
安徽农业大学校园网始建于 2000 年,现有信息网点一万多个,学生用户二万多人,FTP 服务器是校园网主要的应用服务之一。在 FTP 服务器上目前保存着多种共享软件、技术资料和多媒体数据等几十个 TB 的文件资源。FTP 服务器建有若干目录,文件与目录结构存在多样性、复杂性,学生要想在FTP 服务器上找到自己需要的文件,很麻烦,即使按照目录名( 文件夹) 点击,也需要好几层才能找到自己所需要的文件,无法快速搜索、定位,更别提进行数据文件的统计、学生需求应用的查询等,若要在多个 FTP 服务器上查找文件更是困难。基于国内北大天网、百合谷搜索和 FTP 星空搜索的搭建思路,构建安徽农业大学自己的 FTP 搜索引擎,便于省内其他高校进行类似建设,也为了进一步提高校园网的应用服务水平,我们团队根据高校的实际需求情况,以 Linux 系统为平台,利用 Apache、MySQL、PHP和 Python,设计并开发了 FTP 搜索引擎。
1 FTP 搜索引擎原理
FTP 搜索引擎采用 C / S 模式,Server 端进行数据采集和处理( 入库) ,Client 进行关键词搜索,然后Server 进行数据处理,最后返回结果。故采用以下思路来进行模块式分析、解决:
( 1) 数据的存储方式( 数据库设计) ;( 2) 如何采集数据( 多线程) ;( 3) 查询时 Server 端处理数据( 分词,限定条件) 并返回,同时将结果显示给用户。
FTP 搜索引擎由数据采集、数据查询和站点维护等模块组成。建立一个 FTP 搜索引擎,首先要收集各个 FTP 站点上的文件信息,并把这些信息存储到配置文件中; 然后给用户提供查询界面,以获取用户要查询的信息,把这些查询信息转化为数据库语言,然后再进行数据库查询,把查询结果以友好的界面显示给用户; 搜索引擎建好后,为了使数据库数据与 FTP 站点的数据保持一致,还需要更新 FTP 站点的文件信息、添加新的 FTP 站点等管理和维护工作。FTP 搜索引擎的结构[1]如图 1 所示。
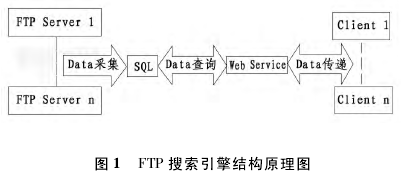
设计 FTP 搜索引擎时,操作系统采用 Linux,WWW 服务器采用 Apache,数据库采用 MySQL,编程语言采用 PHP 和 Python,其中 Python 作为遍历脚本。
2 数据库结构和设置
2. 1 文件信息分析
安徽农业大学 FTP 站点上,根目录下的目录中有许多子文件夹和文件,其中每个文件信息又包括:
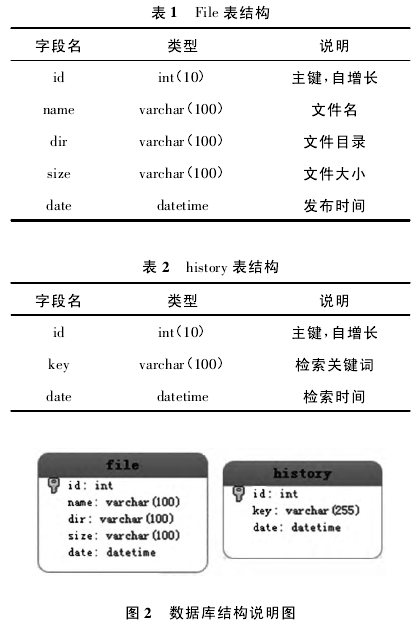
文件名、文件大小、文件地址、日期、类型等属性。对应这些文件信息,在数据库中设置相应的字段,用来记录这些信息,用字段 name 存储文件名( 不大于255 个字符) ,将其设置为 varchar 类型,长度为 255,host 表示 FTP 网站的名称,说明是哪个 ftp 网站上的文件,dir 字段准确给出文件的 URL 地址。由于有些文件的 URL 比较长,因此把 dir 字段类型设置为longtext.有了这些字段,就可以在网络中找到此文件的位置。当然还需要记录下文件的大小、时间、日期,以便用户分辨选择他们所要的文件。另外为提高查询速度( 查询时对文件名字段的访问比较频繁) ,文件名字段设置成 Index 字段。文件表结构见表 1、表 2,数据库结构见图 2.
