
1 传统搜索引擎存在问题
(1) 目录式搜索的缺陷是速度慢
目录式搜索的用户界面基本上都是分级结构, 提供几个大类入口, 用户一级一级地向下查询, 经过若干人工搜索后找到需要查询的结果. 它虽然可以找到需要的信息, 但是其死链接较多, 要依赖手工操作, 按照分类逐层的搜索才能找到, 检索速度非常慢, 有失搜索的功能. 搜索引擎是一种信息检索工具, 要极大缩短人们查找信息的时间, 来最大化地提升了人们的工作效率.
(2) 全文搜索引擎的缺陷是检索功能有限
全文搜索引擎它拥有词命中率不高, 范畴检索功能有限,没有截词检索功能. 它的效率好不好得根据各站的技术判定.
(3) 关键词搜索的缺陷是信息量大, 良莠不齐
关键词搜索返回的信息过多, 需要用户明确知道自己要找什么, 然后理出一个清晰的关键词进行搜索, 否则会搜索出很多无关信息, 这些信息良莠不齐, 鱼龙混杂, 需要用户必须从结果中逐一进行筛选辨别后才能使用. 如果输入多个关键词进行查找, 那么搜出的信息才可能相对减少, 这样就使得人们感到浪费时间很是不方便. 同时关键词搜索不能把多方面的内容融为一体自动过滤提取最有价值的内容.
(4) 模糊搜索的缺陷是准确率低
模糊搜索是建立在关键词搜索理论基础上的同义词搜索,只要输入关键词, 该关键词的所有同义词信息都被搜索出来,留给用户的就是成千上万的信息. 因为输入的搜索请求是模糊的, 所以也无法在最短的时间内, 帮助用户最快地找到所需要的准确信息. 用户如果要找到准确的信息就得一次次地输入多个关键词才可能找到, 这样就显得比较麻烦了.
2 基于企业深度挖掘型的新型垂直搜索引擎
2.1 深度挖掘型搜索的优点
通过对元数据信息进入深度加工, 提供用户专业性、 功能性、 关联性、 用户信息管理以及信息发布互动等功能的网页搜索, 能很好地满足用户高要求的搜索信息的需求. 专业的元数据属性构造背后需要一个强大专业人士组成的团队.
这些专业人士对该领域的元数据模型进行专业的分析、 关联整合, 再通过搜索技术按这些元数据模型把这些信息组织呈现给用户.
2.2 垂直搜索引擎的体系结构
搜索引擎[1]系统一般由网页抓取模块、 信息抽取和索引模块、 界面及检索模块 3 大模块组成, 其中网页抓取模块包括网页信息采集和网页预处理; 信息抽取和索引模块包括 Web信息抽取和建立倒排索引; 界面及检索模块包括查询界面.搜索引擎的体系结构如图 1 所示.
网络信息采集: 主要是指通过 Web 页面之间的链接关系,从 Web 上自动地获取页面信息, 并且随着链接不断向所需要的 Web 页面扩展的过程. 实现这一过程主要是由 Web 信息采集器 (Web Crawler) 来完成的.
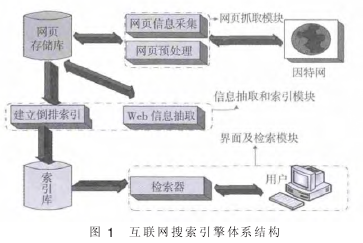
网页预处理: 在数据进入数据仓库之前, 对数据进行抽取、 转化和清理. 从外围系统或源系统中把数据导入, 转化一般指对数据的进行统一 (包括数据格式和数据编码的统一), 然后把一些垃圾数据清理掉, 保留有用数据.Web 信 息抽取 : 是设计 Wrapper 包装器和抽取规则抽取主题相关信息.建立倒排索引: 利用垂直搜索的相关技术如中文分词技术、 索引排序技术等技术建立索引规则.
界面及检索模块: 界面提供用户接口接收用户查询请求、反馈查询结果. 搜索引擎为用户提供通过输入关键词来得到结果的输入输出的可视化界面. 用户在关键词输入界面中,输入检索关键语句、 关键词以及各种检索的关键条件; 在查询结果输出界面, 搜索引擎将检索到的结果按一定规则输出显示.
2.3 构建良好深度挖掘型垂直搜索引擎的要求
(1) 高效的可扩展的信息检索器作为垂直搜索引擎的最基本环节, 信息检索器 (Crawler)为了满足垂直搜索的后续要求, 信息检索器必须能够智能地获取制定网络数据, 并且返回详细报告, 作为后续分析提供参数, 另外检索器必须实现良好的扩展性, 提供各种规则过滤接口, 以便于满足垂直搜索针对特定域的检索要求.
