨contradictthehypothesis��
����-3�����ǿ�ز�֧�ּ��裨stronglycontradictthehypothesis��
����-4�����֧�ּ���ӽ�ȷ����contradictthehypothesiswithnearcertainty��
���������“����”��ָ�������������������ͬһ����˵��
�����¹������������ʹֻ����е�˽��ר�ҡ������ļ���ר��Ҳ������ͬ��9��������ϵ�����������7��������ϵ;������“����”��Ϸ������м�����ר���еĽ������Ϊ7��,�е������5��������ϵ;�й���½������5���ķ�����ϵ;�������������ҲӦ���������ġ�
������������Ȼ�ȣ�LR����ʽ
����
���������Ƽ��������У�LR��ӳ�˶��϶�˵���˵����������Լ���---�����裨�����������������ͬԴ������ͬһ����˵���ͱ绤���裨�������������������ͬԴ�����Dz�ͬ����˵��---֮��Ĺ�ϵ������ֵ�ϵ���ͬԴ�Ͳ�ͬԴ���ֿ����Եı�ֵ������Ҳ��������������֮��������ԣ�simi-larity�����ձ��ԣ�typicality���ı�ֵ����ʾ����������ָ����������������������DZȽϵ�����ά�������ƻ�ͬ�ij̶��ж����Խ���ƣ�����Դ��ͬһ˵���˵Ŀ����Ծ�Խ��ͬʱ����ѡ���������������ˣ���һ��Ⱥ�壬�簴���Ի��Ա���з��ࣩ��˵���ص��п��ܱȽϳ�����Ҳ���ܱȽϺ����������ձ���Խ�ͣ�����֤�ݵ�֤������Խǿ��
����
��������ʽ1��
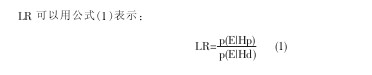
����
�����ù�ʽ�У�p��ʾ���ʣ�probability����E��ʾ֤�ݣ�evidence����Hp��ʾ�����裨prosecutionhypoth-esis����Hd��ʾ�绤���裨defensehypothesis��������������ȷʱ�����ӱ�ʾ��ȡ��֪����֤��E�ĸ��ʣ����绤������ȷʱ����ĸ��ʾ��ȡ��֤ͬ�ݵĸ��ʡ����LR����1,˵������Ը����֤��֧�ּ������������������ͬһ����˵����֮�����LRС��1,˵������Ը����֤��֧�ֶ����Dz�ͬ����˵�����Ӵ����ȶԵ������Բ��棬��ĸ������ձ��Բ��棬�������������������������Ƴ̶ȸߣ��DZ���������ͬһ����˵�Ŀ�����Ҳ��Խϴ�֮��Ȼ�����ձ��Խϸ�ʱ�����������������˵���˵Ŀ�����Ҳ�ͻ���Խϴ�֮�����ձ��Խϵ�ʱ����������������˵�������⣬����˵�����永�Ŀ�����Ҳ��Խ�С�����LR����1,˵�������������������Դ��ͬһ˵���˺Ͳ�ͬ˵���˵Ŀ�������һ�£���ʱ������֤�ݾ��������ˡ�
����LR������һ���ŵ��ǿ��Զ������ļ�ֵ�������������ۺϸ���������LR��ֵ�Ļ����ϣ���������֤�����ȵ�����ֵ������LR��ֵ��ˣ�������ȫ���ֵ���ʽ���ֳ���������LR��ʽ��������LR��������ʽ���ܲ��ܱ���ͥ��������⣬��ѧ�������LR��Ӧ�����ֻ��ּ���ʽ�����ֱ���LR��ʽ��,�����ǽ�LR��ֵȡ����������ɶ�Ӧ�Ľ�С����������ֵ������1.�����ڷ�ͥ�ϲ��ú�����ʽ��LR��ϵ���б�����Ŀǰû��һ���Ե����.
��������LR��ϵ�ǻ��ڱ�Ҷ˹���ۣ�BaysTheorem���ķ������ڴ��б�Ҫ�Ա�Ҷ˹��������Ҫ���ܡ�
������Ҷ˹���ۿ����ù�ʽ��2�����б�ʾ��
��������ʽ2��

�������Կ�����������������������LR�ij˻���������������ϰ���������֤��֮��õ��ĸ��ʣ���ʵ��������������ȷ�ų̶ȣ�������������ʾ��ʵ�������ڼ���ר��չʾ��LR��ʽ���ֵ�����֤�ݣ�����֤��Ҳһ����֮ǰ���������������Լ���֮�������ȷ�ų̶ȡ�Ҫ�õ�������ʣ�����֪��������ʣ���������ʵĻ�ȡ���ܻ��ܵ�����������֤�ݻ����Ӱ�죬��DNA��ָ�ơ�֤��֤�Եȡ���Ȼ���ڱ�Ҷ˹���ۿ���£����Ƽ���ר��û������Ҳ��Ӧ�û�ȡ������ʣ��̶�Ҳ���Ժ�������������ۡ�����LR��ϵ������֤�������ϵ���ϸ���ܣ����Բο�.
��������1��

�������ģ�Ӣ������������ʽ
����Ӣ������������ʽ��ָ��Ӣ��ר��PeterFrench��2005���IAFPA������������Լ�˴�ѧ�ͽ��Ŵ�ѧ�����Ƽ���ר�����ۣ������2007���γɵ�һ�ݹ�������֤�������Ӣ����ͥ�ϱ�����������������һ��֮�⣬Ӣ�����е����Ƽ���ר�Ҷ�ǩ����ʾ֧�֣��������������ڿ��������ϲ�ѯ�������ո���ʽ��ר����Ҫ������������жϣ�һ���ԣ�consistency���Ͷ����ԣ�distinctiveness���������жϼ������������������һ���ԣ�һ������ָ�����������������������ͬһ˵���˷����Ƿ���һ�µģ�consistent������ϵģ�compatible����һ�����ж����������ֿ��ܵ���ʽ��
����һ�£�consistent��
������һ�£�notconsistent��
�������ۣ�nodecision��
����1.�����һ���Է���ó�����“һ��”�Ľ����ר�һ�Ҫ��һ�������������Ķ����Խ��������������������Ϊ����5���ȼ���
�����������⣨exceptionallydistinctive��---����˵����ͬʱ������Щ������ϵĿ������Ǽ���С�ġ�
�����߶����⣨highlydistinctive��
�������⣨distinctive��
�����ʶ����⣨moderatelydistinctive��
���������⣨notdistinctive��
������������һ��������������������ж���֤�ݣ�������Ƶ��أ���ʾ��֪˵���˳��ֲ�������̸���ıռ��ȶԣ�closedsetcomparison���İ����������������֮��IJ���㹻���ԣ��������������϶��Ľ��ۡ�
����2.�����һ���Է���ó�����“��һ��”�Ľ����ר�Ҽȿ��Եó���ȷ���ų�����Ҳ���Բ��ÿ����Եȼ�����ʽ���б�����
�������壩�й���½���е���ʽ
����
����Ŀǰ�й���½���Ƽ������Ϊ�����Եȼ�������ʽ�������Եȼ�Ϊ5�����ù۵����ڶ����º������ж��������֡��������������Ƽ���ʵʩ���������������ǹ��ڴ�������Ϊ��ϸ�Ľ��ܣ�һ���ǹ�������֤���������ƶ���“����ͬһ�϶�������IFSC11-01-01-2010��”���³ƹ�����������,��һ����˾����˾�����������ֹ����ġ�¼�����ϼ����淶��SF/ZJD0301001-2010��������3���֡�����ͬһ�Լ����淶�������³�˾�����淶��.�ݱ�����֪���ҹ���½�����Ĺ��������Ͱ�ȫ���������Ŀ�չ���Ƽ���ҵ��ļ������������϶������˹��������������������Ŀ�չ���Ƽ���ҵ��ļ���������������˾�����淶����������������˾�����淶���ң��������Ƽ�����������ֳ�5���ȼ��������˾���Ļ��ֱ���
����+2 �϶�ͬһ �϶�ͬһ
����+1�����϶�ͬһ ����ͬһ
����0�������ж� �Ƿ�ͬһ
����-1�����ͬһ ����ͬһ
����-2��ͬһ ��ͬһ
������Ȼ����з�������ⲿ�ֹ��Ҳ��õĿ����Եȼ�����������ͬ�����ں��ǻ���һ�µġ�ֵ��ע����ǣ��������ַ����ھ���ȼ��Ļ��ֱ���������ͬ�������������Եȼ���������ȷ������“����”Ҫ�����“�϶�ͬһ”��Ҫ���ǣ�“�˽���Ҫ���ġ������пɹ��ȶԵ�������10�����ϣ�ÿ��������3��������Ч����壻���пɹ��ȶ����ڵ����������ʳ���90%.���߿ɹ��ȶԵ�������6�����ϣ�ÿ��������4��������Ч����壬���������ʳ���95%.������������αװ�������´˽��ۡ�”���֮�£�˾�����淶��������Ա�����ɶȽϴ�û��Ӳ�Ե�“����”Ҫ����“�϶�ͬһ”Ϊ����������������������������㹻�ķ����������ҷ��������ļ�ֵ��ַ�ӳ��ͬһ�˵ķ����ص㣻û�б��ʵIJ���������ͬʱ�����仯�����ܵõ������Ľ��͡�
�����ġ��Ը������������ʽ������
����
������һ����Ԫ�о���ʽ
����
����������˵����˵���˽��м�������������������---�϶��������ʵ�ʰ참�У�������Ա���ܵ����������ľ��ޣ����־�����һ����������˵�������������ı仯���ϣ���һ�������������������ŵ�����绰������������Ҳ�����������������½�����ʱ����ʹ������/����ѧ�������������У�ͬʱ�����������ʱ������̵ܶĻ�������Ҳ���ܳ������˵���˵������ص㡣��ˣ����������ڶ�����ԣ�����������ֻ���������������϶���Ľ����Dz��۵ģ�ʵ���м����˳�����������ȼ��Ŀ������жϡ�Gold��French�ڵ������ᵽ�������й���ѧ�����ٻ�������ʹ�����ֶ�Ԫ�о���ʽ������������ʽ�����й���½���Ƽ�����ҵ��Ա������ѡ�����ǰ��17����
��������������Ŀ����Եȼ�������ʽ
����
�������ų��˶�Ԫ�о���ʽ֮�������ƺ���Ȼת������Եȼ�������ʽ�����������������������ָ��ֿ����Եȼ�����ʽ�����ŵ�����ԣ������Ƕ�ר�Ҷ��ԣ����ǶԷ��١������ź���ͨ������˵���Ǻ���������ģ�ͬʱҲ�������ϴ�������ң����ۺ���˾����ϵ��������������ר�����㷺ʹ�á������������������ʽ�ľ������ר�Ҷ�ʹ������-��ѧ���������м���������ר��Ҳ��ʹ�����������ģ����������˹������ijɷ֡�
�������ܸ���ʽ���㷺ʹ�ã�������������û���κ�覴ã��䲻��֮��ͻ���������������棺�����Խ�ǿ�����ϴ���ȱ�ݡ�
������һ������ʽ�н�ǿ�������ԡ����ȣ������������жԸ����������������ۺܶ�ǻ������������۸�֪����ʹ�����ܹ�רҵѵ��������ר��֮��Ҳ�����һ���IJ�ȷ���ԡ�����������֮������ƻ�����̶�����������ʽ���������̶�����ͳ�Ʒ�������һ���dz����ѵ����飬����˵�����Dz����ܵģ���Ϊ��ͬ�����ˣ���ͨ��Ҳһ������ͬһ�����ĸ�֪δ����ȫ��ͬ.��Σ��ڶԶ�����������ַ����ķ����������Ȩ�غ��ۺϷ���ʱ��������Ҳ�Dz��ɱ���ġ�ͨ�����ĵķ���������֪��������������ѧ�����ศ��ɣ�ȱһ���ɣ����Dz�����˵�����ַ�������һ����ó����һ�µĽ����������߳���ì��Ӧ�����ȡ�ͬ���������ܻ�����ڽ�������������������˹��������Զ�ʶ�����������һ�½��������С��Դˣ����dz����������е�����ѧ/����ѧ������Ϊ���б����������ķ��ϺͲ���̶������DZ��ʵ�/�DZ��ʵ��жϣ���ʵ�����Ƿ�“����”���ж���Ȼ���������еĿۡ��ٴΣ������Եȼ����ֵ��������������������棺��һ���ȼ����ֵľ���������ͳһ����ͬ����/ר��֮��ʹ�õ�������ʽ������ͬ��ѡ���Ŀ����Ա�������ר���Լ�������;��������ͬ�ȼ�֮��Ļ���û�о���Ľ��ޣ��ܶ�����£���������ĵȼ�������Ҫȡ����ר�Ҷ���ѡ����������������������������ר������γɵIJ�ͬ������ȷ������������IJ�ͬ�ȼ��������еĿ����Գ̶Ȼ�����“��”���ݿ�ѭ��������IAI��¼��֤��ίԱ�ṫ���ı�����ʽ����ϸ���Ļ��ֱ�������δ���еó��˱��Ŀ�ѧ��֤.
����������۳�����ΪLR��ϵӵ����������������Եȼ�������ʽ����Ҫ�۵�֮һ����ʵ�������б�Ҫ���������������ʽ�������Ժͼ������������������ֿ����������ᵽ�ij���˵�����Զ�ʶ��֮�������������һ���Ǿ��������Եģ�����Broeders���ԣ�“ֻҪ��ȷ�÷��������۵ģ��������۵��жϾͲ�Ӧ���ܵ��𱸣�ԭ���������������۵ġ��ؼ������ⲻ��ר�ҵó��Ľ��������۵Ļ��ǿ۵ģ����Ǹ÷����Ƿ���š�”�����������Բ��DZ�Ȼ��ζ�ŷ����Dz�ȷ�ģ�����ʵ���д�����������ԣ���ͬ����ḻ�ļ���ר�ҷ���ͬһ���ϵõ��ļ��������������ͬ�ġ���ErikssonΪ������������ר�ҽ��к���������ʱ�ͺ��ٳ��ֽ��۲�һ�µ����.
