
伴随网络技术的发展,网络信息大量增加,涵盖期刊、会议纪要、论文、学术成果、学术会议论文的大型网络数据库应运而生,如万方数据库、百度文库、维普数据库等,文献存储容量近百万篇.如何有效搜集发现信息,并对信息提取、组织、处理,就需要寻找出高效算法,降低计算复杂度,提高运算效率,以适应文献资源的迅速扩充[1].
1 文献资料搜索引擎技术特点
当用户以关键词查找信息时,搜索引擎会在数据库中进行搜寻,如果找到与用户要求内容相符的信息,便采用特殊的算法,根据文献中关键词的匹配程度,如出现的次数、频率等计算出各文献的排名等级,然后根据关联度高低,按顺序将这些资源接返回给用户.
与网络搜索引擎不同,因用户需求为数据资料而非网络资源,因此文献检索主要依据为相关关键词、内容的相关度等,对域名、外链等因素考虑较少.可利用关键词匹配算法,计算出各文献特征值,以特征值作为依据,对检索文献排序删选,满足用户需求.为便于理解,该文利用词频和位置加权算法计算特征值,采用快速排序算法进行整理输出,数据库可高效检索出与用户需求匹配程度较高的文献[2].
2 快速排序算法规则及性能分析
快速排序是由托尼·霍尔于1962年(Tony Hoare)所发展的一种递归排序算法,采用分治的思想.在平均状况下,排序 n 个项目需要Ο(n log n)次比较.
其算法规则可表述为:
1) 从数列中挑出一个元素,称为 “基准”(pivot);2) 所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面,称为分区(partition)操作.如数列[5, 3,8, 1, 6, 7, 9, 4, 2],以首元素作为基准,经一趟操作后,变为 [2, 3, 4, 1, 5, 7, 9, 6, 8];3) 递归地(recursive)把小于基准值元素的子数列[2, 3, 4, 1]和大于基准值元素的子数列[7, 9, 6, 8]排序.递归至最终情形,即子数列的长度是0或1.
在文献检索过程中,根据词频和位置加权算法计算出各文献特征值,特征值构成无序数列,以其为索引,对文献重新整理排序,将匹配程度高的置于顶端,满足用户检索需求.这一过程为排序操作,传统排序算法,如交换排序、选择排序、插入排序等,平均时间复杂度均为O (n2).如图1所示,为分别采用传统排序算法与快速排序算法,在检索过程中计算时间复杂度的比较.
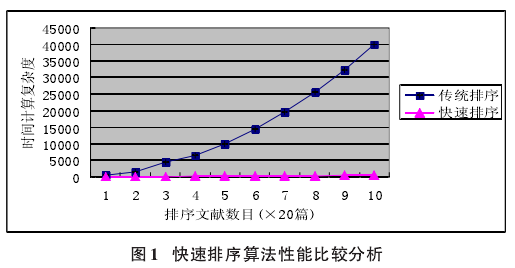
可以看到快速排序算法在计算时间复杂度方面明显优于传统排序算法,特别在相关文献数目不断增长的情况下,优势体现更为明显.这一点能够很好适应当前各文献检索数据库信息资源迅速扩充的现实情况.
3 算法设计与仿真
首先建立包含十五篇文献的资料库,根据用户需求,随机输入关键词,在此可将关键词视为子串,对各文献进行字符串匹配操作.文献为A串,即目标串,关键词为B串,即模式串.若A串中存在和B相等的子串( 若干连续的字符组成的子序列) ,则匹配成功,,否则,称匹配不成功[3].
匹配过程如图2所示,将模式串设置为滑动窗口.在第一次匹配过程中,第三个字符出现不相同情况,此时根据KMP算法原则,利用已经得到的部分匹配的结果,将模式串窗口向后滑动一段距离后,继续进行比较.

同时需要考虑关键词匹配成功的具体位置.在文献检索过程中,如在标题匹配成功,要远比在正文部分匹配成功重要.如表1所示,位置设置包括:标题、副标记、关键词、正文,不同位置分别设置权值,在字符匹配的同时进行加权处理,计算出各文献的特征值,特征值应体现出文献的重要性和与用户需求匹配程度这两个关键指标.

