
1、相关工作
随着互联网的发展,网络上的信息越来越多,但用户不能准确描述查询意图而导致查询失败的问题一直是业界研究热点。人类认知特点表明:人们遇到一个新情况时,一般会从过去的经历中寻找一个类似的情景,即通过类比推理将过去经验(源域)中得来的经验知识应用到新场景(目标域)。但现有的搜索引擎缺乏对此类查询请求的有效支持。
例如,苹果公司产品的用户要查询微软的产品,但该用户不知道相关产品的名字或关键字去描述想要的产品。在这种情况下,用户所熟知的苹果产品成为搜索微软产品的重要线索。大多数苹果产品的用户知道iPad是一款苹果销售的电子产品,如果他们想找到一款这样的微软产品,可以利用苹果公司与iPad之间的关系和微软公司与该公司销售的平板电脑之间关系的相似性。这样,用户只需要简单地给一个熟知领域的例子就足够了。即用户给出一个类比查询三元组Q=(苹果,iPad,微软),用户期望的检索结果Surface将会被搜索引擎返回。在这个类比查询中,(苹果,iPad)和(微软,Sur-face)之间的关系相似。
这种利用一个已知领域的例子进行查询,从未知领域获取信息的搜索方式称为类比检索(Analogy Search,AS),又称为潜在关系检索(Latent Relation Search,LRS)。类比检索能有效地回答用户类比查询请求Q=(A:B,C:?),它通过从现有搜索引擎(例如,Google)返回的Web文档中抽取词对(A:B)之间的潜在关系,将获取的潜在关系与第3个词C相结合,再次从搜索引擎返回的Web文档中查找并返回目标词?。
这里的A,B和C可以是词语或者命名实体。类比检索是随着语义相似度和关系相似度等领域的发展于近几年才开始兴起且受到关注的,是新一代知识搜索引擎的一个体现,目前已经成为业界新的研究方向和研究热点。
文献调查发现,现有相关研究主要面向英语和日语。日本东京大学的Kato等在2009年详细阐述了潜在关系搜索的概念和应用,提出了基于词语共现的方法和基于语义模式的方法。基于词语共现的方法使用词袋(bag-of-word)表示两个词语之间的关系,基于语义模式的方法则是将抽取出来的含有词对的一个短语中的0个或多个单词用*来代替之后构成模式。
Duc等在2010年提出了日文的潜在关系搜索方法。这种方法从Web语料库中抽取词对,利用语义模式来代表词对之间的关系,获得了较高的准确率和召回率。但这种方法需要抓取大规模的语料并构建超大型的索引库,并且测试集限定在 有 限的领域内,没有测试其他领域的准确性。
Goto等于2010年提出了一种利用关系相似对称性和辅助排名来改进关系搜索结果排名的方法。
2011年Duc等提出的CLRS方法初步探索了跨语言、跨领域的知识映射。
国内也开展了针对类比检索的初步研究。
2012年,梁等提出了一种中文潜在关系搜索方法。该方法采取词袋来描述词对之间的语义关系,即首先使用预定义的句法模式来抽取能描述词对之间的潜在关系的关系代表词(集),然后利用关系代表词来搜索满足相关预定义句法模式的目标词语(集)。但这种算法基于两种假设,且从概率统计上对候选关系词和目标词进行筛选,准确率相对较低。
现有基于概率统计的相关方法大都基于二种假设,但这二种假设却不适用于中文。通过观察大量实验数据,笔者发现:能准确地抽取出词对之间的潜在关系的句子一般满足某种特殊结构,本文中把这类句子叫做关系句。基于以上的分析,本文提出了基于SVM的类比检索方法(SVMbCRA),即首先利用SVM将所有包含词对的句子分类,即划分为“潜在关系句”和“非潜在关系句”两类。然后再从关系句中抽取词对之间的潜在关系并进行目标词确定。从而有效地提高了关系词抽取的准确率和目标词识别的准确率。
2、基于SVM的类比检索方法
基于SVM的中文类比检索方法的主要处理步骤如图1所示。该方法的主要步骤包括确定关系代表词R和抽取目标词(集)D。图1中,实线描述了关系代表词R的抽取过程,即通过这一步骤可以得到描述词对(A,B)之间潜在关系的关系代表词(集)R;虚线描述了目标词的抽取过程,即通过这一步骤可以得到目标词(集)D。
关系代表词的抽取过程如下:(1)输入词A和词B,预处理模块通过调用搜索引擎获取包含词A和词B的网页及句子;(2)提取句子特征生成特征向量,通过SVM训练后生成训练模型;(3)利用生成的训练模型对步骤(1)中得到的句子进行测试,识别出关系句;(4)抽取出关系代表词并进行排序。