�����ڶ������ϴ���ȱ���ǿ����Եȼ�������ʽ��������������һ��ȱ�㡣�����Եȼ�������ʽ��һ���������ü���ר���ص������������֮��������ԣ��Ͳ����ԣ���Ȼ��������֮����������������ο������˿��еķֲ�������������ᵽ���ձ��ԣ�ȴ��ע̫��.������һЩ����ר�����ձ����һ����⣬����ΪֻҪȷ����������֮����н�ǿ�������ԣ��Ϳ��������϶����,�������һЩ�����˿��ܻ�˵“��ֻ�DZ�Ҫ��Լ�������������������бȽϣ���û�б�Ҫ��Ҫ�Ѽ�������������˵����������бȽϣ���˼�������������˿��������˵������Ƿ��������صġ�”ʵ���ϣ����ֻ��ע����֮��ķ��ϳ̶ȣ������ԣ������Ը����������������ο��˿��еķֲ��Ļ������DZ��ɱ���س������ϵĴ�������÷����������˿ڷֲ��зdz��������ɴ˵ó��϶������ȷ�Ի�Ƚϸߣ�����÷��������ڣ����˱�����������ģ������˵�������Ҳ�dz��ձ�Ļ����ٵó��϶�����ij����ʾͻ�ܸߡ�����LR��ʽ��ӳ���϶�˵���˵����������Լ��裬�����κ�һ�����裬���������ϳ�����
������������Ȼ�ȣ�LR����ʽ
����
��������ھ���Ŀ����Եȼ������������ԣ�LR��ϵ������û��ȱ�ݣ��÷���Ҫ����˵���˼�����ͬʱ�������������Լ��������ʹ������������ȷ�ġ�����ʽ���Լ�����������������Ƿ���ͬһ����˵�������Եĺ����Ե��жϣ���ֻ�Ƕ�����֤�ݵ����Ƚ�����������ʹ��������“��”����˵����������Ч���ͼ����������ԣ����ܱ������ר��“����”��ʵ�������������Ľ���24.����LR��ϵ֧�����ǹ����ܹ��ﵽ��ЩĿ�꣬�ǽ������Ƽ�������ľ�ɾͣ�Ȼ��������ϵ�Ƿ�������֧�������������ѧ����ɿ�����ʽ�أ���ʵ���ܲ�����ˣ�ԭ����Ҫ���������㣺
������һ��LR��ϵ֧����ʹ�õļ����������������ԣ������¡�����ǿ�����ǣ��κ����������ʽ������ͬ�ھ���ļ���������LR��ʽҲ�����⣬���۸���ʽ�Ƿ�ȷ�ɿ���Ҫ�ȴ��������ݵķ�������������Morrison��Morrison���ڽ��ܸ��ּ��������Ļ����ϣ�������LR��ϵ�������Խ��й�����ϸ�����ۣ�������Ϊ��ѧ�����������Զ�ʶ��ķ��������ʺ�LR��ϵ���෴������������������������-��ѧ�������������ױȶԷ��������ǻ��ھ�����������жϣ��Ӷ���Ϊ��Щ������LR��ϵ�������ݡ�LR��ϵ��֧����֮����������ѧ����������ԭ��������ѧ�����ܹ��ṩ“�۵�”�������ݣ�����������ͳ�Ƽ���IJ��֣�Ȼ����ѧ������������ȫ�ۡ��������������ڼ���ʵ������ѧ���������������ǻ����ġ������ģ���ǿ��һ�£��������ר�Ҷ����Ӧ�ý�������������ѧ�������ʹ�ã������ǵ���ʹ���κ�һ�ַ������������ͨ�������������ּ���������������������ֳ������Եķ��Բ��죬���������ų���������ͬһ����˵����û�н�һ�������ı�Ҫ�ˣ������ĺ�������˵���˵�����״̬����ϴ����ŭ�Ĵ���˵������������������������֮��������ò��߿ɱ��ԣ�Ҳ����˵����ѧ��������ѡ��ķ������������������������б��ж�Ϊ���������ͬ�����������ֻ������������������ѧ������������ȫ�۵ģ�ԭ��ܼ���Ϊ��LR��ϵ���ų���������������۵ģ���������LR֧������ʶ����������������ѧ����֮������й�ϵ25,֮�����ų�����������ԭ���������ںܶ����������Ƕ��Եģ�������LR��ϵҪ���������뱻������Ҫ��ͬʱ����ʹ����ѧ�����У�������ʹ�õ�������ͬ��ͬ���������㷨�����ò�ͬ�ȣ��������һ������������仰˵��������Ա����ѧ����ʱ����������ѡ����һ���������ԣ��̶�Ҳ��Ӱ�쵽�����“����”.�����Ƽ�������LR��ʽ����ͬʱҲ����ҪӦ����˵�����Զ�ʶ���ϵģ�����Ĺؼ��ǣ�����˵����ʶ����ȡ���˺ܴ�Ľ��������������ң����������ͷ�����Ҳ�õ����Ͽɣ����ǵ�ĿǰΪֹ���������㷺��ȷ��Ӧ�õ�����ʵ����ȥ����ʶ������Զ�ﲻ��Ϊ��ͥ�ṩ�ɿ�֤�ݵij̶ȡ��ɴ˿ɼ�����ʵ�ʼ����У�LR��ʽ֧����ʹ�õļ������������£�������Եȼ�������ʽ��ӵ������ȣ�ǰ�߶������������ų⣬��Ȼ���¼��������ȷ�Ŀ��������ӡ���ǰ��������Ŀǰ���ڶ���������У�����-��ѧ����������Ȼռ��������λ����Щ��Ϊ�������Ա���Ϊ���п����Եġ����ܵġ������Ķ���LR��������֮ǰ��������ʱ����о�����Ĺ۵��Dz���ʵ�ģ�������˵�÷����Ŀɿ�����.
�����ڶ����ڶ������������������������ѱ�����������һ��LR֧���ߵ��о��ɹ��ͻᷢ�֣����о���Ҫ��������ѧ�����еĹ����Ƶ�ʺ켣�ȷ��棬���������������ۼ����������������������ֱȽ���ϸ���о�����������������Ҫ�����ܹ���������������French�ȸ�����ȷ�о������Ƽ����г��õ�11�������������ԣ���Щ�����ĺ��Ƿ�Χ�ܹ㣬������ѧ�ġ�����ѧ��Ҳ����������ѧ��������ԶԶ�����˽��Թ����ķ������������Ĺؼ������еĺܶ������Ǻ��Ѷ���ʵʩ����ͳ�Ƶġ���ʵ�ʼ����У�����ר�ұ���Ҫ���ǵ��ͼ���ϵĸ������棬����ȫ���ϵͳ�ķ����������Ѿ����о����ֲ���Ԫ���Ĺ����ģʽ�߱���ǿ�Ļ����������������Ⲣ����ζ�ż�����Ա�Ϳ��Ժ��������������������Ϊ���������ܶ������ķ�����������Ǿ����Եģ����Ҳ�һ����Թ����ķ������һ��.
������������زο��˿�ͳ������ȱ�����������ʹ���й��������Ե��˿�ͳ�����ݣ��Ƕ�LR���ձ��Խ��������ı�Ҫǰ�ᡣȻ����Ŀǰ�����������йصIJο��˿�����ȴ�Dz�������ʵ���Դ��м������������ֵ�ô��ע�⣺���ȣ�����˿���ζ��壿LR֧���߳�������һ�����ȵ���ʵ�������⣬��Ϊ��صIJο��˿�Ӧ�������������һ����������Ҫ����˵���˵��Ա���˵���ԡ����Ե����ؽ����ο����ݿ⣬���ڲο��˿���ȡ��������Ϊ�˵����⣬����ȡ����Ҫ��ľ���.