摘 要: 中文分词算法在搜索引擎应用中有着广泛的应用空间,且能够增加信息检索的准确性,故而值得予以推广。在此之上,本文简要分析了中文分词算法的作用与中文分词算法在搜索引擎中的难点,并分别从基于字符串匹配分词、基于N元语法分词、基于搜索统计技术等方面,论述了中文分词算法在搜索引擎应用中的运用策略,以此提高大众对中文分词算法的认知水平。
关键词 : 中文分词算法;搜索引擎;字符串;
中文分词算法是通过将中文重划为词序列的形式,以此展现文本含义。若将其运用于搜索引擎应用中,可进一步增加搜索结果的准确性与搜索速度,进而满足大众对信息的迫切需求。同时,还需结合中文分词算法的不同类别为其创造适合的运用条件,以便在搜索引擎应用中发挥出重大效用,便于快速精准的查找关键词,并给出可靠的搜索结果,最终促使中文资源实现最大化利用。
1 、中文分词算法的作用
在大数据时代,网络信息的丰富性造成大众在信息筛选中极易受到一定阻力。而中文分词算法作为一种分词技术,它能够快速帮助用户查找到关键信息,以便在搜索时间上起到促进作用。好比在百度网站中,它的搜索引擎模块中可借助中文分词算法依靠“词汇”的形式予以搜索,从而增加信息检索准确性与时效性。其中具体指的“中文分词”是以词汇重新切分的方式为计算机搜索引擎提供可用信息,以便快速给出有效数据。相比英文分词模式中的“空格分词”,中文分词仅在段落、语句中适用,并在搜索引擎无法准确识别词汇含义时,依靠中文分词算法将其转化为“词序列”,由此确保词序列在后期能够经过科学分析匹配适合的信息,最终为大众带来有用信息,准确完成信息检索任务。

2、 中文分词算法在搜索引擎应用中的难点
中文分词算法在实际应用环节,还存在一些待突破的难点,由此造成中文分词算法无法在搜索引擎应用中展现出最优化特征。通常情况下,结合中文分词算法的具体作用可将其难点归纳为下述三点:
其一,高精度与高速度。由于现今数据量较为庞大,如若在搜索引擎应用中未能准确识别词义,并给出错误或准确性较低的信息,很容易影响用户的搜索体验。因此,在研究中文分词算法时需要进一步提升其精度与速度,使其能够在分词上展现出显着优势,以此满足大数据时代的信息检索需求。从当前实际研发结果来看,中文分词技术在其发展阶段依然取得了些许成就,但随着词汇句意的多样性,在分词速度与准确度上仍有待提高,进而借助中文分词算法增加搜索引擎应用的实用性,使其为更多用户提供优质信息检索服务,最终确保每一次搜索都能获得理想化结果。
其二,歧义词义,日常大众交流时,也会因词义出现歧义现象而影响表达效果。而在搜索引擎应用中也会受歧义词义的干扰降低搜索精度,造成检索后的结果与最初要求不匹配。因此,在研究中文分词算法时最为重要的是还应当采取有效措施适当杜绝歧义问题。其中歧义是指计算机设备中的搜索引擎无法准确词义。一般而言,歧义可包含交叉歧义与组合歧义两种类型。
其中前者相比之下易于处理。好比在“他可爱吃蛋糕了”中,可将“可爱”作为一个组合词予以搜索,造成检索结果与句意不符,而在搜索时,用户的检索要求是按照“他-可-爱-吃蛋糕”的分词形式进行搜索。由于计算机搜索引擎未具备人体思维,故而只能利用词汇的联合性加以切分。
后者是在词句中出现名词、动词错误认知等现象引起词义,好比在“她把手弄坏了”中,“把”实则为“动词”,然而在具体分词时,由于“把手”又可当成“名词”,故而在检索时会根据名词的形式进行查找,最终降低检索准确性。
其三,新词识别,随着许多新词的出现,如“键盘侠”“导姐”等,造成计算机在语义识别时对尚未登录在搜索引擎词典中的词汇出现错误识别现象,尤其是许多网络热词、新增人名、地名的出现,若未能及时更新词典,也会引起搜索错误。同时,在词汇判断时也会产生操作难度[1]。