目标词的抽取过程类似于关系代表词的抽取,区别在于输入为C和关系代表词R组成的新词组(C,R)。
2.1确定关系代表词
2.1.1预处理预处理模块的主要功能是抽取包含输入词对的句子,然后进行分词和词性标注处理。
预处理模块首先通过搜索引擎(例如,Google)抽取包含词A和词B的搜索结果,即得到包含词A和词B的一系列网页网址,依次抓取每个网址指向网页中包含词A和词B的句子。接着将包含词对(A,B)的句子从这些文本语料中提取出来。此处以词对(X,Y)为例,抽取同时包含X和Y词的句子。
VSMbCRA方法抽取满足以下模式的句子:m*X*Y*m或m*Y*X*m(1)
其中,m为断句的标点符号或空格,*代表除m外的任意字符。采取此方法,我们可以抽取词X之前,词X与词Y之间及词Y之后的词语(或短语)。
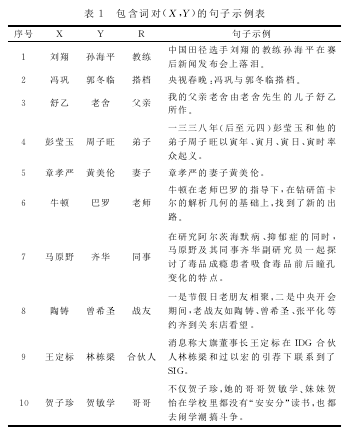
表1中列出了一些抽取出的句子。其中,第2列和第3列表示词X和词Y,第5列表示抽取的包含词X和词Y的句子示例。
其次,将所抽取的包含词对的句子进行分词,抽取每个分词后序列的主干。本文利用中文分词工具ICTCLAS将每个句子分割成独立的词语。每一个词都有自己的词性标注。例如,“章孝严/nr的/uedl妻子/n黄美伦/nr”。预处理后,将得到大量分词标注后的句子。现在的问题是如何确定能代表两个词语之间潜在关系的词语(即,如何确定关系代表词)。
2.1.2模型建立包含两个输入词语的句子可以分为两类,第一类被称为潜在关系句,即句子中有明确表示词对之间关系的词语,如表1中的前10个句子(其中表征关系的词用粗体表示);第二类是普通句子,即不含有表示词对关系的词语。我们把表征词对之间关系的词语称为关系代表词,把包含关系代表词的句子称为潜在关系句。因此,如果能够识别出潜在关系句,则可以精确地找到关系代表词。
如前所述,本文把潜在关系句识别看作是一个二分类问题,即“潜在关系句”与“非潜在关系句”两种类别。
SVM(Supported Vector Machine)是一种建立在统计学习理论基础之上的机器学习方法。该方法建立了一套有限样本下机器学习的理论框架和通用方法,能够较好地解决小样本、线性和非线性等实际分类问题。因此在本文中采取SVM分类器来识别潜在关系句。
潜在关系句识别可以总结为:估计类别y和潜在关系句特征x的共现概率p(x,y),这个共现概率是用来衡量一个潜在关系句在特征x下成为y类别的置信度,从而实现对潜在关系句的分类。在这里类别y主要表示“潜在关系句”和“非潜在关系句”两类,而x就是潜在关系句的特征向量。
潜在关系句识别问题可以转化成如下数学模型,即:给定训练样本集合为T={(x1,y1),(x2,y2),…,(xn,yn)},其中xi∈Rn,yi∈{-1,1}。这里的xi即为潜在关系句样本的特征向量,而yi即为潜在关系句的类别。那么目标问题就转化成在Rn上寻找一个实函数g(x),使得决策函数f(x)=sgn(g(x))能够成立,这样就使得每个样本都能够得出它所对应的y值。
在利用SVM识别潜在关系句时,本文提出根据每一个潜在关系句的语言学特征来判断它是否为潜在关系句。主要过程是利用SVM结合候选潜在关系句的各种语言学特征进行处理,计算出候选潜在关系句在这种特征下可以成为潜在关系句的置信度,SVM选择置信度大于某阈值的句子作为潜在关系句。
2.1.3特征选取本文从两个方面选取特征,即形态学特征和词对的上下文特征。形态学特征主要包括:(1)一个词对中词语的位置关系;(2)词对的上下文相对词语的位置。词对的上下文特征是表征句子特征的重要信息,词对的上下文主要指上下文中词语构成序列。一般地,可以把一个句子划分为4个部分:词语A和词语B、词语A之前的词、词语A与词语B之间的词和词语B之后的词。
词语周围一定范围的上下文可以为词语的定义提供较为充分的语言信息。如何确定每一部分词语的数量是一个需要解决的问题。在文献中采用信息论中信息增益的计算方法来实现上下文有效范围的量化确定。计算结果反映了这样一个情况:上下文对核心词语的描述能力随着相对位置由近及远而逐渐递减,即通过已知上下文推断空缺词语时,近距离的上下文在推断中所起的作用比远距离的上下文更有价值。
这一计算结果与人们的认知过程基本一致。虽然是近似结果,但在一定程度上具有统计意义。本文根据这一原则将上下文范围确定为A词前2个位置,A与B词中间3个位置和B词后2个位置的范围大小。
根据确定的上下文范围,将句子定义为如下形式:a1,a2,A,c1,c2,c3,B,b1,b2(2)分词后的词语全部进行了词性标注,词性标注的序列如下所示:a1pos,a2pos,c1pos,c2pos,c3pos,b1pos,b2pos(3)上式称为N-POS。对大量抓取的包含词A和词B的句子进行分析,如表2所列。本文确定c1,c2,c3,b1和b2作为潜在关系句识别的上下文范围。

