����ժ Ҫ�������������Ļ�������ҳ��Ϣ�ͳ�ǧ������û���ѯ���������������������ºͲ�ѯ���ʴ�����ǰ��δ�е�ʵʱ����ս.��Ч������ѹ���㷨�ܹ������������ݵĴ洢�ʹ��俪�����ӿ촦�������������ݵĴ����ٶȣ������ֱ��Ӱ����������ϵͳ�IJ�ѯ����.���ȣ������˵��������е���������������d-gap��freq�������еĴ洢�ṹ��������ѹ�����ֵĶ��뷽ʽ�Ե�������ѹ���㷨���з���;��Σ���ϸ�����˵�ǰ���е��ֶ���ѹ���㷨�����ܽ���Simple��Frame of Reference(FOR)��Optimized Chunk Splitting(OCS)�ȼ�����͵ĵ�������ѹ���㷨;֮�������˵�������ѹ���㷨��SIM D���л��о���������SIMDָ���Shuffle�����û��ʹ�ֱ���ִ洢�������㷨��d-gap�������еIJ��д�������.Ȼ�����ѹ����������������������⣬������ͨ�����õ�������������ԭʼ����ѹ���㷨���ֲ���.��Ե�������ѹ���㷨����������ϵͳ�е�Ӧ�ý����˷������ܽᲢ��δ����������ѹ���㷨���ܵ��о����������̽�ֺ�չ��.
�����ؼ��ʣ�����������; ��������ѹ���㷨; �ֶ���ѹ��; SIMDָ�; �������ṹ;
����Abstract����The ever-growing Internet web pages and tens of thousands of user queries have brought about huge challenges to the frequent index updates and real-time query processing in search engines. Efficient index compression algorithms can be used to reduce the costs of index storage and data transfer,as well as to accelerate the speed of CPU processing. In this paper,we present a survey on the techniques and algorithms on inverted index compression in decade,and expect to provide further research directions by classifying and summarizing the existing methods. Firstly,we outline the inverted index structure storing d-gap and freq integer sequences,and categorize the compression algorithms of inverted index according to the alignment of the compressed codewords. Secondly,we detail the most popular word-aligned compression algorithm,and summarize several state-of-the-arts,such as Simple,Frame of Reference( FOR)and Optimized Chunk Splitting( OCS). After that,the random access of the compressed inverted index is reviewed,and two commonused strategies are summarized,which are the self-indexing technique and the original sequence compression algorithms. Then,we reviewa recent research direction of the inverted index compression,i. e.,adopting the SIM D shuffle permutation instruction and vertical layout to parallel the common inverted index compression algorithms. Finally,we summarize the applications of the inverted index compression algorithms in the search engine systems,and discuss the possible future research directions of the inverted index compression.
����Keyword����search engine; inverted index compression; word-aligned compression; SIMD instructions; self-indexes;
����1 ������
����������������ҳ�����Ͳ�ѯ�������������������������dz������ս[1,2]���������е���ҳ������ָ����������������Ϊ�˱���������Ϣ��ȫ���ԣ���Ҫ���ϵزɼ��³��ֵ���ҳ��������������ҳ��Ŀǰ������������������Google���ٶ�����ҳ�������������˰��ڣ�����Ҳֻռ�������������в���10%����ҳ��Ϣ[3]������Netcraftͳ�ƣ�����2014��9�·ݻ��������Ѿ�ӵ�н�10�ڸ���վ1,2�����硶��43���й����������緢չͳ�Ʊ��桷ָ��������2018����ڵ���ҳ�����ʹﵽ2816�ڸ�����2017���������8.2%[4,4]�����������������ϸ�����ý����Twitter��Quora��֪����Ӧ�õ����չʹ����������ϵͳ�����������ݹ�ģ��һ������[5,6]����������������ҳ���ݵĴ���ѹ�������������ݷdz��Ӵ�ӵ�н�5ǧ�����ҳ��Clueweb09(B)���ݼ���ѹ�������ʹﵽ15GB(�����ʵ��ļ��͵����ļ�)��������˵�������������������ҳ�ĵ�����������[7]����Щ������������ҳ���ݸ���������ϵͳ�ĵ��������洢�ʹ��������˳�������ս���о�����[2,3,4,5,6,7,8,4]�����⣬��������ÿ����Ҫ�������ڴβ�ѯ�����൱��ÿ�봦����ǧ����ѯ��������Щ��ѯ����������Ҫʵʱ���ز�ѯ���[2]���������ݡ�������ѯ��ʵʱ��Ӧ��Ӧ���������������Ĵ洢�Ͳ�ѯ��������˺ܴ���ս[8].

�����о����������õ�������ѹ���������Լ���Ľ��͵����������ݵĴ��̴洢�ռ俪������ʹ��������ݿ��Ա����ص��ڴ���;ͨ����ϸ�Ч�Ľ�ѹ�������ܴﵽ�Ժ�������ѹ���������ݵĿ��ٲ�ѯ����[9]����ˣ���������ѹ�������ͳ�Ϊ�������������������ݴ洢�Ͳ�ѯ���ܵı�Ҫ�ֶ�[10]�����о���ԱҲչ���˴�����Ե�������ѹ���㷨��������������ϵͳӦ���е������Ż��о�[9,11]����������ѹ����������ֱ��������������ڵ���������ݵĴ洢���ܣ��ڴ����ϣ�����ѹ����������ʹ���ݵĴ洢���ӽ��ܣ���ͽ��������ݷ��ʹ����еĴ���Ѱ���ӳ�[12]������Ҫ���ǣ�����ѹ��ʹ�ø�����������ݿ���ֱ�Ӽ��ص��ڴ��У��ִ���������ô洢������Ϊ�������ṩ���ݷ���֧�֣����ϲ�Ļ�������С���ٶȺܿ죮�������²�洢����������������ٶȱ���[13]����������ѹ���ܹ�ʹ�ø�����������ݴ����ϲ�Ĵ洢����[14]�����Կ�������������ѹ������ʵ���Ϲ�ϵ����������������洢�����ºͲ�ѯ���ܣ���˶Ե�������ѹ���㷨���о�����ҵ�������湫˾��ѧ�������϶������ȵ����ѵ����⣮
�������ĶԵ�ǰ��������ѹ�������ķ�չ��̬�����������Ե�������ѹ���㷨��Ӧ�ý���ϵͳ�����ܽᣬ�������ܹ�Ӧ����һ�����о����ٵ��µ���ս��Ϊ��һ�����о������ṩ������
����2 ����ͳ��������ѹ���㷨
������ӵ�д��ģ�������ݵ����������У�����������֤����һ�ַdz���Ч�����ݽṹ[15,16,16]�������ĵ���������Ҫ�ɴʵ�͵���������������ɣ��ʵ��ɴ����Ĵ�����ɣ���Ҫ������¼�����ĵ������г��ֹ��Ĵ���Ͷ�Ӧ�ĵ�������ָ�룮����������¼�˸ô����ڲ�ͬ�ĵ��е�������Ϣ��λ����Ϣ����Ԥ�����������Ϣ����ʵ��Ӧ���У��ʵ��ļ��������ļ���˵ͨ��ҪС�ö࣬���Ե�ǰ�о���Ա��Ҫ�����ڶԵ�������ѹ���㷨���о�[17,18]�����������洢�ڴ����ϣ�ÿ���Ӵ��̶�ȡ�����ݿ�(block)����һ�������ĵ������������ݶ�(data chunk,DC)��ÿ�����ݶ���Ϊѹ���㷨�����Ļ�����λ��������һ����ѹ�����������У�ÿ�����ݶΰ���һ��docid�Ͷ�Ӧ��һ��freq��ͼ1�����������������ݿ�����ݶεĹ�ϵ��
�����ڵ�������ѹ�������У���������������ĵ���(docid)��Ϣ������ÿ������ĵ��������еĵ�����ĵ��Ŵ�С����������У���ʹ���ڴ洢�ĵ���docid��Ϣʱ�����Դ洢�ĵ���docid֮��IJ�ֵd-gap����������������ѹ���ʣ��ĵ����ż�������ʹ��d-gap��ֵ��һ�����Ͷ���������������ѹ����[19,20]������Shannon�ķ������ֲ�����ΪP(x)�����ֵ�����ѹ�����س���Ϊ[12];���⣬��������ҳ�д�����ĵ�Ƶ�ʷ���Zipf����(�ݶ���)[21]����ˣ���������ѹ����Ŀ�ľ��Dz��þ����ܽӽ����ű��س��ȵı�������ʾһ��ԭ����32��64λ�����ֱ�ʾ��d-gap���������dz�ѹ��״̬�µı���Ϊ����(code word).