好比在“杨虎诚心诚意卖菜”中,对于“杨虎诚”是否可将其当成人名进行搜索,这些都对搜索引擎带来难度。尤其在新词增速不断提高的情况下,针对新词识别准确度的判断是搜索引擎应用效果的关键评价要素。因此,在搜索引擎应用中运用中文分词算法时应结合具体难点提出可行性整改建议,以此扩大搜索引擎的应用范围,促使中文分词算法展现出真正优势。
3 、中文分词算法在搜索引擎应用中的运用策略
3.1、 基于字符串匹配分词
在搜索引擎应用中运用中文分词算法时,其中最为重要的方式是基于字符串匹配分词,从而根据字符串的匹配程度提取关键词,进而搜索有效信息。其中字符串匹配分词是通过与词库中存储的数据进行对比,之后秉承着一定匹配原则给出识别结果,并将其作为搜索引擎的检索依据查找相关信息。虽然此种方法操作简单,但其准确度与辨别歧义语义的能力有限。为了进一步强化字符串匹配分词方法的实用性,还可在其中增添一些匹配标准,以便增加字符串匹配的准确性,也能促使搜索引擎具有较为广泛的应用空间。
常见的改进方法包括“最长匹配”“最小匹配”“逆向匹配”“正向匹配”“双向匹配”等。本文主要以后三种匹配形式加以讨论。其中逆向匹配与最长匹配有着相似之处,即提取词句最长“连词”,且处理方向由句尾出发,将其转化为有效字符串予以匹配,此种方式照比其他字符串匹配方法准确性更高一些。而正向匹配是从句头进行匹配,先行将其拆解为多个汉字串,并结合词库中的分词标准将语句进行“断句”处理,若存在匹配词汇可将其提取出来用于计算机信息识别渠道,若不存在匹配词汇,则将其剔除出去,将剩余汉字串进行逻辑整合,以此作为检索依据查找信息。双向匹配属于一种“联合匹配”模式,它能有效消除歧义语义影响,增加字符串匹配结果的准确性。因此,应尽量推广双向匹配算法作为搜索引擎分词依据[2]。
此外,在借助基于字符串分词阶段,为了避免歧义的出现还可采用下述方法对搜索引擎应用中可能存在的歧义进行处理,确保过滤后的词义与用户搜索目标相一致。
比如在“人民的生活水平提高”中,总体上具有下述多种匹配形式:人民的-生活水平-提高、人民-的-生活-水平-提高等,在分词时可借助计算平均词长的方式确定匹配结果。平均词长具体以词组总字数与总词汇量的商值作为依据。比如在“人民的-生活水平-提高”中,其平均词长为“9/3”,而“人民-的-生活-水平-提高”为“9/5”,以最大值为分词结果,从而将其纳入搜索引擎系统中查找相关信息。虽然从上述内容中发现此种算法的确有着一定优势,但对于新词的识别率仍有待改进,并且还需要其他分词算法予以辅助,最终可增加中文分词算法的实用性,使其在搜索引擎应用中展现价值。
3.2 、基于N元语法分词
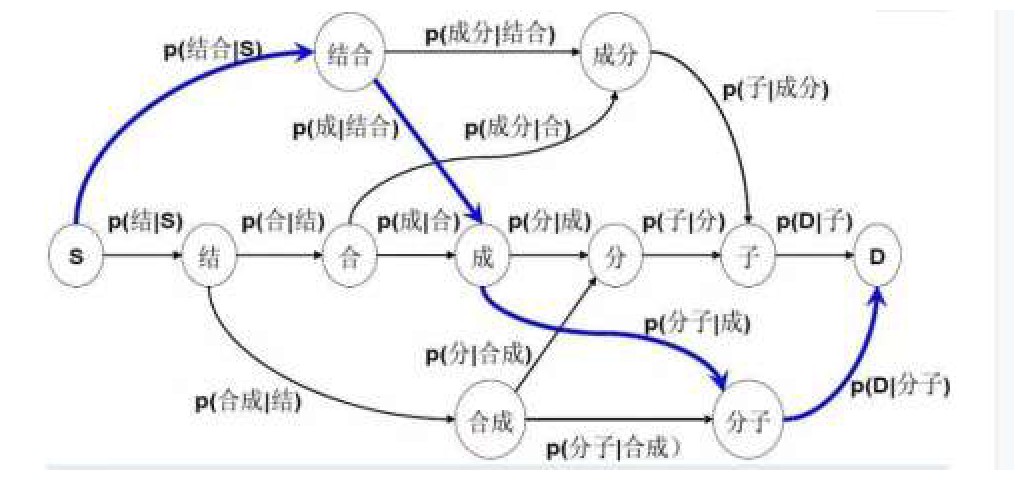
在搜索引擎应用中运用中文分词算法时,还可采用基于N元语法的分词形式实现中文字符的有效划分。它主要以一种“模型”思维,对检索词汇进行延展,进而在搜索引擎中实现精准识别。在此种方法下,同与上述分词算法同样具有词典,并按照一定的匹配原则对搜索词汇进行匹配,并设计“N元分词图”,之后借助动态设计的理念针对中文词汇进行“分解”,其整个分词流程如(图1)所示。同时,还可依靠“二元模型”的形式,对词句中涉及的“分子”进行整合处理,然后得出可靠的关键词,将其用于计算机系统识别。从多种中文分词算法切分准确率结果中可发现,在不同领域中,其准确率不一致,如(表1)所示,N元语法统计在各个学科信息检索中普遍具有较高的准确率,故而值得在中文搜索引擎中予以推广,促使中文分词算法发挥出真正的分词效用,避免歧义的产生。