设有(A,B)为词对,特征向量的集合为:V(A,B)=(v1,v2,…,vn) (4)向量的每一维是这个词对的各项特征形成的七元组。vi=(distance,order,c1pos,c2pos,c3pos,b1pos,b2pos)(5)
其中:
1)distance为命名实体对中两个命名实体之间的词距。
2)order为两个命名实体的相对位置,分别为0(A在B左边),1(B在A左边)。
3)N-POS即词语序列中N个连续词性的顺序组合,本文认为几种连续词性的组合表征关系信息。其中c1pos、c2pos、c3pos、b1pos、b2pos即为N-POS序列组合。
2.1.4识别潜在关系句本文的潜在关系句识别主要分两大模块实现:(1)SVM训练模块;(2)SVM测试模块。在训练模块中,首先进行特征选取并选取特征数据生成特征向量,然后训练生成目标模型。
在测试模块中首先根据选取的特征生成特征向量,然后利用目标模型对特征向量进行识别,最终识别出潜在关系句。
在训练过程中,特征提取主要是针对特征模型提取其相应的特征。在训练语料库中对分词后句子的特征信息进行统计,这些信息主要是词语顺序(order)、词语间距(distance)、词语序列及词性(N-POS)。表3列出了训练样本中提取的一些潜在关系句的特征。对于训练数据,识别出相同数量的潜在关系句和非潜在关系句进行正反例标注并生成特征向量。