����ͼ1 ���������ṹ�����ݿ�����ݶι�ϵͼ
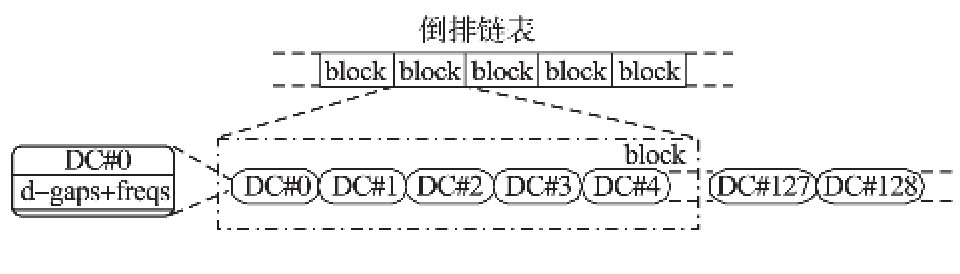
����Fig.1 Inverted lists of data blocks and data chunks
������ͳ�ķ���ѹ���㷨��Huffman���롢�������롢PPM�Ȱ뾲̬��������Ӧѹ��������ҪԤ��֪����ѹ�����ŵ�ͳ����Ϣ��������ѹ��ģ�ͣ�����������ҳ�Ͽ�ĸ����ٶ�ʹ��d-gap���в��ȶ�����Ϊÿ����������d-gap���б���һ���ȶ���ѹ��ģ��[22]�����⣬���Ӹ��ӵĴʵ䷽����LZ77��LZW��Ҳ����Ӧ���ڵ�������ѹ���У�������Ϊ��������d-gap���е������ظ���Ҫ�ȷ�������С�ܶ�[23]����ˣ���������ѹ���㷨���о���Ҫ�����ڲ���Ҫͳ����Ϣ��������ѹ��(light-weighted compression)[24,25]������������ѹ���㷨�����ֶ���ķ�ʽ���Է�Ϊ:���ض���(bit-aligned)ѹ���㷨���ֽڶ���(byte-aligned)ѹ���㷨��
�������ض���ѹ���㷨Ϊ����ÿһ����ѹ����������һ����Ӧ�����֣���ѹ���Ĺ��̾��൱�ڶ��������еķ����滻����Щ��������ѹ����ģ�ͣ�һ����Է�Ϊȫ�ַ����;ֲ�������ȫ�ַ��������ֲ��������������У������е����붼ʹ��ͬһģ�ͽ���ѹ���������㷨��Unary��Gamma��Delta��Golomb��Rice��[12,22,26,27];�ֲ��������������ı仯�ʵ�����ģ�͵IJ�������Interpolative Code[28]���ֲ�ģ����ѹ��Ч������Ҫ����ȫ��ģ�ͣ�����ѹ���̵�����Ҫ��ȫ��ģ�Ͳ����ѹ���㷨���нϸߵ�ѹ���ʣ����ڽ�ѹ��ʱ��Ƶ����λ�����������ؽ���Ч�ʣ�
����Ϊ�˼ӿ�ѹ���ͽ�ѹ�ٶȣ������������ֽڶ���ѹ���㷨����Varint(�ֳ�Ϊvariable byte����vbyte)��Group Varint��[1,29,30]�����ǵĻ���˼����ʹ���ֽڵĵ�7λ���洢���ݣ����λ��Ϊѹ�������ı�ʶ�����ֽڶ����ѹ����ʽ���ܻ��˷�һ���ֿռ䣬����ѹ���ٶ�ҪԶ���ڱ��ض���ѹ���㷨�����ֽڶ���ѹ���㷨�Ļ����ϣ�Google��˾��������õ�Group Varint��������ѹ���㷨���Դ������Varint�Ľ�ѹ����[1]����ͨ����ԭ����Varintѹ����4�����ָ�Ϊһ����ѹ������һ�����ٷ�֧�жϣ����Ӳ����(hard-coding)����λ(shifting)�������Դﵽ���õ�ѹ��/��ѹ���ܣ�������ΪGroup Varint�Զ���ֽڵ�״̬λ����ͳһ�洢�������Ϳ����ڵ������ݲ�����ѹ��������֣���Ҳ����һ����ѹ���������������ѹ���ͽ�ѹ�����ܣ����⣬�о���ԱΪ������㷨��ѹ���ʶ������Nibble Varintѹ���㷨������4������Ϊ��λ������Varint�Կռ���˷�[31]�����ض���ѹ���㷨�ܹ��ﵽ�ϸߵ�ѹ���ʣ����ֽڶ���ѹ���㷨�ܹ��ﵽ�Ϻõ�ѹ��/��ѹ�ٶ�[22]��������ѹ���㷨������Ե�����������ѹ����ѹ�����������ڽ�ÿ�������滻Ϊ��Ӧ�����֣�
����Ӳ�������λ�������㷺Ӧ���ڸ��൹������ѹ���㷨���Դﵽ�㷨ѹ���ͽ�ѹʵ�����ܵ�����[7,32]�����У�Ӳ������ָ��ѹ���㷨��ÿһ�����ģʽ�ĸ���������Ϣֱ��д�������ѹ���ͽ�ѹ���̵�ѭ���ͷ�֧�жϿ�����ͨ��Ӳ�������λ�������Ա���ѭ���ͷ�֧�жϵĿ�������1�ͱ�2�Dz���Ӳ����/��λ�����Ķ�5����������ѹ���ͽ�ѹ�����ӣ����ڸ����Ĵ�ѹ���������У�ͨ����������������λ���Ϳ�ѹ�������������м����ȷ�������������ģʽ(padding mode).