���ԭ���Ե�˵�������Ժܲ��ȻRose�Ƽ���һ���ռ��ο����ݵķ��������ü���ר���ǽ����ǵIJο��˿����ݻ㼯��һ�𣬴Ӷ�����ÿ�����ⰸ������Ҫ����Ȼ���ܻ���Ҫ��¼����˵���˵����ϡ����ڲ�ͬר�ҵ�ѡ��������ݷ�Χ���ѱ���һ�£�������ַ����������ף����������Ժ�ǿ�����Ҵӿ����ԵĽǶȽ������ַ����ܹ����ǵ����Ա�����������ֻ�зdz�����һ���֣��������ڶԻ����������������ḻ�����ӵ���Ϣ���Լ�������н��������Ŀ����ԡ�����Rose����ֻ֤�Ƕ�30��˵���˵����ݽ����˷�������˵���˽�“yes”��������ȡԪ�������켣�ĽǶ�˵�����ռ����ݵĿ����ԣ���δ�ۼ�������������Σ���Ϊ��Ҫ�����������ݿ���Ӧ�ð�����Щ������������Щ���ص��������Ը���ȷ�ľ��пɲ����ԵĴ𰸡������������������п����漰�����������Ƿ�Χ�ܹ㣬ԶԶ�����˹���������ķ��룬��ͼ�ռ��ͷ����㹻����ܹ�����ȫ��������֣������IJο����ݻ����Dz����ܵġ��ռ����ݹ�����ͬʱ���뿼�ǵ�һ��������¼����ʽ�����ŵ����⣩��ʵ���е�¼����ʽ�dz��࣬����˷硢¼���ʡ�¼������ֱ��¼���ģ�Ҳ�й̶��绰���ֻ���GSM��CDMA��3G��С��ͨ����IP����绰֮�䲻ͬ���ͨ��¼���ģ��Ժ�����µ���ʽ����������е���������ʽ�����������������ο�����ʱ�ܹ���������ȫ��¼����ʽ������˵���˵�˵��״̬������˵�������̺����Ƶȣ��ͽ�����������ض�������Կ��ơ��ٴΣ������й��������Ի����dz����ӣ������ڶ����ԡ����Ժʹη��ԵĹ��ң�Ҫ�뽨��ȫ��IJο��˿������Ƿdz����ѵ�,ͬʱ�������ʽ��Ƿdz�����������ء������Ҫ���ǵ��Dzο����ݵ�“����”���⣬���ɷ������е����Ժͷ��Զ����ڲ��ϱ仯֮�У�����κβο����ݾ��������Զ��ԣ���“������”�������ģ����������������ʱ�IJο����ݽ��бȽϵĻ������ɻ�����ܴ�ķ��գ����ڼ�������е�ijһ�ؼ�������˵���ο����ݿ��е����ݿ��ܲ�һ�����г�ֵĴ�����.���������DZ�Ҫ�ģ���Ϊ�ڶ����ض����˵���˵�����ѧ/����ѧ����ģʽ��������Ӱ�죬������㼯���ܹ����������������������Ǹ���Ӱ�����صĺ��ʵIJο��˿�ͳ�������ǿ��еģ���ʹ�Ǵӳ�Զ�ĽǶȿ���
�������ϣ�����LR��ϵ������û�д������������Ƽ���ר��һ��������������������ʹ��LR��ȷ���㲢����ʵ������“���ھ�����������������ԣ���ȱ����Ӧ�IJο��˿����ݣ����������ֱ�ʾ����Ȼ��ֻ��Է����ṩ��ٵ���������ʵ���Ϸ�������������������Ϊ���ж�”.������ˣ�����Ҳ������ȫ�ų�LR��ϵ��������Ҷ˹ԭ���������ִ�˼���Ѿ��õ��˹㷺�Ͽɣ�����DNA֤���еõ��˺ܺõ�Ӧ�ã�Ȼ��������ģʽǿ�Ӹ��������Ƽ������ڵ��������еķ�ͥ��ѧ֤���Ƿ����������ֵ�ÿ��ǵ����⣬����ܶ�ר���ᵽ�ģ��������Ƽ������ԣ���Ҷ˹ԭ���ļ�ֵ����������ֱ��Ӧ�ã������ڸ�������Ա�ṩһ�����õĸ����Կ�ܣ�ʹ��ר�Һ���ʵ������֮������������.
�����������Ƽ���ר����˵�����ܵ�ȷӦ����ʹ������������ܵķ���Ŭ���ܽ�����������Ҳ����Ҫ֪��ʲô����ʵ�ģ�ʲô�Dz���ʵ�ģ������Ҳ�Ǵ�ʹӢ���������������Ķ���֮һ��
�������ģ�Ӣ������������ʽ
����
������Ӣ������������ʽ����֮ǰ��ͨ������£���Ӣ���ķ�����ϵ�У�����ѧ�ҳ������羭��Ŀ����Եȼ���������������ר�������֮����ʵ������ת�䣬��Ҫ���ܱ�Ҷ˹���ۣ�����LR��ϵ����Ӱ�죬Ӣ����ר���Dz�����ʶ������Ŀ����Եȼ�������ʽ�д��ڵ���ȱ��---ֻ���ǵ����������Լ����е�һ�����裬ͬʱҲ��ʶ����LR�����д��ڵ�������˷�����ʵ���⣨����Ȼ����ʽ���֣����̶��ڹ㷺���۵Ļ����������Ӣ������������ʽ��ֵ�ÿ϶����ǣ�����ʽ�����˱�Ҷ˹���۵���Ҫ˼�룬Ҫ�������ͬʱ�����϶�˵���˹����е����������Լ��裬Ȼ������French���ڸ�Rose��Morrison�Ļ�Ӧ�б����ģ�“�ļ�������Ŀ��Ϊ�������Ѽ���ר����Ҫ�жϼ�����������������������Ķ����ԣ��൱���ձ��ԣ��������ζ��Ҫ�������˽��бȽϣ���Ȼ���ֱȽ��Ƿ���ʽ�ģ���ͨ��������Ա�ľ����һ�������ѧ֪ʶ���еģ���������ʽ�ġ������ġ�”���ѿ���������һ�����е��������ڼ��м�����������Ҫ������-��ѧ���������Ļ������ں��˱�Ҷ˹ԭ���Ļ���˼���������������������ʽ���ɲ��ɱ���Ĵ���һ���������ԣ�����ͬ�ڶ�������LR��ϵ���ɴˣ�Ҳ�ܵ���LR��ϵ֧���ߵ�������
������һ������ʽ��������---һ���ԺͶ�����---�Ļ����൱�����ȼ���LR��ϵ�е������Ժ��ձ��ԣ����߲��Dz���ƽ�еģ�������������ģ������Է���ֻ�����ж�Ϊ“һ��”�Ļ������ٽ��У��������ߵĻ��ֵȼ���Ҳ����ͬ��ǰ�߷�Ϊ�������������Ϊ�弶��������Ҳ��ֱ����ء��Դˣ�Rose��Morrison����˵�÷���ʵ�������������������������������Դ��ͬһ˵���˻��Dz�ͬ˵���˵Ŀ��̶ܳ��Ƿ���ȡ�
�����ڶ����ܷ��������Ե��϶�/����������ձ�Ҷ˹ԭ���Ĺ涨���������Ƽ���ר����˵���κξ��Կ϶��ͷ��ǻ��ں�����ʵģ������϶��Ǵ���ģ���Ϊ������ʲ�����֪���Դˣ�LR��ϵ֧���ߺ�Ӣ������������ʽӵ�����ǻ���ָ��Է�������������������������Ӣ������������ʽ��̸��“��һ��”�Ľ��ʱ����Ϊ“������֮�䲻һ��ʱ���ó������Dz�ͬ����˵���ж���������û��ȱ�ݵġ�”�Դˣ���ӵ���ߺ�����������������������ģ�����ǿ������������ʵ��������Ǻ����ģ�ͬʱָ������������������Ҳ����ͬ����ȱ��,��“��Ȼ�������������ض�����£������ȶ�Ҳ���Եó���ȷ���ų����ۣ���һ����С��ͯ�����������ܲ������ͳ������Խϵ͵Ĺ���壬������������£��������������������Բ�ͬ�������������ר����ѯ�����İ��������Dz����ܵġ�”�Դ������ķ��������LR��ϵ֧�����Լ�Ҳ�ó���һ�����Եģ���ȷ�ģ����ۣ�������ͨ���ó�һ��������֧��˵������һ���������Զ���һ����ͯ�ļ���.Ӣ������������ʽ�л��涨�˱ռ��������������������“�����ְ����У��ȶ�����ͱ�����ĸ���˵��ʲô������ʱ�������������֮��IJ���㹻���ԣ�������Ϊ�������������϶����жϡ�”.Rose��Morrison������������ȻΥ����Ҷ˹ԭ��������ΪӦ�ý��˱ռ����ͬ����Ϊ���������м��顣��ʵ����ʵ���참�г��������ƶ�ijЩ�����DZ���������˵������������ͼ��˳�����ļ���Ҫ���Ƕ�һ�������е�“����/Ů��/����ΪXX’��/��绰��/������”�����͵�˵���˵������Dz���������˵�����м�������������ǶԻ�����ʽ������ר����ѡ����������ض�����Ƭ�Σ���ʱ���ò����صģ���Ӧ���ģ�“Ů��/����/����ΪYY’��/�ӵ绰��/�Ӿ���”˵���˵������ų������������ʵ���Ͼ����ƶ�ijЩ������һ���ˣ������ĸ�����ĸ����أ�˵�ģ������������������˵�ģ������ƶ��ľ����Ͽ����ų��DZ���ģ��������ר�ҽ����ʴӣ�����Ӧ�ö���Щ�������з�����28?�ܲ�������ʵ�����߳䵱�ͼ��˵Ľ�ɫ����ָ����ijһ�仰���м����ɣ����ڼ�������а�������Ի��˵�����������˿�����һ��������������Ҫ�����е�“��ͬ”�������з��࣬Ȼ���ٸ��ݼ���Ҫ������е�һ����������������������Ƭ�Σ����н�һ���ķ����������ж������ˣ��ռ������Կ϶��ͷ�˼�롣������Ƕȿ���Ӣ������������ʽ�й涨�ıռ���������������Ҳ��������
����������û�н����Զ�����������ۺ����۵����⡣��������Ҫʹ�ö��������һ����������ʵ������������ָ��һ�»���˵�������������“�Ÿ��������ж�Ϊһ�£���һ���������ж�Ϊ��һ��ʱ������δ�����”���������������Ӣ������������ʽ�;���Ŀ����Եȼ�������ʽ�ƺ���û�и����ܺõ�˵����һ��������ǰ������е�����ѧ/����ѧģ�ͽ��м��飬������֮������ƻ�����Ƿ���Եõ��������ͣ�Ȼ�����ֽ������ɿ��ܻ��ڲ�ͬˮƽ�ļ�����֮����ֲ��죬��Ҳ�������Ե����֡�
�������ģ�û����ȷ������ͬ�ȼ���Ļ������ݡ����ѿ�����Ӣ������������ʽû�и������ֲ�ͬ�ȼ��ľ�����������������֮�������/���������ж�Ϊ“һ��/��һ��”?���������Ҫ��������ܴﵽ“�߶�����”?��ͬ�����˻����Լ��ľ��鼰�����յ�����ѧ֪ʶ����ͬһ��������ܷ�ó�ͬ����“�����Եȼ�”?Ӣ������������ʽ��ӵ������ȷ�ش���Щ���⣬��Ȼ��/���Dz���������Щ����Ĵ���,Ȼ�������Ӧ�ûع鵽��ӵ����ʹ�õļ���������������������-��ѧ����������м���ר�ҵ������жϣ��ɴ˷����ó���Ӣ������������ʽ��������ʽҲһ�����ļ������Ҳ���ɱ���Ĵ������۳ɷ֡����仰˵����Ŀǰ���յ�֪ʶ�̶Ⱥͼ�������������ʵ���Ϻ��Ѹ���һ����ȷ�Ļ������ݡ�
�������壩ѡ��������������ʽ�еļ�ֵ����
����
��������Ŀǰ���������յļ���ˮƽ�ͼ������������ƣ���֮��ͬ����ר���ڼ�����ѡ��ͬ�ص�ļ�������������ϣ���ʹ�ø������������ʽ�������Ÿ��Ե��ŵ�Ͳ��㣬����û���κ�һ�ֱ�����ʽ��������ģ���Щ����Ϊ������“���ѧ��”����“��ɿ���”�з������Է�ģ�Υ���˿�ѧ�ľ������κη�ͥ��ѧ��˵��������������Ҫ��������“��ѧ”��һ�棬�������ܹ�ͬʱ��“��ͥ”�����ض����ҵ�“˾����ϵ”����һ���������ã���“��ͥ”��“��ѧ”���߽�ϵ�ʱ��Ȼ����1+1=2��������ѧ���㣬���漰���ܶ����ѧ����ļ�ֵ�жϡ���ʹ��ͬ����֮��ļ���ˮƽ��ͬ���������������ͬ�Ļ��������ļ�ֵѡ��Ҳ���ܲ�ͬ���������Ƽ�����������ͥ��ѧҲһ�������ԣ�ʹ�ú������������ʽ��������һ�ֿ�ѧ�������⣬ͬʱ����һ�ַ����ϵļ�ֵ�ж����⣬������ֵѡ���ʱ����Ҫ�������¼��㣺�����Ŀ�ѧ�ԡ���ʵ�ԣ��ܷ�ﵽԤ��Ŀ�꣩��ʵ���ԡ����۸ߵ͡���ʵ�����ߣ����ٻ������ţ��Ľ��̶ܳȡ��뱾��������ϵ���ںϵ�Э���Եȡ����������������ʽӦ�þ����ܶ�����������ڶ��ֵѡ�
����LR��ʽ������û�д����Ϸ�ͥ��ѧ���ִ�˼�룬Ȼ������Ŀǰ�����ü������������ƣ���֮ȱ������������IJο��˿����ݣ�ʹ����Ŀǰ�������¸÷�����“��ʵ��”����ۿۣ�LR֧���߷���ǿ��������������������ֵֻ��֤�ݵ���������������Ȼ��������������ڼȷ�����ѧ��/�źŴ���ר�ң��ַ�ͳ��ѧ�ҵ���ʵ��������˵�ܹ���������һ�����֣���LR=123�����ں�,��Щ��ͳ��ѧ�Ҷ�ÿ����������ͥ��������LR�Ľ���Ҳ���߿ɲ����ԡ�ͬʱ������ֻ��ע“��ȫ����”�����ݣ����ӷ�ͥ������̶ܳȵ����������ܻ�����“��������”��“��ѧ����”�Ĺ�Ȧ,��ʵ�в�����ȡ�����ò�����ǣ�LR��ʽ��֧���߳�����“Daubert”����30��Ϊ�������LR��ϵ����Ҫ�������ݣ��ⲻ֪“Daubert”��������ò�����LR��ϵ֧����������������壬ʵ�������“���з��ٿ��Կ���Daubert�����ᵽ��һ��������Ϊ��������أ������ô����������ȷ��֤�Կɿ��ԵĻ����ɿ��Եı�������,Daubert�����ھ������ص��嵥���ȷDZ�Ҫ��Ҳ�������Ե����������е�ר�һ���ÿ��������”�����ĵ���������֤�ݹ����702��32Ҳ��δ��“��֪�Ļ���DZ�ڴ�����”д��������ȥ����ʵ�����ڼ�ֵѡ��IJ�ͬ��������ֻ�в����ݷ�Ժ�����˸ù���33����ֹ2004�꣬��11���ݲ�����“Daubert”������������Ҳ����ͬ��Ҫ���֤�ݹ��������Dz�Ӧ���ų��������еĿ�ѧ�ɷ������Լ����ҵ�֤�ݲ��Ź����ǽ�����Ϊ�κι��ҷ�ͥ��ѧ��ҵ�ߵ��ж�����Ҳ����Ӧ�е�̬�ȣ����ο���Ƭ�����������⡣
��������Ŀ����Եȼ�������ʽ�������⣬ʵ���Ժ�ǿ��Ŀǰ���ڶ����/ר�ҹ㷺����Ҳ֤������һ�㣬Ȼ���������ϴ�����ȱ�ݣ�Ҳ�ܵ�����ѧ�ߵ������������������������ǹ㷺�ģ�����Ŀǰ�������������������ʽ�ǻ��ں�����ʵģ���LR��ϵ֧���߿���������ר���ַ�����ʵ�����ߵ����ղö�Ȩ������ʵ���в������е���ʵ�����߶�����ר�ҵ�����“��Ȩ”��Ϊ���������й���½������ǣ�һ����ܶ�ʱ�ַ��ٻ��ڴ�����“��Ȩ”�ķ�������Ϊ���Ǹ�ϲ��“��ȷ/����”�ļ����������һ���棬��ʹ�Ǽ���ר�Ҹ�����“��ȷ/����”��“��������”,��“����”ʵ����ֻ��ר�ҵ��ж��������һ���ͻ��Ϊ��������IJö����ۣ�����ר�Һܿ�����Ҫ�������������г�ͥ��֤�����ܵ����ˣ�����������䲻����һ��������ʦ�ͷ��ٶ������ɣ�ר������Ƿ�õ����ŵ����վ���Ȩ���ڷ������С��ڲ��ÿ����Եȼ�������ʽ�Ĺ��ң���¹������������ڵ�˾��ʵ�������ٳ���ϰ�������ֺ���ı�����ʽ�����Դ˱�ʾ���⡣�����ʵ�������ڸ���ʽ��ʵ���Ա�����������̬�ȣ���ô�ĸ�������������ϴ���ȱ�ݵ���ʽ��ʧȥ����������“����ȷ”�ļ�ֵѡ����λ��“ʵ����”�ļ�ֵѡ��
����Ӣ������������ʽ��һ��“����”�ļ�ֵѡ��֮������������ѡ������Ϊ��������������Եȼ�������ʽ�д��ڵ���ȱ�ݣ�ͬʱ�������п�ѧ����������������“��ѧ��”�ϵľ����ԣ���ʶ��LR��ʽ���ŵ�“��ȫ����”��“��”����������ȫ�ۣ�����ʵ���в�����ʵ�ԣ����Բ��ò����ڸ����������˱�Ҷ˹ԭ�����ִ�˼�룬ʹ�ø���ʽ�����ϱ����ȷ�����ܸ���ʽ��δ�ı���������������Եı��ʣ���������ʵ�Ժ�ʵ����ȴ�õ���Ӣ������Ĺ㷺�Ͽɡ�
���������ڻ������顢˾����ϵ�ͼ���ˮƽ�ȷ�����ڵIJ��죬�������ڿ�ѧ֤���ϲ�ȡ�ļ�ֵȡ��Ҳ������ͬ�����ۺ�����ʽ�����Ƽ��������������ҪΪ�������ɷ���Ϊ��ʵ������������ʵ�ʽ�ͣ�����������ļ��������Ӧ�ó�Ϊ���ǵļ�ֵѡ�
�����������ҹ�������ʽ����������?