2. 2 FTP 站点信息分析
一个 FTP 站点通常包含服务器名称、用户名和密码。对应 FTP 站点的信息,数据字段设置如下:
站点名、站点 IP 地址、用户名、用户密码等几个字段。站点名字段类型为 vchar,长度为 60; IP 地址为vchar 类型,长度为 50; 用户名为 vchar 类型,长度为50; 密码设置为 password 类型,长度为 60.由于 FTP站点名也是使用较为频繁的数据,因此把它设置为Index 字段。
3 数据采集
首先收集各个 FTP 站点的文件信息,记录到数据库里,用于提供搜索。因特网中有许多 FTP 站点,要收集某个 FTP 站点的文件信息时,就从数据表中读出站点信息,然后登陆到该 FTP 站点。大部分 FTP 服务器都有公共访问区,即公用 FTP,我校对全校师生员工提供免费的文件信息服务,用户名为public,密码为 public,目前限制为校内才能访问。
数据采集程序以用户名和密码登陆站点,然后对该站点所有目录进行采集,读取每个目录下的文件信息,在收到文件信息后,对其进行分析,将文件信息存储到相应的数据表字段中。完成此站点的数据采集之后,再读取另外一个 FTP 站点的信息,进行文件信息采集,如此循环,从而采集所有已知 FTP 站点的文件信息。为了加快遍历速度,这里采用了python 的进程和线程技术,经过测试,遍历 30 万条记录只需要 10 分钟左右。
由于获取 FTP 信息在使用深度优先和广度优先上算法是相同的,这里使用的是深度优先算法。
获取目录信息主要使用的是递归来遍历文件和文件夹信息,有一个主函数的作用是遍历文件,存入该文件的名称和目录信息到数据库中。当得到的是文件目录时,则继续重复调用该函数,进入该目录继续遍历,直至完成整个目录的遍历为止。这样,我们存入数据库就包括一个文件,含有所属站点、文件名称( 文件格式) 、路径等信息,如图 3 所示。

为了增量获取信息,可以通过设定计划任务在每天的凌晨来启动遍历程序,这样可以确保新增的文件可以及时存入到数据库中,有效保证数据库文件的及时性、准确性。
计划任务: 00***root python / opt / ftpspider. py
抓取脚本:
#! / usr / bin / python
#encoding = utf - 8
#导入模块
import os,re,types,MySQLdb,sys,codecs,threading
from multiprocessing import Process,Pool
from ftplib import FTP
#连接 FTP
def link( username,password,ip) :
ftp = FTP( ip)
login = ftp. login( username,password)
return ftp
#获取文件信息并存入数据库
def getfile( ftp,path,ip) :
ftp. cwd( path)
for file in ftp. nlst( ) :
dir = path + ' / ' + file
try:
ftp. cwd( dir)
dir = ftp. pwd( )
#多线程获取文件信息
t = threading. Thread( target = getfile,args =
( link( ) ,dir) )
t. start( )
t. join( )
except:
dir = path
name = file
#将文件信息存入数据库
sql = “ insert into file values ( ” ,' + ' + ip
+ ',' + path + ',' + name + ‘) ’“
insert( sql)
def insert( sql) :
conn = MySQLdb. Connect ( user = ' root',passwd
= ” ,db = ' ftp',host = ' 192. 168. 77. 5',charset = '
utf8‘)
cur = conn. cursor ( cursorclass = MySQLdb. cur-
sors. DictCursor)
cur. execute( “ SET NAMES utf8” )
cur. execute( sql)
rows = cur. fetchall( )
conn. commit( )
cur. close( )