(2) 模板智能生成匹配, 元数据抽取做为垂直搜索引擎的一个重要环节, 利用现有的智能学习方法和算法, 进行改进, 研究智能模板生成, 以及人工训练方法, 研究网页元数据抽取, 实现分散的元数据还原、 聚集.
(3) 基于语义网, 超链接的文本分类, 定向采集对于巨大信息量的网页库, 即便是指定域的网页, 仍然存在大量的不关联和极少关联的网页, 利用现有的超链接识别, 信息提取判断, 结合对网页文本特征提取, 获取文本的权重, 主体相关性, 实现快速定向采集, 过滤掉不相关的超链和文档, 为检索器实现快速定向采集提供支持.
(4) 数据的后期分析提取, 提供查询在大量结构化数据提取后, 面对这些原始的数据集, 如何通过研究一些智能方法, 进行数据重组过滤提取, 获取原来不存在, 但是却对用户很有意义用途的数据信息, 并且智能化建立相关索引提供给用户查询.
3 核心技术
3.1 信息采集
每天互联网上传输的信息内容相当于 3 亿页的文本[3], 要从中针对定制的目标数据源, 通过人工设定网址和网页分析url 方式进行数据采集 . 垂直搜索对信息源的稳定 、 抓 取的成本问题及对用户体验改善程度有着很高的要求.
3.2 网页信息抽取
整个过程中, 数据由非结构化数据抽取成结构化数据,好比网页搜索是以网页为最小单位, 基于视觉的网页块分析是以网页块为最小单位, 而垂直搜索是以结构化数据为最小单位, 然后将这些数据存储到数据库, 经过深度加工处理后以非结构化的方式和结构化的方式返回给用户.
3.3 信息处理
信息处理的范围主要包括去重、 聚类、 分析……, 在此简要说说聚类技术和中文分词技术. 聚类技术指根据 "物以类聚" 原理, 对之前无任何类别标注的样本信息, 不需要人工标注和预先训练分类器, 利用样本间的相似性和差异性等各种相关性, 类别在聚类过程中自动生成的一种无指导的计算机学习过程叫做聚类[4](Clustering). 简单来说, 聚类是指事先没有 "标签" 而通过某种成团分析找出事物之间存在聚集性原因的过程. 聚类不同于分类, 聚类划分的类是未知的,且聚类中的分类在过程中自动生成. 而分类是事先定义好类别 , 类别数不变的. 搜索引擎中利用聚类思想对用户输入的关键词检索结果进行分类, 可想而知聚类思想的应用给搜索引擎的用户带来很好的铺垫. 对于中文信息处理中各种分词方法目前有很多, 大致可以分为: 机械分词法、 基于理解的分词以及基于统计的分词 3 类, 而其中文分词[5](Chinese WordSegmentation) 技术是一个重要的基础 , 中文分词应用广泛 ,且是中文搜索引擎的核心技术之一.
3.4 元数据管理
元数据管理是数据中心信息资源标准管理, 通过该系统来规范管理数据资源的规范定义、 命名、 分类等, 同时也将帮助从技术的角度梳理所有的信息系统, 理解每一个数据的来龙去脉.
元数据管理功能包含元模型管理、 元数据的维护及查询、元数据批量加载、 元数据自动获取、 元数据的分析及应用、元数据版本管理以及元数据的同步检查等.
3.5 索引排序
索引排序是按照索引的关键字的顺序建立一个新的、 与原索引文件同样大小、 结构相同的物理文件, 改变了物理顺序. 目前常用的排序算法有两种, PageRank 算法和 HITS 算法[6].
4 企业垂直搜索引擎系统设计
4.1 需求分析
由于企业信息的不断发展和累积, 一直以来好多企业领导对企业的运营情况只能通过各个部门的人工报表进行了解分析, 这样运营指标缺乏统一、 直观、 准确、 快速的展现方式, 同时对经营存在的问题也缺乏深层次的了解[8]. 因此, 需要搭建一个能够对企业数据进行搜索挖掘, 进而可以对过滤出的数据进行高效分析, 从多个角度以多种方式掌握和展现企业的经营情况, 深层次地搜索发掘数据信息从而进行数据服务的系统.
4.2 总体架构
基于企业深度挖掘型垂直搜索引擎的数据服务的系统架构如图 2 所示, 包括 4 个部分: 数据采集、 数据挖掘、 元数据管理和数据服务.
(1) 数据采集
数据源是整个系统的运行的根本, 其包括企业的内部数据和外部数据及一号工程数据等, 该模块是采集数据任何爬虫都不可或缺的通用模块, 该模块负责协调超链接分析模块和页面相关度分析模块的工作. 首先, 爬虫采集模块从待爬行 URL 队列中取出链接相关度较高的 URL, 将该 URL 相应的网页采集到本地, 然后, 将该页面交由页面相关度分析模块处理. 在整个爬行过程中, 爬行的次序和爬行策略都有链接分析模块提供.