������1 compress��69�㷨α��

�����ڱ�1��ʾ��ѹ�������У�������5���ɵ���ѹ��������(d[1]��d[5])�����ģʽ��״̬��Ϣs(s=69)���㷨�������ģʽ��λ����������Ϣ��5��������λ�����Ե�Ԥ�������(padding slot)��Ȼ�����ģʽ״̬��Ϣs�洢������ͷ���������ڽ�ѹʱͨ����λ�����Ϳ��Ի�����������õ����ģʽ��
������2 decompress��69�㷨α��
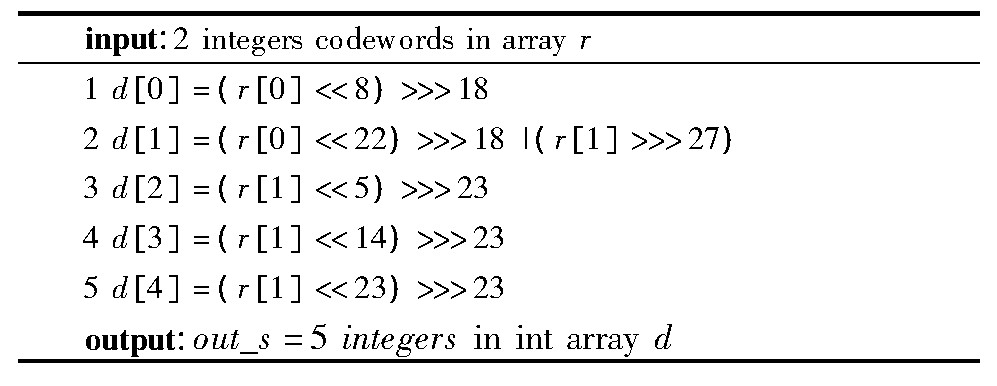
�����ڱ�2��ʾ�Ľ�ѹ�����У�����2������r[0]��r[1]��ÿ��������ѹ��״̬�µ�λ������ѹ��������������Ϣ��Ӳ��������������ͨ����������λ��ȡ�����д洢�����ģʽ��״̬��Ϣ��֮��ѡ���Ӧ��Ӳ�����ѹ�㷨�������ѡ���Ľ�ѹ�㷨������Ԥ���趨�õ�����������Ϣֱ����λ�Ϳ��Եõ�5��������
����3 �������ֶ���ѹ���㷨
����Ŀǰ����������ѹ���㷨�б��㷺�о��Ͳ��õ����ֶ���(word-aligned)ѹ���㷨��������ڸ�����32λ��64λ�����ֳ���һ�δ������������Ϣ��������ѹ���㷨��Ϊ���յ��������ֶ������ѹ��(�ǹ̶�������������ѹ��)�Ͱ��չ̶�������������ѹ�����࣮���յ��������ֶ���ѹ������Ҫ˼���ǽ������������ѹ����һ��32λ��64λ�������ڣ���Simpleϵ��ѹ���㷨[33,34,35,36,37]�����չ̶�������������ѹ������Ҫ˼����ѡȡ32m(mΪ������)���������е�λ��ѹ����ͬʱ��֤����ĩβ���ֶ���ģ���FORϵ��ѹ���㷨[32,38,39,40]�������ֶ���ѹ���㷨�Ľ�ѹ���̾��ɲ���Ӳ���뷽ʽ������CPU��֧�жϵȲ����Ĵ��������������������ֵ��͵��ֶ���ѹ���㷨��
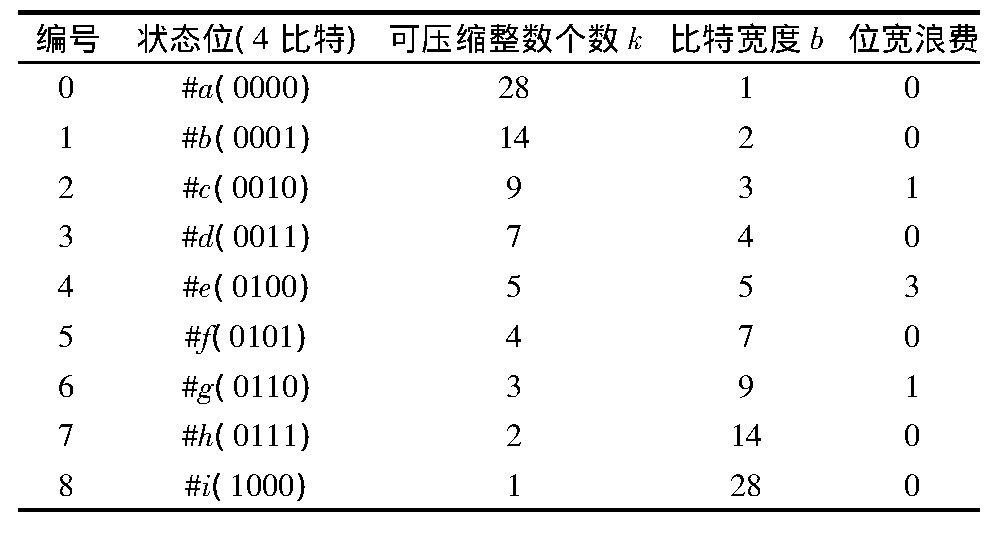
����Simpleϵ��:��ϵ��ѹ���㷨�����Anh��Moffat���������Simple-9ѹ���㷨[33]����Ľ�ѹ���㷨��Carryover-12��Slide��[34,35,36,37]�������˼���ǽ������ܶ������ѹ����һ����һ��32λ�������У����3��ʾ��Simple-9ѹ���㷨ʹ��4������Ϊ״̬λ����������28������λ���γ�9�ֿ��ܵ�����λ���ģʽ��ÿ�����ģʽΪÿ����ѹ������������̶��ı��ؿ��ȣ���ѹ��ͨ��״̬λȷ�����ģʽ����ȡ����λ�洢������������ѹ���ͽ�ѹ���̲���Ӳ���뷽ʽ������ѭ���Ĵ�����Simpleϵ��ѹ���㷨��ÿ�ο�ѹ����������������õ����ģʽ��ͬ����ͬ����ˣ�Simpleϵ��ѹ������ʵ�������������ģʽ�Ե�����������“̰��”����(left-greedy partition)���ֱ�ѹ����Ϊ�˽����������ѹ����һ���������в����̶����ؿ��ȴ�����λ���˷ѣ��о���Ա������ڶ���и�Ϊ�ḻ���������ģʽ�ĸĽ��㷨������Carryover-12��Slide��Simple-16��Simple-8b��[33,34,35,36,37]��������Simple-8b��Ϊ��Simple-9��64λ�������ϵĸĽ�������4���ص�״̬λ������60λ����λ�IJ�ͬ���ģʽ[35].Simple-8b��Ϊ����64λ�����ֶ�ѹ�����н��д����������˵��οɱ����������������Simple-8b���Simple-9�ܹ����Լ���CPU��֧�жϵĴ�����������ѹ���ͽ�ѹ�ٶȶ�����Simple-9�㷨��
������3 Simple-9�в��õ�9�����ģʽ
����FOR(Frame Of Reference)ϵ��:��ϵ��ѹ���㷨�ֳ�ΪBinary Packing��Packed Binary����Null Suppression[7,41]������Ҫ˼���ǰѴ�ѹ���������л���Ϊ���������ݶ�(һ��Ϊһ�����̷�ҳ������ܰ���216=65536������)��Ȼ���ö������λ������ʾ��������[38];PFOR��Ϊ�˿˷���ijЩ�ֶ��г��ֵ��쳣ֵ����ʹ�����ֶβ��ù���λ�������⣬�������ֶηֳɽ�С������ֵ�ͽϴ���쳣ֵ�����֣��쳣ֵ�ĸ���ͨ��ȡ���ݶγ��ȵ�10%�����У�PFOR����ֵ�Բ��ö���ѹ�����쳣ֱֵ�Ӹ��ڷֶε�β����ʹ��32λ����������ʾ[39];Zhang���˸Ľ���ԭ����PFOR(Lemire����[7]�Ƹ��㷨ΪPFOR2008)��ʹ��ÿ��ѹ�������ݶγ���Ϊ128�����Ҳ���8��16����32������ѹ���쳣ֵ[34].New PFD��OptPFDҲ�����ݶγ��ȶ�Ϊ128�������쳣ֵ��������֣����ѳ�������ֵ�IJ�������β��������Simple-16����ѹ��;��ͬ����New PFDѡ��10%���쳣ֵ����OptPFDͨ��Ȩ������ֵ���쳣ֵѡ�������ʵ������ѹ��Ч��[19];Fast PFOR��SimplePFOR���ǰѶ���ֶε��������ֱ�ѹ�����쳣ֵ����γ�һ����ҳ(Page)����ѹ������ͨ���ڽ�ѹʱһ����ȡ�÷�ҳ�ӿ��ѹ�ٶ�;��ͬ����SimplePFOR����Simple-8bѹ���쳣ֵ����Fast PFOR����32�в�ͬ���ȵ�λ���������ֱ��Ų�ͬ��С���쳣ֵ[7]���ܵ���˵��FORϵ��ѹ���㷨��ÿ�ο�ѹ��������������һ���ģ�������ڵȳ�ѹ���㷨��
����OCS(Optimized Chunk Splitting)ϵ��:FORϵ��ѹ���㷨���нϸߵĽ�ѹ���ܣ�������Ϊ����Ե��δ����ϳ�(��:128��256��)���������У��������ӵ��ο�ѹ�������ĸ������ܻ���ɸô�ѹ�������ݶ��д��ڽϴ���쳣��(exception)���Ӷ���Լ���㷨��ѹ���ʣ�Ϊ�˽����쳣ֵ���ȳ�ѹ���㷨������λ���˷����⣬�о���Ա������ڵ����������ֵ��Ż�ѹ�����������Ż�����Ѱ�����ŵĵ����������ݶλ��֣�ÿ�����ݶ��ڲ����õ����ĵȳ�ѹ���㷨����ѹ����ͬʱ��֤�����Ķ�����ݶ����ֶ����[8,42].Rossano Venturini���������VSE���������������ʹ�ö�̬�滮����Ѱ���������ݶλ���[32]������ȫ���Ż��ļ������̫�ߣ�ʹ����������ʱ����ӳ���Renaud Delbru���������AFOR���ù̶����ȵĻ������ڷ�ʽ���������ݶΣ�����˵���Զ�̬�滮���ֲ����ŵİ취��������ߵļ������[40].Gonzalo Navarro�о��Ŷ������DACsʹ���˺�VSE��ͬ��˼�룬�������ݶ��ڲ�������Varint���Ƶ��ֽ�ѹ����ʽ��ͬʱ�Բ�ͬ���ȵ����ֹ����ֲ�ṹ��ʵ��������ʵ�Ч��[43];Rossano Venturini���˽�һ�������PEF��CEFѹ���㷨�Ż���Elias-Fanoѹ���㷨[44]���ڻ���ʱ��������������������ͼ(DAG)���������˽��Ƽ���ķ���������ʱ����������Ż���[45,46].e Bay��˾Andrew Trotman����ͨ���������ڴ浹���������л����Ż�������Simple-9ѹ���㷨��ѹ���ʣ����Ǹ÷���δ�ܹ����Ǹ���ͬ�������ڶ��൹����Ϣ����ѹ���洢������λ���˷�����[47].