conn. close( )
#获取 FTP 站点信息
def ftpinfo( ) :
conn = MySQLdb. Connect ( user = ' root',passwd
= “ ,db = ' ftp',host = ' 192. 168. 77. 5',charset = 'utf8’)
cur = conn. cursor( cursorclass = MySQLdb. cur-
sors. DictCursor)
cur. execute( ” SET NAMES utf8“ )
cur. execute( ” select* from ftpinfo“ )
rows = cur. fetchall( )
return rows
conn. commit( )
cur. close( )
conn. close( )
#启动该脚本
def start( ) :
addr = ftpinfo( )
for info in addr:
username = info['username']
password = info['username']
ip = info['ip']
ftp = link( username,password,ip)
#多进程
p = Process( target = getfile,args = ( ftp,' / ',ip) )
p. start( )
start( )
4 数据查询
数据查询主要包括查询 web 页面的设计、程序编写和查询结果的输出处理。查询页面由 Web 服务器提供,用户浏览该页面,填写并提交搜索信息,如文件名、大小等。然后将该信息提交给 Web 服务器,由查询程序进行处理,再生成查询语句,提交至SQL 服务器进行查询。查询结果则由查询程序进行处理,以超链接形式生成 Web 页面,便于用户浏览,获悉结果[1].
为进一步实现文件细分,引导搜索,增加便利性,我们仿照其他全文搜索引擎的样式并结合本校FTP 站点文件的现状,决定按照文件格式的区分来进行分类搜索,主要依据是文件的格式( 文件的后缀名) ,比如。 doc、。 rar 等。当用户检索关键词时,我们可以通过如下 sql 语句来进行 mysql 的多字段检索匹配,其中三个字段 site( 站点) 、name( 文件名或类型) 、dir( 目录) 中的任何一个字段和给出的关键词相同的话即可返回结果。Sql 语句[2]如下:
select* from ' file' where concat( site,name,dir)like'% 关键词%5 搜索结果处理。
5. 1 搜索结果分页
分页显示,即数据库中的结果集,一段一段显示出来,包括: 怎么分段、当前在第几段 ( 每页有几条,当前在第几页) 分页公式:
( 当前页数 -1) × 每页条数,每页条数
Select* from table limit ( S| Page - 1) * S| PageS-ize,S| PageSize
前 10 条记录: select* from table limit 0,10.
5. 2 关键词推荐
用户每次检索记录后,我们都会将搜索过的关键词存入到数据库中,在首页会有一个最近搜索词的推荐,便于用户知道其它人最近检索的是什么,我们也可以直接插入关键词到数据库中。根据这些关键词,作为校园网的一项重要服务,就可以有针对性地上传特定的更具体的资源。关键词推荐效果如图4 所示。
关键词推荐效果的具体实现过程如下:
S| sql = “ select DISTINCT history. 'key' from histo-
ry; ” ;
S| query = mysql_query( S| sql) ;
while( S| rs = @ mysql_fetch_array( S| query) ) {
S| return. = getlabel( S| rs['key']) ;
}
echo S| return;
/ / 获得推荐关键字随机样式
function getlabel( S| key) {
S| label_style = array(
'0' = > 'label label-primary',
'1' = > 'label label-success',
'2' = > 'label label-info',
'3' = > 'label label-warning',
'4' = > 'label label-danger',
