
0、引言
我国正处于工业化、城镇化发展的关键阶段,资源需求刚性上升,资源环境压力日益增大,加强生态文明制度建设,把资源消耗、环境损害、生态效益纳入经济社会发展评价体系,建立体现生态文明要求的目标体系、考核办法、奖惩机制是立足国内提高能源资源保障能力的现实选择,对我国经济社会发展具有十分重要的现实意义和深远的战略意义。
然而多年来,绿色矿山评价缺乏统一标准,评价主管决策因素太大,有失公平。因此,国土资源部提出创建一个统一的绿色矿山评价标准,而矿山企业的技术创新能力作为重要的评价内容列入其中。在此背景下,本文专门研究矿山企业中煤矿的技术创新能力评价体系,运用数据挖掘技术中的ID3决策树算法,在很大程度上提高了评价准确度,为评选绿色矿山企业提供了可靠的依据,同时也为煤矿企业在技术创新领域的效果做出分析,便于进一步改进提高。
1、理论与方法
1.1ID3算法模型
ID3算法是Quinlan于1979年提出的一种经典的决策树算法,此算法将属性的信息增益作为各级结点的属性选择标准。在几种决策树算法中,ID3算法可以说是最有影响力的。为了实现达到以最小信息量最大程度对测试数据分类目的,样本划分的测试属性要选择信息增益最大的属性。该算法内容概括如下:
树从训练样本的某单个结点开始,若样本都属于同一类,那么该结点成为树叶,分类结束,用该类标号。如果样本属性不属于同一个类,算法使用信息增益度量作为启发信息,来计算能将样本最好地分类的属性。计算出的属性便是该节点的测试属性。在此算法中,所有的属性都是要分类的,即本算法只适用于离散值,如果是连续属性的话必须进行离散化。对每个已知的测试属性值都要创建一个分支,以此来划分样本。根据以上步骤,递归此算法形成样本判定树。每个分支上的属性只会出现一次,一旦使用某属性对样本集划分后,此属性在这个分支上就不会出现了。
递归划分步骤只要出现下列条件便会停止:所有属性都以完成对样本的划分;所有样本属于同一类;某个测试属性值上已经没有样本。测试属性的取值是样本集的划分依据,样本集将划分为多少子样本集取决于测试属性有多少不同取值。以信息增益度量作为选择测试属性的依据,属性的信息增益越大就越重要,也就更靠近根节点,所以要选择具有最高信息增益的属性作为当前结点的测试属性。由于采用此信息理论方法可以使一个对象分类的期望测试数目最小,以保证能找到一棵简单的树。
设S是s个数据样本的集合,类标号属性有m个不同值,并定义n个不同类Ci(i=1,2,...,n)。设Si是类中的样本数,则对一个样本分类所需的期望信息为:
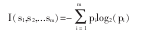
其中,pi—任意样本属于的概率,用Si/S表示。设属性A具有v个不同值{a1,a2,...av},可以用属性A将S划分为v个子集{S1,S2,...,Sv},在属性A上,Si中的样本的取值为aj。设子集中类Ci的样本数为sij,则属性A的熵可以这样计算:

集中的样本数除以S的样本总数。熵值与划分纯度成反比,即熵值越高,子集划分的纯度越低,反之亦然。对于子集Sj有:

通过上述公式计算每个属性的信息增益,选择具有最高信息增益的属性作为集第一个属性,即根节点的决策属性,当创建结点之后,对属性的每个值分别创建分枝,划分样本。引入信息增益的概念是ID3算法的一大特点。该算法应用简单,基础理论清晰。该算法的计算时间是结点个数、例子个数和特征个数之积的线性函数。由于目标函数一定在搜索空间中,而搜索空间又是完全的假设空间,所以此算法一定有解。该算法不是像候选剪除算法逐个地考虑训练例,而是全盘使用训练数据,这样的优点是可以抵抗噪音,利用全部训练例的统计性质进行决策。
总的来说,ID3算法是一种具有实用价值的学习算法,它的学习能力较强,基础理论清晰,算法较简单,是机器学习和数据挖掘领域中的一个经典方法。
1.2ID3算法应用
构建煤矿技术创新能力评价数据集。根据煤矿技术创新能力评价指标体系,选择了11家煤矿的技术创新数据,并将其整理,如表1所示。


由于分类属性太多,而当前的训练集数据太少,若按照当前分类建模,准确率会很低,在实验后得到的准确率为9.0909%,不符合要求。若根据指标权值合并划分属性,将原先的22个属性合并到4个。并用等宽间距法将每个属性五等分,由高到低划分为5个级别,对原始数据进行数据处理,得到处理后的数据集如表2所示。
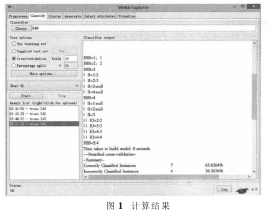

对训练集进行标准化后,用ID3算法进行分类并计算,得到结果如图1所示。从图中可以看到,通过对属性的合并以及对原始训练集数据进行相应转换后,再次运用ID3算法得到的分类模型比之前的分类准确率高出很多,达到63.6364%,这说明对于当前训练集的划分属性改进是比较正确的,也得到了更为理想的结果。根据上图中的分类规则创建对应的决策树。如图2所示。
解析上图的决策规则为:


以上为最终得到的分类规则,即评价模型,通过此模型可以对其他实例进行划分,得到相应的分类。
2、结论
本论文运用数据挖掘中ID3算法,通过对煤矿技术创新能力数据研究分析,产生决策规则,通过对决策规则进行验证,正确率较高,基本能够反映煤矿的技术创新能力。由于训练集数据量小,采用了合并指标的办法来减少划分属性,其中引入的专家权值造成了一定的主观影响。
参考文献:
[1]陈燕.数据挖掘技术与应用[M].北京:清华大学出版社,2010.
[2]王宏云.基于数据挖掘的煤矿安全监测系统研究[D].辽宁工程技术大学,2009,12.
[3]彭蓬.基于神经网络的煤矿企业技术创新能力评价及经济学分析[J].煤矿现代化,2008,87.
[4]冯陈雷.基于决策树方法的煤炭企业效绩评价研究[D].山东科技大学,2007,5.