此外,还可利用“一元语法”针对中文词汇进行切分,为了确保此种分词方法适用于搜索引擎应用过程中,还应适当重调最短路径与N元语法分词图中的节点数值,以便在适合的节点中合理确定“候选词汇”,以便在分词期间增加词汇统计的准确度。从以往研究经验中,还可采用“词性标注法”对语句中固有词性进行标注,包括上文中提到的“把手”中“把”为动词,在标注过词性后,也能提高搜索引擎中关于中文信息检索的可靠性[3]。
表1 各种分词算法的切分准确率
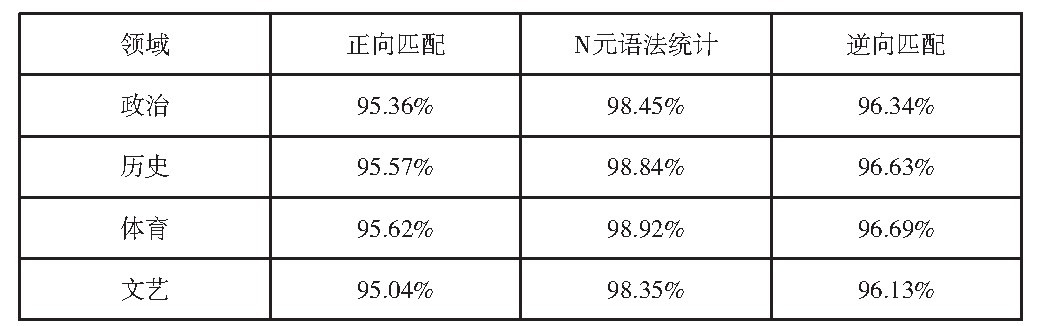
图1 基于N元语法分词算法的图解
3.3、 基于搜索统计技术
1)频率统计
中文分词算法是指将语句中的词汇切分出来,进而将其转化为“关键词”用于搜索引擎中,从而获取有效信息。其中基于搜索统计技术实现中文分词,是以“无词库”形式针对中文语句进行词汇划分。由于中文句意较为丰富,故而在统计词汇时,还可运用“词汇出现频率”作为划分基准。所谓词汇频率是指字与字之间结合次数,在其频率越高时,则代表词汇结合的可能性更大。
比如在对“中国人”“中国心”等词汇进行划分时,若此词汇出现在语句中,可根据它的出现频率判断是否将其作为关联词汇用于信息检索中。相比之下,运用频率统计的形式实现中文分词可适当提高词汇检索的速度与准确率。好比在“中华人民共和国万岁”中,由于与“中华人民”出现频率略高,可将其作为首次检索目标用于搜索引擎中,之后再对“共和国”“万岁”词汇的常规频率进行确定,以便在频率统计过程中有针对性地为搜索引擎提供重要检索依据[4]。
2)智能统计
在搜索引擎应用中运用中文分词算法时,还可依靠智能技术实施智能统计,它是以一种“模拟人体思维”的方式实现中文句意的深层次理解。与以往分词方法相比更具智能化,并且可有效避免歧义问题。我国汉字文化博大精深,尤其在新时代背景下,许多新词的出现造成搜索引擎在实践操作中面临着较大挑战,需随时根据信息变化予以更新。然而,此种智能统计的方式可对中文复杂性与综合性特征起到协调作用,以便在搜索引擎应用中为用户提供优质检索服务,使其快速从检索结果中找到相关信息。在人工智能技术日益发展阶段,智能统计已成为当前中文分词算法的主流发展趋势。但由于它需要以“中文理解”的视角开展中文分词工作。因此,无论从成熟度还是可操作性上都有待改进。
比如在“大哥大是团队领导者”中,以往常出现的词汇为“大哥”,而对于“大哥大”词汇相比之下出现频率较少。对此,若能依靠智能统计形式,可结合句子的含义判断出大哥大属于单独的词汇,由此增加检索精度。
4 、结论
综上所述,中文分词算法在搜索引擎应用中有着重要作用,故而应结合具体要求拓宽其运用渠道,以此为我国搜索引擎研究工作给予指引。同时,还应从基于字符串匹配分词、基于N元语法分词、基于搜索统计技术等方面着手,以便中文分词算法展现出显着优势,使其在提高搜索速度基础上增加信息检索准确性,以便大众在中文分词算法协助下快速获取信息。
参考文献
[1]王洪浩.中文分词算法在搜索引擎应用中的研究[J].中小企业管理与科技(下旬刊),2019(1):103-104.
[2]郑国兴.面向航天领域的中文分词算法研究与实现[D].西安西安电子科技大学,2019.
[3]刘桂梅.应用中文分词技术的网络推广管理系统的设计与实现[J]电子商务,2019(9):56-58.
[4]杨贵军,徐雪,凤丽洲基于最大匹配算法的似然导向中文分词方法[J]统计与信息论坛,2019,34(3):18-23.