����������������˾�����淶�İ䲼���ڹ淶�ҹ������Ƽ����������˷dz���Ҫ�����ã���Ϊ֮ǰ��2006�����ң������жԸ�������й���ϸ���ļ�����������Ȼ��������������������Ϊ���͵Ŀ����Եȼ�������ʽ���������ϵ�ȱ�ݺͱ����ϵ������ԣ��ҹ����е����������жԼ�������ı���Ҳ���������������⣬��Դ����⣬Ŀǰ������ǣ����˸���LR��ϵ֧���߶����������֮�⣬�����Ƽ�����ҵ��Ա�ͷ��ٶ�����ģʽ��ʾ���⣬��δ�����������Ҫ��Ȼ����������ʶ�����������м������������ʽ����ȱ��֮������Ҫ������һ�μ�ֵѡ���ǹ��ػ����������ȱ�ݵ�ʵ���Ժ�ǿ�Ŀ����Եȼ�������ʽ������ת������ȷ����������ʵ�ֵ�������LR��ʽ������Ӣ������������ʽ�������һЩ��ʾ��
�����塢δ������
����
�������Ƽ�����Ȼ��һ�űȽ��µļ���������ҵ�ںܶ�ר�Һ�ѧ���Ѿ������˷ḻ�ľ��飬�ó��������о��ɹ������ǻ��кܶ�����ֵ������һ�����о�������ص��о���������Ѱ����Щ�����ȶ��Ը�ǿ���˼ʲ����Ը�������������������м��������Ļ����ϣ����ϸ��ַ�����˵���˼����ļ������ƣ��ص㿪չһЩ�����ԵĻ����о����п��ܵĻ������Ǹ��ڴ������µĸ��ɿ��ķ����������������Ǻ��ѵ����顣���ڴ�ͳ������-��ѧ���������ԣ�����Ŀǰ�ܶ��о������ǻ��ڽ��ٷ����ˡ������ġ���ɢ�ġ����������о�����������Ƽ����ļ���ˮƽ�������ޡ�һ���ȽϺõ��о���ʽ�����ȳ��Խ���һЩ�ϴ��ģ�����ݿ⣬�������˵ķ��ԡ��������䡢�Ա�Ȼ��������������ڰ��ˣ��������ˣ����ϣ�ʹ�ö����ŵ�����¼������������ʵ����ƣ��趨���ݹ������ƣ��ڴ˻�����չ��ʵ���Ҽ�����ԵĻ����о������Ŵ�ѧNolan����������ֵ�һ���о���Ŀ“�����Ķ�̬�Ա仯�о�”���Ǻܺõķ�������������Ҳ�ڴ�˵�����Զ�ʶ�����ڲ�Զ�Ľ���ȡ�ø���ķ�չ�������Ľ������ܻ��������������ר�����źŴ���������Ա�������ϣ��ڽ���ı����ݡ��ŵ�³���ԡ������ٶȵȹؼ�����Ļ����ϣ��������ģ���������ݿ⡣Ȼ�����ڿ�Ԥ����ʱ���ڣ�ʵ����˵�����Զ�ʶ��������Ҫ��������ר�ҵĹ㷺���롣��֮��ֻ�д������ϡ������ϴ��£���������������Ƽ����Ŀ�ѧ�Ժ�ȷ�ԣ���������ı�����Ӧ������λ�����⣬��Ϊֻ�дӼ��������Ļ����о������֣����п��ܴӸ����Ͻ�������е�������⣬�������仯��������ֵ������������������������ͬ�������Լ����Ϻ��ȷ�ʵȵȣ�ֻҪ��Щ�������ˣ����ڼ��������α������Ǹ��ӿ�ѧ�ġ��ɿ��ġ��۵ġ����е�����Ͳ����ҵ����ˣ���֮����û�м���������ѧ�ԵĻ����ϣ�̸ֻ������������Ŀ�ѧ��ע�����Դﵽ��ѧ�Ե�Ŀ�ꡣ
������������
����
�����������Ŀǰ���۱Ƚ����ҵ����Ƽ����������������������������ȱȽ�ȫ��ؽ�����Ŀǰʵ��������ʹ�õ�5�ּ���������ָ���˸��ּ�����������ȱ�㣬Ȼ����ִ��4�ּ������������ʽ�����˽��ܺ����������������ڴ˽������������Ӧ����α��������⳹�����ֻϣ�����ĵ������ܹ�������ߵ�˼�������Ź��ڸ���������ۻ���������������Ҫ�����ܽ����£�
������һ������Ŀ����Եȼ�������ʽ������Ŀǰ����������ҵ����Ƽ�����Ա�����á�Ȼ����ʹ�øñ�����ʽ�ļ�������Ҫ�����˼��������������������֮��������ԣ�û�н������������Էŵ������ο��˿���ȥ������ֲ����⣨�������ձ��ԣ����ɴ˵ó��ļ�����������ϴ���һ����ȱ�ݣ����������Խ�ǿ�����Ҳ�ܵ��ܶ�ר�ҵ�������
�����ڶ�����Ȼ�ȣ�LR����ʽ�����ڼ�����ͬʱ���������������Լ��裬���������������Ժ��ձ��Զ������˿��飬���Ҹ���ʽ���Լ�����������������Ƿ���ͬһ����˵���������жϣ�ֻ��ʹ��������LR��ֵ������֤�ݵ�֤�������������ۣ��������������ȷ�ġ�Ȼ��������ȱ����صIJο��˿�ͳ�����ݣ�ʹ����ȫ������LR�����ڼ���ʵ���в�����ʵ�ԣ�ͬʱ����Ŀǰ���еļ��������У�����-��ѧ����������Ȼռ��������λ�����������ѧ�����������õ�ȷ������ͳ�ƣ�Ŀǰ����ij���ض������С�����IJο��˿����ݣ�����ʹ����ѧ�����Բ�����������������ó����۵������Dz������εġ���һ��˵�����������������ԣ���Щ��Ϊ�������Ա���Ϊ���п����Եġ����ܵġ������Ķ���LR����֮ǰ��������ʱ����о�����Ĺ۵��Dz���ʵ�ġ�Ȼ����LR��ϵ�Ͼ��Ǹ���������Դ�����ҲҪ�����㹻�Ŀ�����̬������������ɿ���������Ҫʵ�������顣
��������������ʱ���Ľ����ͼ����ķ�չ�������ƺ����ò���“������������覴õ�”��ʽ��“����ȷ���������ʵ�����Ե�”������ʽ֮��������ֵѡ��������ȫ������LR��ʽ�ڸ��Ӷ�������֤������������ʵ�֣����ǿ��ܲ��ò���Ѱ;�����պ����ֱ�Ҷ˹ԭ�����ִ�˼�룬�����ڲ��õĽ���������Ҳ���ܻ�ת��ʹ��LR��������������ȫ���ֵ�������ʽ������ֻ�����۵ġ����Եġ���ʱ��Ӣ������������ʽ�����ܹ�������һЩ��ʾ��Ȼ������ͬ���ҵ�˾����ϵ����ʵ���鲻ͬ����������ı��������б����������֣�������ͬ�ĵ�����
�������ģ�Ҫ�������������Ŀ�ѧ�ԺͿɿ��ԣ����Dz���Ҫ���ձ�Ҷ˹ԭ�����ִ�˼�룬��Ӧ�ô����������ͼ��������Ĵ��������֣������ڴ���ͬ��������ר��֮�䡢��������ר�����źŴ�������ʦ֮�俪չ�����ԵĻ����о����ڲ��õĽ����г��ε��о����֣��������Ǹ�ʱ����ڼ��������α������Ǹ��ӿ�ѧ�ɿ����ۿ��е�����Ÿ����ش�
������л
����
������лʩ���ࣨ����������ʦ����Ӣ�Ƹ����ڡ����縱���ڡ�������ڶԱ��ij�������ĺ��м�ֵ�����������лMichaelJessen��ʿ��PaulFoulkes������IAFPA2013����ڼ�ʹ����������ߵ��������ۡ����д���֮���ɱ������߳е���������ר���ء�
����
���������
����[1]Saks,M.J.andKoehler,J.J.,Thecomingparadigmshiftinforensicidentificationscience[J].Science,2005,309��5736����892-895.