������4 �����ֶ���ѹ���㷨�Ա�

�������������������������ʵ�飬��4��������������ֶ���ѹ���㷨�����ܶԱ�[48].FORϵ��ѹ���㷨��Ȼÿ�ο�ѹ�������������ǹ̶��ģ�������ѹ����������ռ�õĻ����ֳ��Dz�ȷ���ģ����Խ����̵��������ֿ������ڴ�IO�����(buffer pool)�ͻ���������ڽ�ѹʱ�Ļ���ؿ���д�����[49,50]����Ŀǰ������������ϵͳ�к��������������ݵĴ洢�Ͳ�ѯӦ�û����£���һ�����ڴ���ѹ�����������IJ�ѯ�����л���Լ���ֵĽ�ѹ���ܣ���ʱ��Simpleϵ��ѹ���㷨���FORϵ��ѹ���㷨����������������:
����1)�����ģʽ����ϸ�������Խ��ͽϴ��쳣������������������ѹ��λ�����˷�����[7,32,34];
����2)��ѹ�������ܹ��������ڴ�IO����صĶ�д���ݿ���룬���Ա����д����ѹ��������������ʱ�Ŀ����ݿ��ѹ����[22,39,51].
����Ȼ����Simpleϵ��ѹ���㷨��Ȼ�������µ�����:
����1)�ڽ���ѹ���������ȵĶ��൹����Ϣʱ���ڹ���ķ�֧�жϺ�ѭ�����õȿ���;
����2)������ѹ�����ཻ��������Ϣʱ�������ص�λ���˷����⣬�������õ�“̰��”���ַ������ﵽ���ŵ�ѹ��Ч����
����3)�ڸ��������ֳ��ڿ�ѹ�����������IJ�ȷ����ʹ�����������ṹ�������Ż������д���ͬ������͵�ַƫ�����Լ�����������[48,52].
����4 ������SIMDָ���ѹ���㷨
����Ϊ�˸�����Ч�����������������ܣ�����ھ���������п��ܴ��ڵIJ��в������ִ��������������˶��ֲ��нṹ��SIM Dָ���ܹ���������������ʵ�����ŵ����ܼ���[53]��������˵������ָ���ֻ�ܴ�����һ���ݣ����ܹ���һ������������ͬʱִ����ͬ������Intel�Ƴ���SSE��AVX��չָ��Ϊ�����������������ܼ���Ӧ�ô��������Ե���������[54]�����磬SSE����ָ��ʹ����128λ�ļĴ���������һ�β��д������32λ������������Ա������Ҫ�����ṩ��C/C++���ʽ���ڽ�����(Intrinsic)�Ϳ���ʵ�ֻ���SIM Dָ��IJ��л�����[55]����ǰ��������ѹ���㷨��һ���о��������ͨ������SIMD����ָ����������и������ĵ�������ѹ���㷨����ִ�е��ٶȣ�
�������������ѹ���㷨����SIMD���л��Ĺ�����Willhalm����[25]��������������ڴ����ݿ��н��ȳ�λ��ѹ��(��FOR��)����������SIMD�����û�ָ����п��ٽ�ѹ�㷨������̰�������ѹ�����ݵ�128λ��SIMD�Ĵ���������Shuffle�����û�ָ���SIMD�Ĵ����е����ݽ������´洢����������ı���λ�����в��л���������ȡ��Schlegel����[56]����SIMDָ��ͬʱ����k�������ı��룬���������ѹ�����ݵĴ�ֱ�����������ѹ�����д�����SIMD�����û�ָ����������������Null Suppression��Elias Gamma���ֱ���Ľ�ѹ���ܣ�Stepanov����[57]���ñ�־λ�Ĵ洢��ʽ�ͱ��뷽ʽ���ֽڶ���ѹ���㷨�����˷��࣬������һ��������ͨ��SIMD�����û�ָ��(Shuffle)�����SIMD-GVB(����3������SIM D-GB��SIM D-G8IU��SIM D-G8CU)����ѹ���㷨��Lemire����[7]��������ֲ������ִ�ֱ����(Vertical Layout)��SIMD�����û�ָ����в��л���ѹ���㷨������SIMD-BP128*�ܹ��ﵽ��δ���л�������ѹ���㷨varint-G8IU��PFOR��2���Ľ�ѹ�ٶȣ�SIMD-FastPFOR���Simple-8b�ܹ��ڱ�֤�ϸ�ѹ���ʵ�����´ﵽ2���Ľ�ѹ�ٶȣ����Lemire����[58]���о�����ͬʱ����4�����ֵĻ���SIMD��S4-BP128��S4-FastPFOR����ѹ���㷨��4�ֲ�ͬ��ֱ�������µ����ܣ��Լ���������ĵ���������(Intersection)�㷨�е����ܱ��֣�Trotman[59]���SIM D-BP128*ѹ���ʽϵ͵����⣬�����һ�ֻ���SIMD��ѹ���㷨QMX�����������128���صĸ��ֻ���(Quantities)��ָʾλ�ļ��д洢��ʽ(e Xtractors)���Լ�ͨ���γ̱������洢�ظ�����(Multipliers)�����ͨ������SIMD�����û�ָ����ʵ�ֶ����������ݵĿ��ٴ�����
�������ڶ��ڻ���SIMD�ĵ�������ѹ���㷨�о�����:�Ͽ���ѧ�ŕ�����[60,60]�Լ�Ao����[61]����SSEָ���AVXָ��ʵ����Simple-9��Simple-16��PFORDelta��BP�IJ��н�ѹ�㷨�����ж��ڲ����㷨�����˴�ֱ��������һ�������㷨�������������ܣ�ʣ����㷨����SIMD�����û�ָ����ʵ�ֲ��л����ݷ��ʣ�������ѧ�ƺ�ɵ���[62,62]ͨ��SIMD�����û�ָ��ʹ�ֱ�������ַ�ʽ��Packed Binary��PFORDelta�����˲��л����õ������ԵĽ�ѹ���ܸĽ������µ��о���Zhao��Zhang����[63,64]����SIMD����ָ�����һϵ�з���ѹ���㷨:Group-Simple��Group-Scheme��GroupAFOR��Group-PFDelta����Щѹ���㷨���ո���������������ֵ�λ�������з�����е�λ����ֱ�洢��������Ȼ���ѹ���ܵõ������������ǻᵼ�²���ѹ���㷨��ѹ������Ƚ�δ���л���ԭѹ���㷨��һ������ʧ��
����5�� ѹ������������������ʲ���
������������ѹ���㷨������ҪӦ������������ϵͳ�еģ���Ϊ�˱�֤���õ��û����飬����������ƾ������ģ������������������ȿ���ϵͳ�IJ�ѯ����ָ��[2,10].Stefan Büttcher����ָ����������ѹ���㷨�������������ܽ����ǶԵ����������γɵ������������е�ѹ���������뿼�Ǻ������̵�������������������ѯ�ṹ��ʵ��Ӧ�û���[65].Jimmy Lin�����о����֣��ڸ���ͬ�������ڵķֶε�����Ϣ�����洢�����£�Simpleϵ��ѹ���㷨�����ģʽλ���˷�����Ҫ���ڴ�����ѹ�����������Ҫ���صĶ࣬��������¿���Ӱ��ѹ���㷨�ڵ���������ѯ�е�����[66].
