
0 引 言
代码的重用性在软件工程领域是一个很重要的课题。通过面向对象分析、模块化编程,开发者可以很大程度地提升代码的重用性。但在具体编码时,仍然会遇到很多在方法层面上需要重用的情况。考虑如寻找一段可直接使用的寻路算法,或者是矩阵打包算法。这些具有特定功能的源码在目前通过关键字搜索的方式下很难在海量源码中被搜索到。原因有3 个: 1) 源码中变量名的命名法通常使用缩写,并以大写字母进行分词,如 preNode,inRect 等,而用户进行搜索输入的关键字更偏向自然语言,如 previousnode,input rect。这导致很多源码无法通过关键字匹配算法匹配。2) 在 Sourceforge 或者 Github 即使存在匹配的关键字,更多的搜索结果是头文件或接口,很少有实际可用的源码。3) 自然语言存在同义词问题,语义相近的源码会由于无法被字符串匹配而错过。如用户输入 draw node,draw( vertex[]v) 就不会被搜索到。
文献通过以语义网络为文本关键字建立近义词索引的方法,改善了文本搜索问题中近义词无法被关键字匹配算法所匹配的问题。本文将该方法运用于源码搜索,并结合传统的程序分析技术,提出一种海量源码分析的新方法,解决上文提到的源码搜索遇到的 3 方面问题。
1、 相关工作
1. 1 基于关键字的海量源码搜索引擎
传统源码搜索引擎采用关键字匹配的算法,如Github 的代码搜索服务,其优势是搜索迅速,可以用通用的文本搜索引擎检索源码,而缺陷如引言所述,无法匹配源码中的缩写,以及搜索结果大部分是无数据流的方法声明。
1. 2 基于自然语言的源码定位
Emily Hill在基于自然语言的源码定位方面做了很多建设性的工作。其主要目的为了解决软件开发过程中由于缺少文档而导致的软件维护困难问题,帮助开发者更方便地定位系统模块,了解系统结构。其核心思想是通过分析制定项目,为项目中的标识符建立源码索引,如 strtPt: start point,srcNode: sourcenode。最后通过用户输入的自然语言词素与标识符拓展后的词素进行匹配达到源码定位的目的。
2、 分析及搜索方法描述
本文将 Emily Hill的自然语言源码定位应用于海量数据,并构建一个包含海量源码变量使用关系与词素拓展集的数据库。在此之上运用关键字匹配算法定位相关源代码。
2. 1 源码 identify 缩写拓展到自然语言单词
本文提出一种树状单词树用以解决将标识符从缩写到完整词素的拓展算法。如图 1 所示。
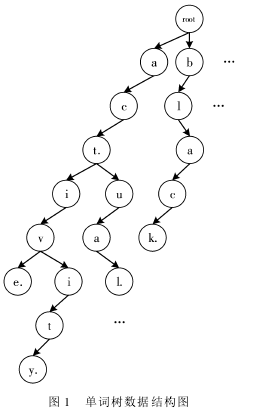
构造完成的单词树是一种包含所有英语词素的树状数据结构,其中每个节点有且仅有一个字符信息,并附带标志位 isWord,其中自顶向下的路径表示一个词素序列,当节点上 isWord 被标记时,代表路径到此为止构成的序列是一个完整词素。图 1 以“. ”作为完整词素标记。以下是节点数据结构的定义:

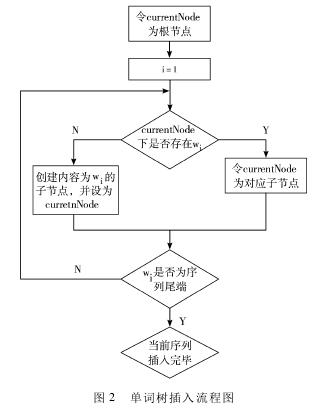
如图 2 所示,对一棵单词树 T,插入词素 w1w2…wn的过程如下:令 T[wi]表示字符 wi在第 i 层对应的节点。则 T[w1]是根节点下字符为 w1的节点。倘若不存在,则创建对应节点。对每个 wk,k >1,寻找 T[wk - 1]节点下是否存在字符为 wk的节点,倘若存在,则 T[wk]为该节点,若不存在则创建字符为 wk的子节点。图 1 所示为在一棵空单词树上插入 act,active,activity,black,actual 几个词后的示意图。
将全词素列表的每条词素按上述算法插入一棵空树,最后得到的结果即包含全词素的单词树。在已建立的单词树基础上,对标识符 I 拓展完整词素备选集的问题可划归为树路径搜索问题,令 I[i]表示 I 中第 i 个字符,满足条件的路径必须依次( 不必连续) 包含内容为 I[1],I[2],I[3],…,I[n -1]字符的节点,并以 isWord 标记为 true 的节点终止,该问题是一个深度优先搜索问题。图 1 示例中,对“actv”寻找完整词素拓展集合的结果即为{ activity,active} 。
以下为词素扩展过程伪代码。
过程: Node[]expand ( root,I,offset) 。
输入: root 表示自然语言单词树根节点,I 表示要拓展的标识符字符串,offset 表示 I 的起始偏移量。
返回: Node[]表示每条满足要求的路径的最后节点,该节点 isWord 必须为 true。