����[2]NationalReasearchCouncil.StrengtheningforensicscienceintheUnitedStates:Apathforward[M].Washington,DC:TheNationalAcademiesPress,2009.
����[3]LawCommission.ExpertEvidenceinCriminalProceedingsinEnglandandWales��LawCom.No.325��[M].London:TheStationeryOffice,2011.
����[4]��Ӣ����������ܺ��֡����Ƽ�����������[J].���켼����2012��04����54-56.
����[5]Rose,P.,Forensicspeakeridentification[M].LondonandNewYork:CRCPress,2002.
����[6]Rose,P.,Technicalforensicspeakerrecognition:Evaluation,typesandtestingofevidence[J].ComputerSpeech&Lan-guage,2006,20��2-3����159-191.
����[7]Rose,P.andMorrison,G.S.,AresponsetotheUKpositionstatementonforensicspeakercomparison[J].InternationalJournalofSpeech,LanguageandtheLaw,2009,16��1����139-163.
����[8]Morrison,G.S.,Forensicvoicecomparisonandtheparadigmshift[J].Science&Justice,2009,49��4����298-308.
����[9]Morrison,G.S.,CommentsonCoulthard&Johnsons��2007��portrayalofthelikelihood-ratioframework[J].AustralianJournalofForensicSciences,2009,41��2����155-161.
����[10]Morrison,G.S.,Forensicvoicecomparison[A],inExpertEvidence[M],Freckelton,I.andSelby,H.Editors.2010.
����[11]French,P.andHarrison,P.,PositionStatementconcerninguseofimpressionisticlikelihoodtermsinforensicspeakercom-parisoncases[J].InternationalJournalofSpeechLanguageandtheLaw,2007,14��1����137-144.
����[12]French,P.,Nolan,F.,Foulkes,P.,etal.,TheUKpositionstatementonforensicspeakercomparison:arejoindertoRoseandMorrison[J].InternationalJournalofSpeechLanguageandtheLaw,2010,17��1����143-152.
����[13]Nolan,F.,Speakeridentificationevidence:itsforms,limitations,androles[A].inProceedingsoftheconferenceLawandLanguage:ProspectandRetrospect[C].2001,Levi��FinnishLapland����
����[14]Nolan,F.,Voice[A],inIdentification:Investigation,trialandscientificevidence[M],BoganP.S.,andRoberts,A.,Editors.2011,381-390.
����[15]Foulkes,P.andFrench,P.,Forensicspeakercomparison:alinguistic-acousticperspective[A],inTheOxfordHandbookofLanguageandLaw[M],Tiersma,P.andSolan,L.,Editors.2012,557-573.
����[16]Broeders,A.P.A.,Someobservationsontheuseofprobabilityscalesinforensicidentification[J].ForensicLinguistics,1999,6��2����228-241.
����[17]Broeders,A.P.A.,Forensicspeechandaudioanalysis,forensiclinguistics.Areview:2001to2004[A].in14thINTER-POLForensicScienceSymposium[C].2004,Lyon,France.
����[18]Eriksson,A.,Aural/Acousticvs.AutomaticMethodsinForensicPhoneticCaseWork[A],inForensicSpeakerRecogni-tion:LawEnforcementandCounter-Terrorism[M],NeusteinA.andPatilH.A.,Editors.2011,Springer.41-69.
����[19]Eriksson,A.,Presentingevidenceincourt–somefundamentalproblemstobeconsidered[A].inProceedingofInterna-tionalAssociationforForensicPhoneticsandAcousticsAnnualConference[C].2011,Vienna,Austria.
����[20]�Ŵ��ᣬRose,P.,������Ȼ�ʷ���������֤������[J].֤�ݿ�ѧ��2008��03����337-342.
����[21]�Ŵ��ᡣ��ͥ�������������·�չ[A].�ڶ���֤���������ѧ�������ֻ�[C].2009.�й�������
����[22]�Ŵ��ᡣ��ͥ�����ȽϵĿ�ѧ�ԺͿɿ���[A],�������֣��������ࡣ֤���������ѧ:������������ֻ����ļ�[C],�������й�������ѧ�����磬2012.
����[23]�Ŵ��ᡣ��ͥ���������о�[M].�������й��������磬2009.
����[24]���������Ƽ������۵Ŀ�ѧ�Ա���ģʽ[J].���ϴ�ѧѧ��������ѧ�棩��2009��05����122-125.
����[25]Jessen,M.,�ܺ��֣���Ӣ�����룩����ͥ����ѧ[J].֤�ݿ�ѧ��2010��06����712-738.
����[26]K�ister,O.andK�ister,J.,Theauditory-perceptualevaluationofvoicequalityinforensicspeakerrecognition[J].ThePho-netician,2004,89��1����9-37.
����[27]K�ister,O.,Jessen,M.,Khairi,F.,etal.Auditory-perceptualidentificationofvoicequalitybyexpertandnon-expertlis-teners[A].inProceedingsofthe16thinternationalcongressofphoneticsciences��ICPhSXVI��[C].2007.Saarbrücken.
����[28]Laver,J.,Thephoneticdescriptionofvoicequality[M].Cambridge:CambridgeUniversityPress,1980.
����[29]Nolan,F.,Auditoryandacousticanalysisinspeakerrecognition[A],inLanguageandthelaw[M],Gibbons,J.Editor.Longman:London/NewYork.1994:326-345.
����[30]Nolan,F.,Forensicspeakeridentificationandthephoneticdescriptionofvoicequality[A],inAFigureofSpeech:aFestschriftforJohnLaver[M].Hardcastle,W.J.andBeck,J.M.,Editors.LawrenceErlbaumAssociates,Inc.:NewJerseyandLondon.2005:385-411.
����[31]Kersta,L.G.,VoiceprintIdentification[J].Nature,1962,196��4861����1253-1257.
����[32]Tosi,O.,Oyer,H.,Lashbrook,W.,etal.,ExperimentonVoiceIdentification[J].TheJournaloftheAcousticalSocietyofAmerica,1972,51��6B����2030-2043.