基于网页检索PageRank算法中的学术引文机制[5],当文献1引用到文献2时,就认为文献1投了文献2一票,增加了文献2的重要性,.首先将资料库中资源通过文章参考文献建立链接关系,如图3所示,当输入检索关键词“搜索引擎”,在目标文献的参考文献部分匹配成功,此时不应增加目标文献的重要性指标,应将重要性特征值的增长量赋予文献“搜索引擎及其发展”,即文献2.
这一算法设计体现出,被引用次数越多,则该文献权威性越高,特别适用于结构化文档,如期刊数据等.

应充分考虑用户行为反馈,即被下载次数越多的文献,说明该文献的重要性.被下载次数的统计,可设计为一动态投票系统,被下载一次,即进行投票处理,系统累计每篇文献投票次数,形成一个排序系统[6].
根据以上原则搭建信息检索系统结构,如图4所示,当用户输入需求检索信息后,程序开始启动,分析计算出资源库中各文献特征值,特征值计算原则为 R=∑i=17ai×bi,此时文献就会携带关于自身评价的信息,包括权威性、匹配吻合度、受欢迎度等,但仍无序排列.需要以文献特征值为依据,引经特征值算法分析计算,模拟资源库中十五篇文献资料获得各自特征值,分别记录在每篇文献上,如表2所示,但仍处于无序状态,无法提供用户使用,此时快速排序算法开始执行.

快速排序算法的基本出发点是把某个需要解决的庞大问题, 化作若干个在尺寸上小于原问题而在形式上和原问题又完全相同的问题, 层层分解逐次逼近.在排序过程中,引入该思想,可有效提高检索效率.具体执行过程如下所示:
① [3, 9, 10, 7, 4, 11, 13, 9, 9, 9, 0, 1, 0, 8, 13]
第一次执行,将首篇文献R[1]作为基准,分区操作,特征值大于其的文献列左,其余列右:
② [0, 1, 0, 3, 4, 11, 13, 9, 9, 9, 7, 10, 9, 8, 13]
第二次执行,将R[5]作为基准,分区操作:
③ [0, 1, 0, 3, 4, 11, 13, 9, 9, 9, 7, 10, 9, 8, 13]
第三次执行,将R[1]作为基准,分区操作:
④ [0, 0, 1, 3, 4, 11, 13, 9, 9, 9, 7, 10, 9, 8, 13]
第四次执行,将R[6]作为基准,分区操作:
⑤ [0, 0, 1, 3, 4, 8, 9, 9, 9, 9, 7, 10, 11, 13, 13]
第五次执行,将R[6]作为基准,分区操作:
⑥ [0, 0, 1, 3, 4, 7, 8, 9, 9, 9, 9, 10, 11, 13, 13]
经过五次操作,排序完成,明显优于传统排序算法O (n2)的时间复杂度.如表3所示,此时资源库形成有续表,可以顺序输出,满足用户检索需求[7].


4 结束语
伴随近年来文献检索平台信息数量、种类的不断增加、服务需求水平的不断提高,对文献检索算法提出更高的要求.在本检索系统设计思路中,充分参考当前网页搜索引擎中较为普遍应用的位置加权、用户行为反馈、KMP算法和Pagerank算法等设计思.
参考文献:
[1] AnIlbmst M,Fox A,Gmth R,et a1.A view of cloud computing[J].Communications of the ACM,2009,53(4):50-58.
[2] Brian Hayes.Cloud computing[J].Communications of the ACM,2008(7):9-11.
[3] 李建锋,彭舰.云计算环境下基于改进遗传算法的任务调度算法[J].计算机应用,2011,30(1):184-186.
[4] 李爱国.多粒子群协同优化算法[J].复旦学报:自然科学版,2004,43(5):923-925.
[5] Eusuff M M,Lansey K E.Optimization of water distribution network design using the shuffled frog leaping algorithm[J].Joumal of WaterSources Planning and Management,2003,129(3):210-225.
[6] The Could Lab.Cloudsim[EB/OL].[2011-08-15].
[7] Buyya R,Ranjan R,Calheiros R N.Modeling and simulation of scalable cloud computing environments and the CloudSim Toolkit:chanl.