通过该算法获得的节点集合对每个节点不断访问 parent 即可获得该节点对应的完整路径,即一个完整词素。
2. 2 海量数据库建立
基于语义的搜索过程如图 3 所示。
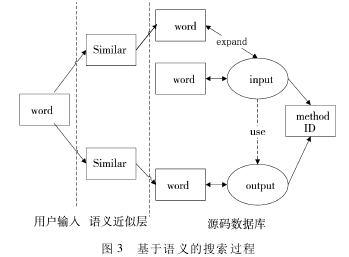
本文的核心思想是通过分析海量源码,建立源码数据库,数据库中包含源码中标识符之间的关系,以及标识符对应的完整词素的扩展。
源码中标识符的关系主要包含以下 2 点:
1) 方法与变量的从属关系;2) 同一方法体内变量的使用关系。以上 2 点主要通过传统的程序分析方法建立,本文使用的工具是 JavaCC,对源代码进行静态的语法分析,最后以关系型数据库 MySQL 持久化分析结果。
2. 3 搜索算法
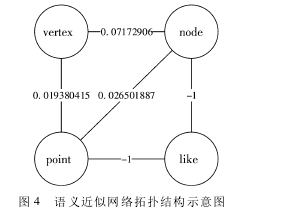
令函数 Similarity( wi,wj) 代表 S 中 2 个单词的语义近似度,其值域为[0,1],该值的获取方法通过 Dis-co Wiki 数据库,其结构如图 4 所示。

最后按降序排列的方法结果集合即为搜索结果。
3、 测试结果及分析
实验从功能及性能 2 方面进行评测,通过不同难度的测试用例,统计使用者对本引擎的搜索结果与Github 搜索结果匹配度进行对比以评价引擎的可用性。
3. 1 搜索用例测试
测试用例实验主要通过提供 4 组不同难度的测试用例,并召集 10 位志愿者分别在 Github 上与在本引擎上搜索测试用例,并将前 10 条结果匹配率作为反馈进行比较。当结果中包含具体源码,源码标识符内容与输入所匹配时,算作一条匹配结果。
测试用例 1: 寻找图表绘制 API 相关源码。根据本文定义的格式,以{ chart; draw; Φ} 作为输入。
测试用例 2: 本例采用实现较为多样化的最大流问题作为搜索。以{ source,stream; max; Φ} 作为关键字进行查询。
测试用例 3: 本例作为测试用例 2 的对比测试,以更精准的{ source,flow; max; Φ} 搜索最大流算法。该测试用例主要测试语义近似对搜索结果的影响。
测试用例 4: 寻路算法寻找,输入{ start; find,path; Φ} 。
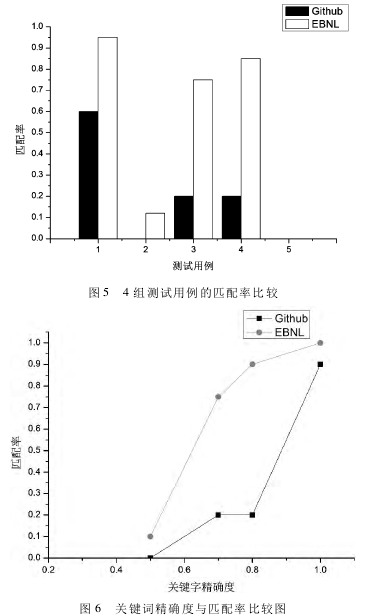
由图 5、图 6 可知,在匹配度上,4 组测试用例中本文的搜索结果均高于 Github,在实验中,Github 的搜索结果大部分是接口声明,本文的搜索结果均包含匹配关键字的数据流,具有可工作源码。在语义近似的测试用例上,如最大流问题的 stream 与 flow,没有flow 关键字时,Github 不存在匹配的结果,而本文的方法在前 10 项搜索结果中仍然包含匹配的源码。4项测试的比较中,本文提出的方法搜索结果均强于Github 的搜索结果。
3. 2 性能测试
该测试根据参数扩展集最大容量 maxArg、被影响参数扩展集最大容量 maxAffected、调用图搜索的最大深度 d、词汇泛用性 v 为基准对搜索引擎性能进行评估。测试结果如表 1 所示。
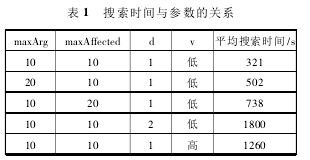
表 1 中的数据表明,参数和被影响参数对搜索时间影响是线性的,被影响参数系数更大,原因是被影响参数集合大小决定了调用图搜索的复杂度。而深度的增加对时间的增加是高于线性的,因为广度优先搜索每多搜一层其元素将是上一层的 k 倍,k 取决于节点的平均子节点数量。单词的泛用性,高的指 object等泛用名字,低的指词义信息具体的名词,对搜索时间影响得非常大,原因是单词泛用性决定了搜索引擎构筑的语义网络的出度,从而影响备选集的容量。
4、 结束语
本文通过结合程序分析与语义网络,通过大数据分析的方法,为源码中的标识符建立使用关系。本文基于缩写拓展算法,设计适用于程序标识符缩写的自然语言单词拓展算法。通过使用自然语义近似网络,将用户的关键字进行拓展,与之前生成的源码标识符拓展集合结合搜索,解决了以往源码搜索引擎因源码使用缩写而导致的关键字不匹配或无法搜索到语义近似的源码的问题。
在实际使用过程中,该引擎能够搜到主流通用算法,如寻路、3D 飞行、图像压缩等。搜索时间取决于单词的通用性与专业性,以及调用图的深度。通过为开发者提供方法层面的可靠搜索引擎,能够大幅度提升开发者的开发效率。