����ǰ��������Ϊѹ���㷨�Ľ�ѹ�ٶ���һ���̶��ϼ���������������IJ�ѯ�ٶȣ�������ʵ��Ӧ���в�����ȫ��ˣ�����������IJ�ѯ�����У�����ֱ���ڴ���Ѱ���ķ�ʽ���������ݽ��з�������Ҫ��ʱ�����������ܵģ�����Ƚ��洢�ڴ����ϵĵ�������ȫ�����ص��ڴ��У��ٶԼ������ڴ��������������������ȫ��ѹ֮���ٽ��в�ѯ�����Ļ������������ݼ���ʱ�佫�Ӿ��û��IJ�ѯ�ȴ�ʱ��[67]�����ѹ����������������������⣬�о���Ա������������������о�:Ϊ������������������ͬ�������������������(Self-Indexes)�Ϳ��Զ�ѹ�������������оֲ���ѹ��������ʼ���(Random Decoding).
����5.1 ����������������
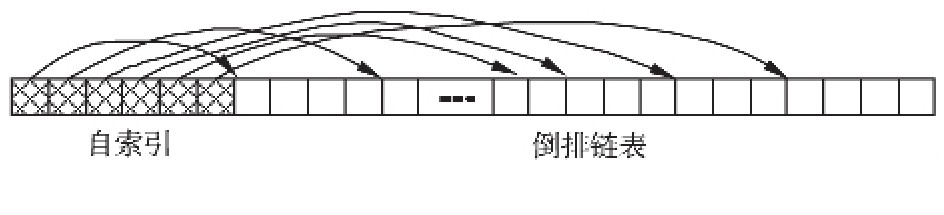
����Ϊ�˶�ѹ��״̬�ĵ����������и�Ч��������ʣ�Moffat��Zobel����Է�ѹ�������������еȳ��������γ��������ṹ��֮���о������ŵ��������ṹ����[68]��ͼ2��ʾΪһ���������ṹ�������Ϳ����ڲ��ҹ�����ͨ���������ṹ��λ������������Ŀ�����ݶΣ���ͨ�����ֲ��������ݶ��ڲ���λĿ���ĵ��ţ�Strohman��Croft�о���Impact-Ordered�����ṹ�ϵ��������ṹ����[69].Boldi��Vigna�����һ����ת�������ṹ���÷���ͨ����ÿ�����ݶε��������ṹ���е����γ���״�ṹ���ڲ��ҹ����п��Դ��ϵ����Ƚϣ�ȷ��λ��������ݶ�[70].Dimopoulos����Ϊ���о������������ڴ��еIJ�ѯ���⣬�������������ṹֻ�DZ���ÿ��ѹ�����ݶε����ĵ��ţ��������������ṹ��������ѹ���洢[71].Jonassen�����о���PFOR�ȳ����ݶ�ѹ���ĵ����������������ṹ��������[72]����ѹ���洢�ĵ������������������ṹ�ܹ����ٴ��̶�ȡ������������ʹ���������Ա����ص��ڴ��н��з��ʣ��������ṹ���ǿ��Խ�ʡ�����Ľ�ѹʱ�䣮Bortnikov�������������Ӧ�������ṹ�ܹ��ڴ�ͳ��������Treap������֮�䶯̬�л���ʵ�ֻ�������ת���Ҳ������Ӷ�ΪTop-K��ѯ�Ż��ṩ���õ�ѹ�����������������[73].
����ͼ2 �������ṹʾ��ͼ
����5.2�� �ֲ�������ʼ���
����ǰ����ѹ���㷨����������ĵ���֮��IJ�ֵd-gap��Ϣ����ѹ��������d-gap�����ѹ���ʺͽ�ѹ������Ч�����ţ�����������ǰ��Ԫ�ص������ԣ����½�ѹ���̱��봮��ִ�У���ʵ�ֶ�����λ�õ�Ԫ�ط��ʣ���Ȼ���������������������ṹ����һ���̶���ʵ�ֵ���������������ʣ�����ȴ����ÿ��ѹ�����ݶ��ڲ�����������������ʣ�Ϊ�˽����һ���⣬�о���Ա����˲�����d-gap��Ϣ��ֱ�Ӷ�ԭʼ�������н��д�����ѹ���㷨�����У�DACs�������ĵ���(docid)����λ����ͬ�ֲ�洢�����ö�̬�滮�ķ�ʽ�������ֲ�ĸ����Լ�ÿ���ֲ��λ������Ϊ��λ���ĵ�λΪ�ֽڣ�������ѹ������Ȼ�ϲ�[43];Interpolative Code�����������������IJ�ֵȷ���м������ı��볤�ȣ��Ե����������������н��н��յĵݹ���룬���㷨��Ŀǰѹ��Ч����ߵ��㷨[28];��С��������ʹ��Interpolative Codeѹ���ķ������Եȳ����ݶ�ѹ���ĵ�������ʵ���������[74,75,74]�����µ�Quasi-Succinct Indices[44]��Partitioned Elias-Fano Index[45]��Դ��Elias-Fano����[76]�����ǽ���������������������ָ���ij��ȷֳɸ�λ�͵����㣬��λ������������ʽ˳��д��ѹ���ļ�����λ���մ�Сӳ�䵽��ͬ�Ĺ�ϣ�ֶ���ͳ����Ŀ��λ�ã����ͨ��������Rank/Select��Ϣ��Ч��ʵ��ѹ��������������ʣ�
����6�� ��������ϵͳ�е�ѹ���㷨
�������ŵ���������ģ�IJ������ӣ�����ѹ���㷨�����ϵ��κ����������Լ������������Ӳ������ɱ�����Ȼ��������ѹ���㷨����ࡢ�������ƣ���������ʵ��������ϵͳ�е�ʵ�ֺ�Ӧ�û���Ҫ���Ǻܶ����أ���:Ӳ����ʵ�ֻ����������ṹ��[7,10]����������ҵ���ǿ�Դ�������棬����Ҫ��Ժ������ݡ�������ѯ��ʵʱ��Ӧ��Ӧ������������ѹ���㷨��ѡ����ҪȨ��ѹ���ʡ�ѹ���ٶȺͽ�ѹ�ٶ�����������أ����Ȩ��ѡ����ʵ�����ѹ���㷨����ҵ�������湫˾��ѧ���϶������о����ȵ����ѵ�[9]���������������ѹ���㷨����ijһ����ָ���ϱ���ͻ������������ѡ��ѹ���㷨����Ҫԭ����ϣ���ܹ��ڸ�������ָ��֮��ȡ��һ��ƽ��[77]����ǰ������ҵ�������������õ�����ѹ���㷨������ҵ���ܶ����������������ǿ��ԴӴ�����Դ��������ϵͳ�еó���������ѹ���㷨��ѡ����ԣ�
������ǰ���еĿ�Դ��������ϵͳ����϶࣬ʹ��Java���Ա�д����Lucene��MG4J��Terrier��ʹ��C/C++��д����Xapian��Zettair��Indri�ȣ�Lucene�ṩ�˰���Gamma��Delta��Varint�ȶ����㷨��֧�֣�Ĭ�ϲ�����Gamma������ѹ������������[78]��ԭ��M G4J����Golomb������ѹ���������ݣ�ͬʱҲ�ṩ������ѹ���㷨��ʵ�ֽӿ�[79]����MG4J��5.0�汾��ʼʹ����Quasi-Succinct Indicesʵ�ֵ����������������[44].Zettair��Galago�ж��ڵ������������ɵ�d-gaps���ý�ѹ���ܽϺõ�Varint����ѹ����������Gamma��Delta�Դ�Ƶ��Ϣ����ѹ��[80,81].Terrier-v5.1ʵ����һ������ѹ���IJ�������а�����ǰ���ֳ�������PFOR��Simple�ȵ�������ѹ���㷨����Ĭ�ϵ�����ѹ���㷨������Gamma���룬ͬʱ�ṩ�˽���ѹ������ת���Ĺ���[82].Lemire��������M offat����[35]�����з����������ɵķ���ʵ����һ������ѹ���㷨��Java���Է������ƽ̨�����а����˳��õĸ���ѹ���㷨ʵ��[7]������Lemire���˻�������һ��C++����ʵ�ֵĻ���SIMD��ѹ���㷨���Կ��3.Catena���˶Գ����ĵ�������ѹ���㷨��Terrier��������ϵͳ�е����ܱ��ֽ����˱Ƚ�ȫ��IJ��Ժͷ���[48]�����ϵ�������ѹ���㷨�ڿ�Դϵͳ�е�Ӧ�ÿ�����Ϊ���е�������ѹ���㷨�о���ʵ��IJ��գ�
����7�� �ܽ���չ��
������������Ϣ�IJ��Ϸḻ���������������ݵij������ӣ�Ϊ�µĵ�������ѹ�������ķ�չ�ṩ�˳־õĶ������ۺϹ������о���״���Կ������������������ѹ�������������Ż�������Ҫ��ע�˶��������е�ѹ����ȴ���������е�������ѹ���㷨����������ϵͳӦ���д��ڵ���:�����������̷ֶδ洢�����൹����Ϣ����ѹ����ѹ�������������ṹ��ʵ���������Ե�������ѹ���㷨�ڴ洢�Ͳ�ѯӦ���д��ڵ�ʵ������չ�����۷����о������ܲ��ԣ���Щ����Ľ���������ƶ������ֶ���ѹ���㷨�ڵ��������洢�Ͳ�ѯ�еĹ㷺Ӧ�ã������ڽ����������ѹ���������ݵĿ��ٲ�ѯ�������⣬�������������������ϵͳ���ܺͷ�������������Ҫ��ʵ�����壮�ۺϹ������о���״����������ѹ���㷨��ǰ����չ���ͽ�����Ҫ�о����������¼�������:
����1)��������ѹ���㷨�����������ѯϵͳ�е�ʵ��Ӧ�����⣬��:�о�֧�ֵ�������������ʵĵ�������ѹ���㷨[75]����Ϊ֧��������ʵ�ѹ�������������Լ��ٲ���Ҫ���ڴ����ݼ��أ���������������ѹ�����������IJ�ѯ����;ͬʱҲ�����ڵ�����������(��SvS�㷨)�и���AND��ѯ�������������߸Ľ���ʹ�õ�ѹ���㷨[58]�����������ѯ�жԲ�ͬ�����������ߵ����������ݶη���Ƶ���Dz�ͬ�ģ����ڲ�ͬ��ѯ����Ƶ�ʵ��������ݲ��ò�ͬ��ѹ����ʽ�Ϳ���ʵ�ָ���ϸ���ȵ����ܵ��ڣ���Ȩ��������С��ѹ���ٶȺͽ�ѹ�ٶȵ�����ָ�꣬�Ӷ��ﵽ���õ�ʱ��Ч��[77,83].
����2)�����µ�ָ��ܹ��Ż���������ѹ���㷨�����ݴ����ܹ���һ������ѹ���ͽ�ѹ���ܣ��������ø������ṩ�Ŀ⺯��ʵ�ֵĵ�������ѹ���㷨�����ݵIJ������Ƚϴ֣������ڵ�������ѹ���㷨�������Ż������Ŵ����������IJ��Ϸ�չ���µ�SIMDָ�(SSE����AVXָ�)�����㵥Ԫ(GPUоƬ����оƬ������[84])�ȵĸ��½�������µ�ָ����л����ԣ�����:����Intel CPU��SSE��AVX����ָ�����:����ļĴ������ȡ�����Shuffle�û�ָ��ʹ�ֱ���ִ洢������[54]�����Դӻ��ָ���������������еĴ洢���֣��������ڴ�ͼĴ���������ԡ�ָ��ı���λ�����ȼ����������������������еIJ��л�ѹ���ͽ�ѹ�������ܣ�
����3)���ڴ�ͳ����ѹ��������¼�����������������������ѹ���㷨�����ܣ����ִ�ͳѹ�������е������ۺͷ�������Ӧ���ڵ�����������������ѹ�������ⷽ��Ĺ�������:Zhang��������Ļ������������ķ�(Context-free Grammar)�ĵ�������ѹ������[85];Moffat��������Ļ��ڲ��Գ�����ϵͳ(ANS)�ĵ�������ѹ������[86,87];Pibiri�������ø����ָ�(Plurally Parsable)��������˻��ڴʵ�ĵ�������ѹ������[88]�������о���Ҫ���մ�ͳ����ѹ�������۲������������о���̬�����ǵ���������ѹ������������Ҳ��һ������ķ������У����ô�ͳѹ��������¼����������۷����ĵ��š���Ƶ���������еĴ洢���ԣ��Ϳ��ܴ��µĽǶ�������������������ѹ�����ܣ�
���������
����[1]Dean J.Challenges in building large-scale information retrieval systems:invited talk[C]//Proceedings of the 2nd International Conference on Web Search and Web Data M ining,2009:1-1��
����[2]Jake B.Speed matters for google web search[EB/OL].https://services.google.com/fh/files/blogs/google_delayexp.pdf,2009��
����[3]Bosch A,Bogers T,Kunder M.Estimating search engine index size variability:a 9-year longitudinal study[J].Scientometrics,2016,107(2):839-856��
����[4]CNNIC.The 43rd China statistical report on internet development[EB/OL].http://www.cac.gov.cn/2019-02/28/c_1124175686.htm,2019��
����[5]Agrawal R,Golshan1 B,Papalexakis E.Whither social networks for web search?[C]//Proceedings of the 21th ACM SIGKDD International Conference on Know ledge Discovery and Data M ining,2015:1661-1670��
����[6]Guan W,Gao H,Yang M,et al.Analyzing user behavior of the micro-blogging website sina weibo during hot social events[J].Physica A:Statistical M echanics and its Applications,2014,395(4):340-351��
����[7]Lemire D,Boytsov L.Decoding billions of integers per second through vectorization[J].Software:Practice and Experience,2015,45(1):1-29��
����[8]Delbru R,Campinas S,Tummarello G.Searching web data:an entity retrieval and high-performance indexing model[J].Journal of Web Semantics,2012,10(2):33-58��
����[9]Piriri G E,Venturini R.Inverted index compression[M].Encyclopedia of Big Data Technologies,Springer,2018��
����[10]Trotman A,Jia X F,Crane M.Towards an efficient and effective search engine[C]//SIGIR Workshop on Open Source Information Retrieval,2012:40-47��
����[11]Wang J,Lin C,Papakonstantinouy,et al.An experimental study of bitmap compression vs.inverted list compression[C]//Proceedings of the 2017 ACM International Conference on M anagement of Data,2017:993-1008��
����[12]Witten I H,Moffat A,Bell T C.Managing gigabytes:compressing and indexing documents and images[M].M organ Kaufmann,1999��
����[13]Hennessy J L,Patterson D A.Computer architecture:a quantitative approach[M].Elsevier,2011��
����[14]Croft W B,Metzler D,Strohman T.Search engines:information retrieval in practice[M].Reading:Addison-Wesley,2010��
����[15]Zobel J,Moffat A,Ramamohanarao K.Inverted files versus signature files for text indexing[J].ACM Transactions on Database Systems,1998,23(4):453-490��
����[16]Li Xiao-ming,Yan Hong-fei,Wang Ji-min.Search engine:principle,technology and system(second edition)[M].Beijing:Science Press,2012��
����[17]Manning C D,Raghavan P,Schutze H.Introduction to information retrieval[M].Cambridge:Cambridge University Press,2008��
����[18]Zobel J,Moffat A.Inverted files for text search engines[J].ACMComputing Surveys,2006,38(2):6.1-6.56��
����[19]Yan H,Ding S,Suel T.Inverted index compression and query processing with optimized document ordering[C]//Proceedings of the18th International Conference on World Wide Web,2009:401-410��
����[20]Arroyelo D,Oyarzun M,Gonzalez S,et al.Hybrid compression of inverted lists for reordered document collections[J].Information Processing and M anagement,2018,54(6):1308-1324��
����[21]Zipf G K.Human behavior and the principle of least effort[J].Journal of Clinical Psychology,1948,6(3):306-306��
����[22]Buttcher S,Clarke C L A,Cormack G V.Information retrieval:Implementing and evaluating search engines[M].M IT Press,2010��
����[23]Sayood K.Introduction to data compression[M].Morgan Kaufmann Publishers,2000:1-27��
����[24]Abadi D,Madden S,Ferreira M.Integrating compression and execution in column-oriented database systems[C]//Proceedings of the ACM SIGM OD International Conference on M anagement of Data,2006:671-682��
����[25]Willhalm T,Popovici N,Boshmaf Y,et al.SIMD-scan:ultra fast in-memory table scan using on-chip vector processing units[J].Proceedings of the VLDB Endow ment,2009,2(1):385-394��
����[26]Rice R F,Plaunt J R.Adaptive variable-length coding for efficient compression of spacecraft television data[J].IEEE Transactions on Communication Technology,1971,19(6):889-897��
����[27]Elias P.Universal codeword sets and representations of the integers[J].Information Theory,IEEE Transactions on,1975,21(2):194-203��
����[28]Moffat A,Stuiver L.Binary interpolative coding for effective index compression[J].Information Retrieval Journal,2000,3(1):25-47��
����[29]Williams H E,Zobel J.Compressing integers for fast file access[J].The Computer Journal,1999,42(3):193-201��
����[30]Cutting D,Pedersen J.Optimization for dynamic inverted index maintenance[C]//Proceedings of the 13th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,1989:405-411��
����[31]Scholer F,Williams H E,Yiannis J,et al.Compression of inverted indexes for fast query evaluation[C]//Proceedings of the International ACM SIGIR Conference on Research and Development in Information Retrieval,2002:222-229��
����[32]Silvestri F,Venturini R.VSE:efficient coding and fast decoding of integer lists via dynamic programming[C]//Proceedings of the19th ACM International Conference on Information and Know ledge M anagement,ACM,2010:1219-1228��
����[33]Anh V N,Moffat A.Inverted index compression using word-aligned binary codes[J].Information Retrieval Journal,2005,8(1):151-166��
����[34]Zhang J,Long X,Suel T.Performance of compressed inverted list caching in search engines[C]//Proceedings of the 17th International Conference on World Wide Web,ACM,2008:387-396��
����[35]Anh V N,Moffat A.Index compression using 64bit words[J].Software:Practice and Experience,2010,40(2):131-147��
����[36]Anh V N,Moffat A.Improved word-aligned binary compression for text indexing[J].IEEE Transactions on Know ledge and Data Engineering,2006,18(6):857-861��
����[37]Anh V N,Moffat A.Index compression using fixed binary codewords[C]//Proceedings of the 15th Australasian Database Conference,2004:61-67��
����[38]Deveaux J P,Rau-Chaplin A,Zeh N.Adaptive tuple differential coding[C]//Proceedings of the 18th International Conference Database and Expert Systems Applications,2007:109-119��
����[39]Zukowski M,Heman S,Nes N,et al.Super-scalar RAM-CPU cache compression[C]//Proceedings of the 22nd International Conference on Data Engineering,2006:59-59��
����[40]Delbru R,Campinas S,Samp K,et al.Adaptive frame of reference for compressing inverted lists[R].Ireland:DERI,2010-12-16��
����[41]Harizopoulos S,Liang V,Abadi D J,et al.Performance tradeoffs in read-optimized databases[C]//Proceedings of the 32nd International Conference on Very Large Data Bases,2006:487-498��
����[42]Song X,Jiang Y,Yang Y,et al.Optimizing partitioning strategies for faster inverted index compression[J].Frontiers of Computer Science,2019,13(2):343-356��
����[43]Brisaboa N R,Ladra S,Navarro G.DACs:bringing direct access to variable-length codes[J].Information Processing and M anagement,2013,49(1):392-404��
����[44]Vigna S.Quasi-succinct indices[C]//Proceedings of the 6th ACMInternational Conference on Web Search and Data M ining,2013:83-92��
����[45]Ottaviano G,Venturini R.Partitioned elias-fano indexes[C]//Proceedings of the 37th International ACM SIGIR Conference on Research and Development in Information Retrieval,2014:273-282��
����[46]Pibiri G E,Venturini R.Clustered elias-fano indexes[J].ACMTransactions on Information and System,2017,36(1):2:1-2:33��
����[47]Trotman A,Albert M,Burgess B.Optimal packing in simple-family codecs[C]//Proceedings of the 2015 International Conference on The Theory of Information Retrieval,2015:337-340��
����[48]Catena M,Macdonald C,Ounis I.On inverted index compression for search engine efficiency[C]//Advances in Information Retrieval-36th European Conference on IR Research,2014:359-371��
����[49]Pang H,Ding X,Zheng B.Efficient processing of exact top-k queries over disk-resident sorted lists[J].The VLDB Journal,2010,19(3):437-456��
����[50]Bast H,Majumdar D,Schenkel R,et al.IO-top-k:index-access optimized top-k query processing[C]//Proceedings of the 32nd International Conference on Very Large Data Bases,2006:475-486��
����[51]Do J,Zhang D,Patel J M,et al.Turbocharging DBMS buffer pool using SSDs[C]//Proceedings of the ACM SIGM OD International Conference on M anagement of Data,2011:1113-1124��
����[52]Jiang K,Yang Y,Zheng Q.Well-balanced successive simple-9 for inverted lists compression[J].IEICE Transactions on Information and Systems,2017,100-D(7):1416-1424��
����[53]Flynn M.Very high-speed computing systems[J].Proceedings of the IEEE,1966,54(12):1901-1909��
����[54]Intel Corporation.Intel?64 and IA-32 Architectures software developer manuals(version 058)[M].Santa Clara,CA:Intel Corporation,April 2016��
����[55]Intel Corporation.Intel?C++compiler 16.0 user and reference guide[EB/OL].https://software.intel.com/en-us/intel-cplusplus-compiler-16.0-user-and-reference-guide/��2019��
����[56]Schlegel B,Gemulla R,Lehner W.Fast integer compression using SIM D instructions[C]//Proceedings of the Sixth International Workshop on Data M anagement on New Hardware,2010:34-40��
����[57]Stepanov A A,Gangolli A R,Rose D E,et al.SIMD-based decoding of posting lists[C]//Proceedings of the 20th ACM Conference on Information and Know ledge M anagement,2011:317-326��
����[58]Lemire D,Boytsov L,Kurz N.SIMD compression and the intersection of sorted integers[J].Software:Practice and Experience,2016,46(6):723-749��
����[59]Trotman A.Compression,SIMD,and postings lists[C]//Proceedings of the 2014 Australasian Document Computing Symposium,2014:50��
����[60]Zhang Zhao-hua.The research on index compression and query process parallel algorithm based on multi-core platform[D].Tianjin:Nankai University,2014��
����[61]Ao N,Liu X,Wang G.Efficient decoding of posting lists with SIM D instructions[J].Journal of Computational Information Systems,2015,11(24):7747-7755��
����[62] Yan Hong-fei,Zhang Xu-dong,Shan Dong-dong,et al.SIMD-based inverted index compression algorithms[J].Journal of Computer Research and Development,2015,52(5):995-1004��
����[63]Zhao W X,Zhang X,Leire D,et al.A general SIMD-based approach to accelerating compression algorithms[J].ACM Transactions on Information Systems,2015,33(3):1-28��
����[64]Zhang X,Zhao W X,Shan D,et al.Group-scheme:SIMD-based compression algorithms for web text data[C]//Proceedings of the2013 IEEE International Conference on Big Data,2013:525-530��
����[65]Buttcher S,Clarke C L A.Index compression is good,especially for random access[C]//Proceedings of the Sixteenth ACM Conference on Information and Know ledge M anagement,2007:761-770��
����[66]Lin J,Trotman A.The role of index compression in score-at-a-time query evaluation[J].Information Retrieval Journal,2017,20(3):199-220��
����[67]Bast H,Majumdar D,Schenkel R,et al.Io-top-k:index-access optimized top-k query processing[J].The VLDB Journal,2006:475-486
����[68]Moffat A,Zobel J.Self-indexing inverted files for fast text retrieval[J].ACM Transactions on Information Systems,1996,14(4):349-379��
����[69]Strohman T,Croft W B.Efficient document retrieval in main memory[C]//Proceedings of the 30th Annual International ACM SI-GIR Conference on Research and Development in Information Retrieval,2007:175-182��
����[70]Boldi P,Vigna S.Compressed perfect embedded skip lists for quick inverted-index lookups[C]//String Processing and Information Retrieval,12th International Conference,2005:25-28��
����[71]Dimopoulos C,Nepomnyachiy S,Suel T.Optimizing top-k document retrieval strategies for block-max indexes[C]//Proceedings of the 6th ACM International conf Conference on Web Search and Data M ining,2013:113-122��
����[72]Jonassen S,Bratsberg S E.Efficient compressed inverted index skipping for disjunctive text-queries[C]//Advances in Information Retrieval-33rd European Conference on IR Research,2011:530-542��
����[73]Bortnikov E,Carmel D,Golan-Gueta G.top-k query processing with conditional skips[C]//Proceedings of the 26th International Conference on World Wide Web Companion,2017:653-661��
����[74]Liu Xiao-zhu,Peng Zhi-yong,Chen Xu.An efficient random access inverted file self index technology[J].Chinese Journal of Computers,2010,33(6):977-987��
����[75]Liu X,Peng Z.An efficient random access inverted index for information retrieval[C]//Proceedings of the 19th International Conference on World Wide Web,2010:1153-1154��
����[76]Elias P.Efficient storage and retrieval by content and address of static files[J].Journal of the ACM,1974,21(2):246-260��
����[77]Ottaviano G,Tonellotto N,Venturini R.Optimal space-time tradeoffs for inverted indexes[C]//Proceedings of the 8th ACMInternational Conference on Web Search and Data M ining,2015:47-56��
����[78]Mccandless M,Hatcher E,Gospodnetic O.Lucene in action:covers apache Lucene 3.0[M].M anning Publications Co.,2010��
����[79]Boldi P,Vigna S.MG4J at TREC 2005[C]//Proceedings of the14th Text REtrieval Conference,2005:4��
����[80]Zobel J,Williams H,Scholer F,et al.The Zettair search engine[J].Search Engine Group,RMIT University,Melbourne,Australia,2004��
����[81]STrohman,Trevor.Efficient processing of complex features for information retrieval[D]//University of M assachusetts Amherst,M assachusetts,2008��
����[82]Ounis I,Amati G,Plachouras V,et al.Terrier:a high performance and scalable information retrieval platform[C]//Proceedings of the Open Source Information Retrieval Workshop,2006:18-25��
����[83]Petri M,Moffat A,Culpepper J S.Score-safe term-dependency processing with hybrid indexes[C]//Proceedings of the 37th International ACM SIGIR Conference on Research and Development in Information Retrieval,2014:899-902��
����[84]Ao N,Zhang F,Wu D,et al.Efficient parallel lists intersection and index compression algorithms using graphics processing units[J].Proceedings of the VLDB Endow ment,2011,4(8):470-481��
����[85]Zhang Z,Tong J,Huang H,et al.Leveraging context-free grammar for efficient inverted index compression[C]//Proceedings of the39th International ACM SIGIR Conference on Research and Development in Information Retrieval,2016:275-284
����[86]Moffat A,Petri M.ANS-based index compression[C]//Proceedings of the 2017 ACM on Conference on Information and Know ledge M anagement,2017:677-686��
����[87]Moffat A,Petri M.Index compression using byte-aligned ANS coding and two-dimensional contexts[C]//Proceedings of the Eleventh ACM International Conference on Web Search and Data M ining,2018:405-413��
����[88]Pibiri G E,Petri M,Moffat A,et al.Fast dictionary-based compression for inverted indexes[C]//Proceedings of the 12th ACM International Conference on Web Search and Data M ining,2019:6-14��
����[4] �й�����������Ϣ���ģ���43���й��������緢չ״��ͳ�Ʊ���[EB/OL].http://www.cac.gov.cn/2019-02/28/c_1124175686.htm.,2019��
����[16]���������ƺ�ɣ���������������:ԭ����������ϵͳ(�ڶ���)[M]������:��ѧ�����磬2012��
����[60] �ŕ������ƽ̨����ѹ���������������㷨�о�[D]�����:�Ͽ���ѧ��2014��
����[62]�ƺ�ɣ��������������ȣ�����ָ����еĵ�������ѹ���㷨[J]��������о��뷢չ��2015,52(5):995-1004��
����[74] ��С�飬�����£�����Ч��������ʷֿ鵹���ļ�����������[J]�������ѧ����2010,33(6):977-987.
����ע��
����11Total number of Websites. http://www. internetlivestats. com/total-number-of-w ebsites. 2019. 05.
����22 The size of the w orld w ide w eb. http://www.worldwidewebsize. com.2019. 05.
����33The FastP FOR C++library:fast integer compression. https://github. com/lemire/FastPFOR. 2019. 05.





