
对于少于 1 000 人的企业单位,60% 的员工认为在企业信息化平台中找到自己想要的数据是非常困难的。
而在公司人数超过 1 000 人的情况下,认为获取不到自己想要数据的员工竟然达到公司人数的 77%.因此,企业的规模越大,企业的人数越多,企业信息化平台中产生的数据量就越多,员工查找信息就更加困难。根据调查显示,对于少于 1 000 人的企业里,有 67% 的员工认为找到所需的信息对企业的发展是有影响的,而对于多于 1 000 人的企业中,这个数字竟然高达 89%.在大中型企业中,每天有 70% 的员工耗费 1 ~ 2 小时来查找所需要的信息,加大了企业的成本,尤其是用户想要查看已经离职员工之前记录的信息,由于人员已经离开,想要查找对应信息的难度加大,搜索耗费的时间就更长。
传统企业搜索引擎虽然在一定程度上已经解决该问题。然而,不同角色的用户有着不同的需求,例如,财务角色的用户和销售角色的用户对于相同的查询词会有不同的需求。本文提出采用卡方的方法进行角色信息的分析,使不同角色的用户虽采用相同的查询词,但得到与其角色更相关的信息。
1 基于卡方的角色分析理论
企业内部每个用户在不同系统中的职位不一样,对于相同角色下的用户,偏好可能相同,如角色 A 下的用户关注财务信息,经常搜索和点击财务方面的数据。当角色 A 下的其他用户搜索时,如果查询词跟 A 输入的查询词相关时,根据 LUCENE,获取文档应排在后面,但根据角色信息,角色 A 下的用户点击过多的文档应排在前面,这样就隐含地为用户推送了相关文档。针对这个可能性,进行角色分析。【1】

其中,N 是一个定值,系统的数据条目数;A 代表在某角色中文档包含该词的篇数;B 代表在该角色中文档没有包含该词的篇数;C 代表的是不在该角色下有多少篇文档包含该词;D 代表的是不在该角色下有多少篇文档没有包含该词;而 A+C 是一个定值,B+D 也是一个定值,因此公式(1)可以简化,如下所示:【2】
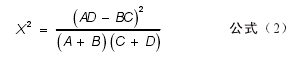
2 基于卡方的角色分析理论算法过程
因为企业中有多个系统,分系统考虑,统计一个系统下所有角色对应的特征词。
第一步获取某系统下的所有数据,获取文档对应的用户以及角色,并对正文部分进行分词。
第二步获取角色 A 在该系统下的所有数据并分词。
第三步对角色 A 下的每个词 T,统计词 T 在该角色下出现的样本频率,获取词 T 在该角色中没有出现的样本频率,获取词 T 不在该角色下出现的样本频率,获取词 T 不在该角色下没有出现的样本频率。
第四步,根据公式(2)计算该系统下角色 A 中词T 的权重;获取每个系统下的每个角色对应的特征词,并保存。
第五步获取用户所能访问系统中角色对应的特征词,并根据特征词进行全文检索,获取排名前300的文档。
当获取某系统下角色 A 权重最大的 10 个词时,需考虑特征词在该系统下所有角色中出现的次数,如果次数大于角色个数的一个比值时,则这样的词排除掉,因为这样的词不具有特性。
当用户查询时,根据输入查询词,得到搜索结果,分析前 300 篇文档中是否包含该文档,如果包含,则将文档的分数提高。
3 结 语
针对目前企业搜索中存在的问题,不同角色的用户有着不同的需求,本文提出基于卡方的角色分析方法,使不同角色的用户虽采用相同的查询词,但得到与其角色更相关的信息。该方法已经应用在实际平台中,进一步证明了该方法的有效性。
参考文献
[1] 吴庆涛 . 个性化搜索引擎中的用户兴趣模型分析与研究 [J]. 研究与开发 ,2010(10)。
[2] 李绍华 , 高文宇 . 搜索引擎页面排序算法研究综述 [J]. 计算机应用研究 ,2007(24)。