����[33]Tosi,O.,Voiceidentification:theoryandlegalapplications[M].Baltimore:UniversityParkPress,1979.
����[34]Nolan,F.,Thephoneticbasesofspeakerrecognition[M].Cambridge:CambridgeUniversityPress,1983.
����[35]Hollien,H.F.,Theacousticsofcrime:Thenewscienceofforensicphonetics[M].NewYork:PlenumPress,1990.
����[36]Hollien,H.F.,Forensicvoiceidentification[M].SanDiego:AcademicPress,2002.
����[37]InternationalAssociationforForensicPhoneticsandAcoustics,IAFPAResolution-Voiceprints[EB/OL],2007.[cited2013August24]
����[38]���������о����»ᣬ�������룩��ɤ�������������ʵ��[M].������Ⱥ�ڳ����磬1989.
����[39]Morrison,G.S.,Distinguishingbetweenforensicscienceandforensicpseudoscience:Testingofvalidityandreliability,andapproachestoforensicvoicecomparison��inpress��[J].Science&Justice,2013.
����[40]Koenig,B.E.,Spectrographicvoiceidentification:Aforensicsurvey[J].TheJournaloftheAcousticalSocietyofAmerica,1986,79:2088-2091.
����[41]VoiceIdentificationandAcousticAnalysisSubcommitteeoftheInternationalAssociationforIdentification.VoiceCom-parisonStandards[J].JournalofForensicIdentification,1991,41��5����373-396.
����[42]Cain,S.,AmericanBoardofRecordedEvidence-VoiceComparisonStandards.[EB/OL],1998.[cited2013August24].
����[43]Maher,R.,Audioforensicexamination:Authenticity,enhancement,andinterpretation[J].SignalProcessingMagazine,IEEE,2009,26��2����84-94.
����[44]Nakasone,H.andBeck.S.D.,Forensicautomaticspeakerrecognition[A].inProceedingofSpeakerOdysseySpeakerRecognitionWorkshop[C]2001.
����[45]Coulthard,M.andJohnson,A.,Anintroductiontoforensiclinguistics:languageinevidence[M].LondonandNewYork:Routledge,2007.
����[46]Archer,C.,HSNWconversationwithHirotakaNakasoneoftheFBI:VoicerecognitioncapabilitiesattheFBI-fromthe1960stothepresent[EB/OL],2012.[cited2013August24].
����[47]Branca,A.,ZimmermanCase:Dr.HirotakaNakasone,FBI,andthelow-quality3-secondaudiofile[EB/OL].2013.[cited2013August24].
����[48]Solan,L.M.andTiersma,P.M.,Hearingvoices:Speakeridentificationincourt[J].HastingsLJ,2002,54��2����373-435.
����[49]Solan,L.M.andTiersma,P.M.,Speakingofcrime:Thelanguageofcriminaljustice[M].ChicagoandLondon:UniversityofChicagoPress,2005.
����[50]Tiersma,P.M.andSolan,L.,Thelinguistonthewitnessstand:forensiclinguisticsinAmericancourts[J].Language,2002,78��2����221-239.
����[51]Schwartz,R.,VoiceprintsintheUnitedStates-Whytheywontgoaway[A].inProceedingofInternationalAssociationforForensicPhoneticsandAcousticsAnnualConference[C].2006,G�iteborg,Sweden.
����[52]��Ӣ�����������Ƽ�����������������[A].�ھŽ��й�����ѧѧ���������ļ�[C].2010.�й����
����[53]Gfroerer,S.,Auditory-instrumentalforensicspeakerrecognition[A].inProceedingsofEurospeech2003[C].2003.Geneva,Switzerland.
����[54]�����˵���˼�������[A],��һ��ȫ��������������ѧ������������ѡ[C],��������֤�������ģ��������й�������ѧ�����磬2007:281-286.
����[55]�����������֤�����������������������[A],������ѧ�������������ࡣ��֤����ѧ�����İ棩[M],�й������ѧ�����磺������2011:266-284.
����[56]Nolan,F.,ForensicPhonetics[J].JournalofLinguistics,1991,27��2����483-493.
����[57]���������ƽ�����������Զ�ʶ���������ƿ⽨��Ӧ��[J].���켼����2012��04����66-69.
����[58]Gold,E.andFrench,P.,InternationalPracticesinForensicSpeakerComparison[J].InternationalJournalofSpeechLan-guageandtheLaw,2011,18��2����293-307.
����[59]˾����˾��������ѧ�����о�����2010˾������������֤������������[M].��������ѧ�����磬2011.
����[60]Utl��tandeskalan/SKL/Utlatandeskalan.pdf��[EB/OL].2008.[cited2013August24].
����[61]Jessen,M.,ConclusionsonvoicecomparisonevidenceinGermanyandachallengingcase[A].inProceedingofInterna-tionalAssociationforForensicPhoneticsandAcousticsAnnualConference[C].2011.Vienna,Austria.
����[62]Bo�c��L.-J.,ForensicvoiceidentificationinFrance[J].SpeechCommunication,2000,31��2-3����205-224.
����[63]McDermott,M.C.,Owen,T.andMcDermott.F.M.,VOICEIDENTIFICATION:TheAural/SpectrographicMethod.[EB/OL].1996.[cited2013August24].
����[64]��������˾����������ѧ����[M].�������й��������磬2009.
����[65]���磬��������ʶ������������淶[M].�������й�������ѧ�����磬2012.
����[66]�����ᣬ��Ƶ�е���������[A],��鳼���š���Ƶ���鼼���淶[M].�������й�������ѧ�����硣2012.
����[67]Cambier-Langeveld,T.,Currentmethodsinforensicspeakeridentification:Resultsofacollaborativeexercise[J].Interna-tionalJournalofSpeechLanguageandtheLaw,2007,14��2����223-243.
����[68]Champod,C.andEvett,I.W.,CommentaryonAPABroeders��1999��Someobservationsontheuseofprobabilityscalesinforensicidentification,ForensicLinguistics6��2����228–41[J].ForensicLinguistics,2000,7��2����239-243.
����[69]Forensic-Speech-Science.info,[EB/OL].2007.[cited2013August24]
����[70]��������֤�������ģ�����ͬһ�϶�������IFSC11-01-01-2010��[S],2010.
����[71]�й�����˾����˾�����������֣�¼�����ϼ����淶��SF/ZJD0301001-2010��[S],2010.
����[72]Nolan,F.andOh,T.,Identicaltwins,differentvoices[J].ForensicLinguistics,1996,3:39-49.
����[73]Rose,P.,Goingandgettingit–Forensicspeakerrecognitionfromtheperspectiveofatraditionalpractitioner-researcher[A].intheAustralianResearchCouncilNetworkinHumanCommunicationScienceWorkshop:FSInotCSI–Perspec-tivesinState-of-the-ArtForensicSpeakerRecognition[C].2007.Sydney.
����[74]Coulthard,M.,Expertsandopinions:Inmyopinion[A],inTheRoutledgeHandbookofForensicLinguistics[M],Coulthard,M.andJohnson,A.,Editors.Routledge.2010:473-486.
����[75]Lindh,J.,Eriksson,A.andNelhans.G.,MethodologicalIssuesinthePresentationandEvaluationofSpeechEvidenceinSweden[A].inProceedingofInternationalAssociationforForensicPhoneticsandAcousticsAnnualConference[C].2010.Trier,German.
����[76]��̾���ר��֤���о�[M].�������й������ѧ�����磬2004.
����[77]����ϲ������������֤�ݹ���2011�����ܰ棩����[M].�������й����Ƴ����磬2012.
����[78]AdmissibilityofScientificEvidenceUnderDaubert[EB/OL].[cited2013August24].
����[79]Nolan,F.,McDougall,K.,DeJong,G.,etal.,TheDyViSdatabase:style-controlledrecordingsof100homogeneousspeakersforwforensicphoneticresearch[J].InternationalJournalofSpeechLanguageandtheLaw,2009,16��1����31-57.