SVM训练主要是利用之前从训练语料库中提取的正负特征向量。将训练样本向量进行SVM训练,得到支持向量模型。本文采用林智仁开发的支持向量机学习测试工具包LibSVM,LibSVM程序包提供4种核函数供选择:线性、多项式、径向基、sigmoid核函数。程序包作者通过实验指出在一般情况下使用径向基核函数较好,但在特征数量较大时则应该选择线性核函数。本文的研究重点是有效区分潜在关系句和非潜在关系句,选取了程序包默认参数。通过SVM的训练,使正负样本特征向量生成支持向量模型,为后续的测试识别潜在关系句提供测试分类的数据依据。
为了提高SVM训练的准确度,本文将c1、c2、c3、b1、b2所对应的词性标注映射到连续区间,并将表征潜在关系句的词性标注和其他词性标注划分为两个连续的数值区间。例如将b1pos的标注“30058”、“为”、“是”、“28160”分别映射为0、1、2、3。其余的标注依次从4开始映射。
整个测试过程的流程如下:同训练过程,首先按照句子划分的定义,记录下每个位置的上下文词语的词性。同时记录下两个实体间的位置关系,包括实体的前后顺序和两个实体之间的间距。然后生成潜在关系句的正负样本特征向量,最后将生成的特征向量进行SVM训练,从而标记出测试样本的正负实例。测试的过程其实就是把候选潜在关系句分成正和负两类,正表示潜在关系句,负表示非潜在关系句。
2.1.5候选关系代表词排名识别出潜在关系句后,我们从这些潜在关系句中提取出候选关系代表词。候选关系句排名分为4个步骤:(1)识别出潜在关系句后,抽取出其中的候选关系代表词;(2)将潜在关系句中出现的名词和动词进行词频统计;(3)统计完成后,计算词语之间的相似度进行合并;(4)最后对合并后的候选关系代表词排序。具体算法见算法1。


2.2抽取目标词目标词的抽取过程和关系代表词的抽取过程基本相同
主要步骤包括:抽取出的关系代表词R同C组合成新的词对(C,R)。通过2.1.1节中介绍的预处理过程得到包含C和R的句子。然后按照2.1.2节、2.1.3节和2.1.4节介绍的方法抽取句子特征生成特征向量,利用训练得到的目标模型对特征向量进行识别,识别出潜在关系句。最后从潜在关系句中提取出满足N-POS特征的候选目标词。
3、实验结果及分析
3.1测试数据集和实验方案设计
现有的实验数据集仅涉及日文和英文,没有标准中文实验数据集。人立方关系搜索是微软亚洲研究院开发设计的一款新型社会化搜索引擎,它能从超过十亿的中文网页中自动地抽取出人名、地名、机构名以及中文短语,并通过算法自动地计算出它们之间存在的可能关系。本文考虑了人立方中人与人的13种关系,即师徒,夫妇,情侣,父子,母子,兄弟,姐妹,合伙,搭档,朋友,同事,战友,经纪人,从人立方中选取了2400人物实例,并构成1200个测试词对。这些测试词对涵盖了上述13种关系。
部分测试词对及组成该词对的两个词之间的关系如表4所列。对于每一种关系大类中的实例,分别取一半用来进行关系代表词确定实验,一半用来进行目标词确定实验。因此关系代表词确定和目标词确定实验的测试词对均为600组。

SVMbCAR方法有两个重要步骤,步骤1是潜在关系句识别,步骤2是关系代表词抽取和目标词抽取。为此,本文设计了两个实验,第1个实验测试潜在关系句识别的效果,第2个实验测试关系代表词抽取及目标词抽取的效果。这两个实验的机器配置如下:处理器为Intel?Pentium?CPU G630 @2.7GHz,内存4GB,操作系统为Win7 64位。
3.2实验评估
3.2.1潜在关系句识别效果评估潜在关系句识别实验采用训练测试时间和准确率来衡量实验效果。其中表5中的均方误差为SVM衡量测试准确率的相关指标,均方误差越低,说明准确率越高。
本文选取3组测试数据来训练SVM模型,第1组中的正反例个数均为2000,第2组的正反例个数均为4000,第3组的正反例个数均为8000。各组训练时间和模型大小如表5中第2列和第3列所列。在识别之前对测试数据进行人工的正反例标注,标注方法与训练数据的标注方法相同,即对于N-POS序列符合潜在关系句的句子标注为正例,其余的标注为反例。测试结果如表5的第4列所列。表5显示,随着训练正反例个数的增加,训练模型时间增加,但测试时间整体变化不大。