'5' = > 'label label-warning',
'6' = > 'label label-danger',
) ;
/ / 返回最新关键词标签
return“ < a href = '#'class = ‘” . S| label_style[rand
( 0,6) ]. “' > ”. S|key. “ < /a > ”;
}
5. 3 搜索结果自动分类
传统的 FTP 搜索引擎一般都是根据用户提交的查询词,在索引数据库中匹配,然后对检索结果按相关度排序。诚然,相关度排序能够将较重要的结果信息反馈给用户,但也存在着一词多义与多词同义的问题,使得检索结果依然很难满足不同用户的需求。为了改进检索结果的质量,采用: 根据 FTP文件扩展名标识,其次利用 K - 群近邻算法对检索结果的文件名分类,这样检索结果就有了层次结构,从而进一步方便了用户查找,而且提高了用户的获取效率。搜索结果如图 5 所示。
6 自定义 FTP 服务器地址
对于 FTP 服务器地址的管理,设置一个专门的配置文件,该配置文件仅只读权限,且无法下载。该文件保存以下信息: FTP 服务器的地址,用户名和密码。数据结构使用的是二维数组,如 S| ftp_site = ar-ray( '0' = > array ( ' ip' = > '210. 45. 176. 32',' user-name' = > 'public','password' = > 'public‘) ,
'1' = > array ( ' ip' = > '210. 45. 176. 24',' user-name' = > 'public','password' = > 'public’) ) ;
当执行遍历程序时,会在后台读取该文件,一个站点遍历完成后,则会遍历下一个 FTP 站点。
7 搜索引擎维护与性能优化
搜索引擎维护,其中重要的一点就是数据库数据与 FTP 站点的数据保持一致,维护中包括增加、显示、删除及更改 FTP 站点等功能。另外,为了实现站点文件信息自动更新的功能,把更新 FTP 站点文件信息的程序( ftp. php) 设置成系统周期性计划任务,如日凌晨1∶ 00 运行 1 次。
结合其他 Web 搜索引擎的优点,我们采用了全文索引方式,即先对网页进行中文分词,然后提取关键词项对数据文件建立倒排索引表[3].经过学生的调查统计分析,用户在 FTP 搜索引擎中查询的文件类型主要是电影、软件、歌曲、视频等。FTP 文件名大致可分 4 种类型: 纯英文、纯中文、中英文混排、其它等[3].我校 FTP 服务器中存储的文件: 12% 的文件为纯英文命名,45% 的文件是中英文混排命名,32% 的文件是纯中文命名,其它命名形式占 11% ,以上命名比例在视频与电影文件命名中尤为突出。
因此,在设计搜索引擎索引文件结构时应对中文作更多的优化。由于中文字符集的常用汉字数比英文字母多,所以两者的编码方式不同[4],英文是单字节,而中文要用两个字节来存储,且双字节索引的性能比单字节的要高,因此在考虑兼容性与性能的基础上,FTP 搜索引擎采用双字节倒排索引技术,即对文件名中每两个字节建立倒排索引表。
ALTER TABLE ' file' ADD FULLTEXT INDEX 'filename‘( 'name’)
8 结论
介绍了高校 FTP 搜索引擎的设计与实现,重点展示了系统所采用的关键技术和方法,对构建思路、程序设计、语句实现等方面进行了系统、具体的阐述。目前该搜索引擎已经在安徽农业大学校园网上使用,为用户提供了很好的服务,得到了用户的普遍好评。下一步将继续就搜索引擎的分布式处理、支持 IPV6、进一步提高查询速度、更高效的分类检索、满足移动终端需求、跨高校的 FTP 站点群共享等方面的技术进行研究,努力让高校 FTP 搜索引擎能更好地服务于广大师生员工。
参考文献:
[1]汪剑,牟奇春,王霖,等。 基于 SQL SERVER 的 FTP 搜索引擎系统的设计[J]. 软件导刊,2008,7( 6) : 93 -95.
[2]钟伟财。 精通 PHP4. 0 与 MySQL 架构 Web 数据库实务[M]. 北京: 中国青年出版社,2000.
[3]武海燕。 基于校园网的 FTP 搜索引擎的研究与实现[J]. 中国电子商务,2010( 2) : 53 -54.
[4]石小梅,刘克剑。 FTP 搜索引擎索引技术的研究[J]. 西南民族大学学报: 自然科学版,2012,38( 3) : 475 -477.