(2) 数据挖掘
Web 数据挖掘建立在对大量的网络数据进行分析的基础上, 采用相应的数据挖掘算法, 在具体的应用模型上进行数据的提取、 数据筛选、 数据转换、 数据挖掘和模式分析, 通过存储数据字典、 按照一定的数据转换规则、 对数据进行自动加载频率等组织相应的元数据, 对那些需要重点分析的元数据进行有效整理统计分析, 进而根据所获得的相关数据进行应用.
(3) 元数据管理
系统根据烟草数据中心元数据管理规范对元数据进行定义, 支持烟草元数据的分类管理. 系统提供包括获取层元数据维护、 存储层元数据维护、 访问层元数据维护、 交换层元数据维护以及元数据的检索、 浏览、 打印等功能.
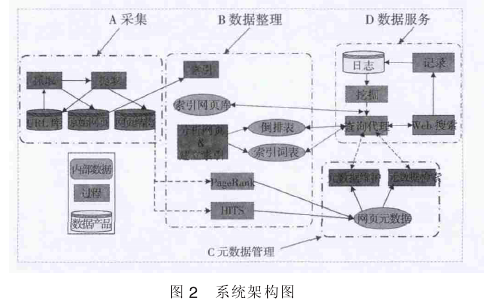
(4) 数据服务
数据服务让使用者无需去访问或者更新多个数据源, 更重要的是, 当使用者需要操作多个数据源时, 数据服务有助于维持数据的完整性. 此外, 它们还能够帮助构建可被多个项目和创新利用的可重用数据服务. 数据服务还能够执行关键的治理职能---它们有助于度量指标的集中化、 监视、 版本管理、 数据类型的重用, 以及执行数据可视化和访问规则.
数据服务的范围包括: 数据实体上的各种操作, 聚合多个不同数据源的数据, 使用多种协议简化使用多个平台的数据接口, 逻辑接口和物理提供者接口之间的映射.
4.3 系统架构
基于企业垂直搜索引擎的数据服务的系统是建立挖掘型垂直搜索引擎进行元数据分析整理, 改变一般搜索引擎只将网页为最小单位存储到数据库中, 此系统将网页的非结构化数据抽取成特定的结构化信息数据, 对行业领域内的信息模型和用户模型结构化的搜集或再组织, 提供更多、 更专业、个性化的行业相关服务.
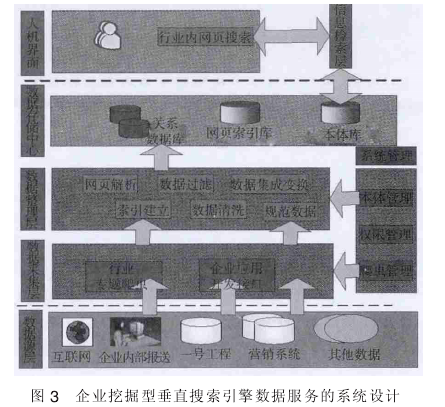
数据源层主要包括: 互联网、 企业内部报送、 一号工程等; 数据采集层主要包括: 行业专题爬虫、 企业应用开发接口等; 数据加工层主要包括网页解析、 索引建立、 数据过滤等; 数据存储中心主要包括: 关系数据库、 网页索引库、 本体库等; 信息检索层、 展现层实现不再累述.
4.4 人机交互界面
(1) 不同工作分工的人员有不同的权限访问系统进行相应的操作.
(2) 能同时显示不同种类的信息 , 用户可在几个工作环境中切换而不丢失几个工作之间的联系.
(3) 引用图标、 下拉式菜单、 按钮等技术使那些不太精于打字的用户和系统之间有很高的交互.
(4) 系统提供自动通知, 用户可以及时知道需要处理哪些工作.
(5) 系统为方便用户了解分析数据提供了报表和图形的方式.
(6) 系统提供良好的人机交互.
(7) 提供一定的帮助系统.
参考文献
[1] 赵 杰. 搜 索引擎技术 [M] . 哈 尔滨 : 哈尔滨工程大学出版社, 2007.
[2] 卢 亮 , 张博文 . 搜索引擎原理实践 与应用 [M] . 北 京 :电子工业出版社, 2010.
[3] 陈 菊红. 搜索引擎返回结 果聚类技术的研究与实现 [D] .成都: 西南交通大学, 2009.
[4] 沈岳. 搜索引擎技术综述 [J] . 北京城市学院学报 , 2007,13 (4).
[5] 朱 焱. 基于数据中心的烟草决策分析系统的构建 [J] . 计算机与现代, 2009, (9).
[6] 赵大明. 基于本体的专业搜素引擎的研究与设计 [D] . 陕西: 西北大学, 2009.
[7] 杨 坚争 , 李朝平. 垂直搜索引擎及其应用. 电 子商务 [J],2006, (10): 24-25





