
1、 引言
近年来,随着数字化教育浪潮的不断推进,我国在教育资源建设方面已经取得了巨大的成就,各类教育资源的数量巨大且呈现几何级数增长。随着搜索引擎技术的发展, 通用搜索引擎的功能变得日益强大, 取得了很大的成功, 但其仍有局限性, 如搜索的深度不够, 且查准率低、时效性差。尤其是现有的通用搜索引擎的搜索方式是采用关键字的形式实现, 没有根据用户的个体差异满足用户的个性化需求, 其返回结果往往不令人满意。
基于语义的搜索引擎是指搜索引擎的工作不再拘泥于用户输入的关键词,而是能够对这些关键词进行语义推理。通过在语义的层面上把文档中关键词和其映射的概念进行关联, 可以部分解决文档语义理解的问题。语义搜索对网页文档信息所蕴含的语义信息进行充分挖掘, 同时把用户的检索要求转换成相应的语义表示, 基于领域本体对其进行辨别和推理, 从语义层面理解用户查询, 并将基于本体推理的结果返回给用户。
本文从基础教育网络资源搜索的需求考虑,在开源技术Hadoop 和 Nutch 的基础上设计了面向基础教育领域的语义垂直搜索引擎,并对如何实现语义搜索的关键技术进行了重点研究。
2、 系统框架设计
利用搭建在Hadoop 分布式系统上的 Nutch 开源软件进行面向基础教育的网络资源爬行,过滤掉与基础教育无关的信息,将爬行的内容进行解析、去重后存入分布式数据库Hbase 中,接着利用人工构建及自动抽取技术实现教育资源本体库,再基于领域本体库实现对用户查询内容的语义检索,从而使得搜集信息具有“专、精、深”的特点,检索内容准确、可靠、快速且更新及时。该系统框架设计如图1所示:
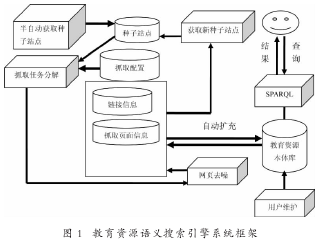
3 关键技术研究
①种子网站的选取和过滤因为该搜索引擎是针对基础教育这一特定主题,为了是搜索站点的范围更具有代表性,只爬取和主题相关的URL,需要根据一定的策略算法对“网络蜘蛛”程序的初次爬行网址做一些过滤。这一过程借助Web- Harvest 开源软件对 intute、DMOZ 等开放式分类目录中的特定领域站点列表进行抽取, 形成站点描述XML 文件。为了获得更多的种子站点, 可以使用能够代表领域特征的语词, 通过 Yahoo! Search API 进行检索来获得更多的候选站点URL。经过上述途径获得的候选站点, 需要根据 PageRank 值、连通情况指标及主题相关度预测算法进行初步过滤, 将影响力不大、难以访问及相关度不高的站点排除, 最后再通过人工方式进一步核查和分类, 最终获得高质量的站点种子。
②网页自动去噪和去重通过 Nutch 抓取的网页, 除含有有效的正文内容外, 还携带有广告信息、客户端运行代码、版权声明、栏目设置等噪音信息。为了给后续的信息抽取、分析步骤提供高质量语料,减少噪音信息的干扰。设计在网页抓取阶段根据噪音信息的一般特征设置网页去噪模块,对网页内容进行过滤。网页去重功能保证了抓取内容数据库中存储的网页是不重复的,也可以识别新发布的页面。
③搭建分布式系统基于开源云平台Hadoop搭建分布式系统,利用分布式平台提高信息抓取和信息检索的效率。充分利用Nutch面向接口的插件技术,对关键模块进行封装,使系统具有高度重用性,从而为今后该系统的扩展打下良好基础。
④教育资源本体的构建随着语义网(Semantic Web)研究的不断深入和实践的 不断发展,特别是XML 和 RDF 技术的日趋成熟,以及 W3C 认定 OWL 语言后,基于语义网的本体论为有效地开发、管理和使用教育资源提供了解决方法。
目前还不存在一种被公认的本体构建的标准框架, 当前被广泛接受的是 Gruber 于 1995 年提出的本体构建五项原则,分别是:明确性、一致性、可扩展性、最少约束性和完整性。上述五项原则给出了构造领域本体的基本思路, 但不足之处是它们反映的内容较抽象,在具体实践中难以把握,为此研究人员从不同的角度提出了众多本体构建方法。