从表5中可以看出,随着训练数据的增加,准确率有所提高。实验结果表明,SVMbCAR算法识别潜在关系句是十分有效的。
3.2.2关系代表词和目标词抽取效果评估关系代表词抽取从3个方面进行评估,即准确率(P)、期望目标词排名的倒数平均值(MRR)和期望目标词排名在前k位的百分比(Rank(i))。目标词抽取采用准确率(P)进行评估。准确率指的是期望词排名在第一位的测试词对占所有测试词对的比例。
MRR是期望词排名的倒数平均值。Rank(i)是指期望排名在前i位的测试词对所占的比例。

文献调查发现,现有的类比检索相关研究围绕着日语和英语展开,鉴于中文的语言特点,面向日语和英语的类别检索方法不能直接处理中文。文献[5]提出了面向中文的基于统计的类比检索方法(简称为STAbCAR方法)。因此本文将SVMbCAR方法和STAbCAR方法进行了比较。
表6显示了两种方法针对600组测试数据在关系代表词抽取方面的实验效果,即两种方法得到的关系代表词排名在每个区间中的实例个数。表6中,第1列为两种方法,第2列至第7列分别表示两种方法抽取出的关系代表词的个数的排名情况,即第1位的个数,第2-5位的个数,第6-10位的个数,依次类推。从表6中可以明显看到代表STAbCAR算法关系代表词排名在第1位的个数少于SVMbCAR算法,越往后,实例个数分布越少。
SVMbCAR算法抽取的关系代表词排名前10的占到了99.3%,STAbCAR算法占到了97.3%。
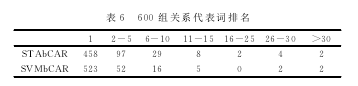
表7显示,SVMbCAR方法抽取关系代表词的准确率为82.3%,比使用STAbCAR方法抽取关系代表词的准确率提高了10.2%。SVMbCAR方法的MRR值由78.7%提高到了85.9%。

在目标词的确定过程中,我们可以明确目标词D一定是名词并且目标词的出现相对于关系代表词的出现更加集中和准确。因此,在目标词的确定实验部分不再使用MRR指标,只要出现在排名第1位则认为准确,否则错误,因此这里只采用正确率进行衡量。从表8可以看出,SVMbCAR抽取目标词的准确率达到了90.5%,而STAbCAR的准确率为82.8%。

结束语
类比检索是一种根据已知领域知识查询未知领域知识的全新检索方式。通过分析词对间的潜在关系,类比检索可以准确地返回目标信息。即,给定查询请求Q={A:B,C:?},类比检索的目标是得到?所代表的目标词D,其中A与B的关系和C与D的关系相似。本文提出了基于SVM的中文类比方法。该方法首先利用SVM识别潜在关系句,然后抽取出潜在关系句中的相关词语作为关系代表词或目标词。本文采用从人立方中选取的600组人物实例对设计了两个实验,一是针对潜在关系句识别的实验,二是针对关系代表词抽取和目标词抽取的实验。实验结果表明了,本文提出的SVMbCAR在潜在关系句识别、关系代表词和目标词抽取两个方面的效果。
本文提出的SVMbCAR方法虽然取得了良好效果,但也存在一些需要改进的地方:(1)由于需要实时抓取大量网页语料进行处理,时间和空间消耗较大。接下来的研究考虑通过提高关系词的提取准确率来减少网页访问次数,以实现实时的类比检索。(2)在SVMbCAR算法中,特征提取的有效性对识别准确率有较大的影响,未来考虑选取更加有效的特征来构造特征向量,提高潜在关系句的识别准确率,进而提高抽取关系词和目标词的准确率。(3)进一步研究SVM的不同参数对实验效果的影响。