首先,根据教育领域的各种权威性的词表来构建领域本体, 既可以根据词表中概念间存在的简单语义关系构建轻量级的本体, 这种本体语义简单但优点是容易通过编写程序实现大批量的自动转化。可以选择《教育资源建设技术规范》(CELTS-41) 作为元数据方案,基于此定义出教育资源本体的核心类。具体实现可使用Protégé 软件进行本体的构造, 使用 Protégé 提供的OWLvizTal 插件, 这个插件可以通过图形的形式显示构建的教育资源本体中各子类的层次关系。在建立了教育领域本体的核心类之后, 要确定本体概念间的属性关系。Protégé 中到的属性关系包括两种属性:
关系属性与数值属性。关系属性表示概念间的逻辑关系,如前驱关系(hasPrecursor)、后继关系(hasSuccessor)、包含关系(is_part_of)等,关系属性有定义域与值域,即指明这一关系的方向。本体的类、关系属性和数字属性设计完成后, 教育资源领域本体的总体架构设计就完成了,之后要录入教育资源信息,即实例信息数据。
在已有的本体库基础上,设计了基于本体的自适应 Web 信息抽取平台的模型视图,该模型视图如图 2所示:
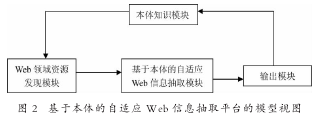
其中,Web领域资源发现模块:该模块的功能是实现面向不同网页类型的网络爬虫,定向获取与教育领域相关的资源,通过机器学习技术,对所获得的网页数据进行过滤, 将获得到的教育相关数据提交给基于本体的自适应信息抽取模块。基于本体的自适应 Web 信息抽取模块:接收来自Web 领域资源发现模块的信息, 结合相应的抽取任务描述信息,调用相应的抽取方法,完成不同类型数据的抽取工作。输出模块:对经过验证后的输出结果进行输出,写入特定的数据库或知识库中, 同时建立将抽取结果与相应的本体之间的关系,实现本体的扩充。本体知识模块: 该模块包含与待抽取目标相关的本体知识, 涉及不同的教育领域本体、数据库描述本体、交互关系本体以及各种知识库资源等。
⑤本体数据及实例数据存储模型RDF Schema 可视为一种简单的本体语言,但是它过于简单,描述能力较弱,难以表示复杂的领域知识,因此需要对其进行扩展,Web 本体描述语言 OWL 是对RDF Schema 的一种扩展。
现有的OWL 数据管理系统大都采用 XML 文件或传统的关系型数据库来存储OWL 数据, 这种方式已难以高效地管理海量OWL 数据。本文结合关系型OWL数据存储模式以及分布式系统平台,提出一种基于分布式数据库 HBase 的 OWL 数据存储模型构思,进一步设计该存储模型上的基于 MapReduce 的SPARQL查询算法。
4、 结束语
本文还只是初步设计了一个的教育资源语义搜索引擎框架,在很多关键技术方面还有待进一步探究和改进。相信在不久的将来,特别是随着本体构建技术的不断健全,语义检索的应用范围会愈来愈广。
参考文献:
[1]王晓伟. 垂直搜索引擎若干关键技术的研究[D]. 杭州:[学位论文],浙江大学, 2007.
[2]冯桂尔. 基于本体的教育资源探究[J]. 上海: 计算机教育,2007.1.
[3]周纯. 垂直搜索引擎技术进展[J]. 天津: 知识经济,2011 年 09 期.
[4]吕 昊. 面向垂直搜索的聚焦爬虫研究及应用[D]. 杭州:浙江大学, 2012 .
[5]胡宜敏. 农业垂直搜索引擎语义化若干问题的研究与实现[D]. 合肥:[学位论文],中国科学技术大学, 2012 .
[6]李传席. 基于本体的自动 Web 信息抽取方法研究[D]. 合肥:[学位论文]中国科技技术大学,2012.5[7]郭仲毅. 基于本体的教育资源个性化语义检索研究[D]. 内蒙古:[学位论文],内蒙古大学, 2012 .
[8]莫 倩, 张 树, 王 芳. 面向领域的智能搜索引擎设计与实现[J]. 北京:计算机工程与应用, 2012.
[9]张 静,唐杰. 下一代搜索引擎的焦点:知识图谱[J]. 北京: 中国计算机学会通讯, 第 9 卷第 4 期,2013 年 4 月.
[10]郑文良. 基于简单本体的农业 P2P 搜索引擎关键技术研究[D]. 沈阳:[学位论文], 沈阳农业大学, 2013.6.
[11]朱敏. 基于 HBase 的 RDF 数据存储与查询研究[D]. 南京:[学位论文]南京大学, 2013.5.





