
0 引言
经济周期,又称商业周期( business cycles) 是国家总体经济活动中反映出的起伏波动,其表现为很多经济活动同时发生,包括扩张、全面衰退和收缩,以及作为下一个经济扩张周期循环开始的复兴过程[1].对国家经济形势周期性变化进行分析和预测一直以来都是各国政府制定金融策略和应对金融危机的重要依据,对国家政治经济系统的安全和稳定运行具有重要意义。
对于经济周期的模拟自 20 世纪 80 年代在全世界范围内已经开始,学者们开展了大量的研究,取得了巨大的成绩。传统模拟方法中,以 Swarm 模型作为系统的整体模型,利用多主体 Agent 进行模拟仿真[2-3],但不能处理大规模数据,如果多次模拟会耗费大量的时间,并且占用资源过多。将并行技术用到经济模拟系统中,可以达到提高模拟系统效率的目的,在一定程度上降低硬件成本。
并行计算技术至今为止已经经历了 3 代模型,第 1 代主要是以处理器计算为中心的 PRAM[4-5]和APRAM[6]等模型; 第 2 代主要是以网络通信为中心的 BSP[7],NHBL[8]等模型; 第 3 代主要以存储访问为中心的 UMH[9]和 HPM[10]等模型。模型更新主要以减少运算过程中的通信开销,避免读写及调度时的冲突为主线,在整体方面提高计算速度和人机交互的速度[11].通过模型的对比分析,在分布式环境中,第 3 代模型虽然能协调各进程的执行和节点之间的数据的传输,但无法解决系统中进程失效以及合并进程的中间结果等问题。使用 Hadoop 并行技术能有效解决上述问题。
由 Apache 基金会开发的 Hadoop 是一个分布式系统的基础架构,实现了分布式文件系统( HadoopDistributed File System,HDFS) ,能运行 MapReduce.MapReduce 是 Google 开发的一种简洁抽象的分布式计算模型[12],因其高易用性和可扩展性而得到了广泛应用。基于第 3 代并行计算模型的 MapReduce能够解决系统中部分进程失效的问题,能自动检测到失败的 map 和 reduce 任务,并让正常的处理机处理这些失败的任务。以上功能都基于其无共享框架实现[13].
本文在研究仿真模拟和并行计算技术的基础上提出了运用 Hadoop 并行技术解决多个经济市场并行模拟问题,实现了多市场同时模拟,实时显示模拟结果,提高了系统资源的利用率,缩短了仿真模拟的时间。
1 并行计算在系统模拟中的应用
并行计算在系统模拟中的应用,主要针对多处理器的并行进行算法的改进,将 CPU 的利用率问题作为考虑的最主要方面,每个线程对应一个 CPU,多 个 CPU 在 处 理 时 的 加 速 比 为 S( n) =单 CPU 串行处理的最优时间/多 CPU 的并行处理时间, CPU 的 效 率 =S( n)/CPU 数量,如 何 提 高 CPU 的 效 率 成 为 重 中 之重[14].运用多线程同步机制、调度算法和通信机制,进行并行计算程序的设计,构造一个多线程的应用,主要是对线程的调用和线程状态的转换进行研究,在线程同步的过程中对线程进行监视和加锁,以达到对线程的同步控制并增加系统的安全性和整体利用率。多个线程之间的通信机制也对系统整体状况起到非常关键的作用[15].图 1 为 Hadoop 并行计算体系结构,集群系统首先将求解问题分解到多个节点中,每个节点都有自己 的 处 理 模 块 ( MapReduce ) 和 存 储 模 块( DataNode) ,完成本节点的计算和存储任务,然后通过各个节点之间的通信( RPC) ,最终完成问题的求解过程,得到结果。
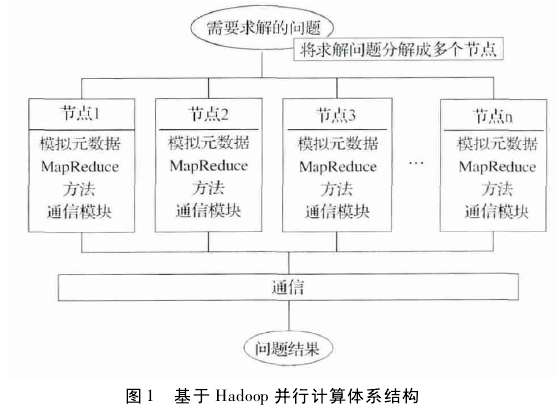
节点间的通信机制是处理过程中一个重要的任务,通信量的大小直接影响系统的性能,为权衡通信机制占用的开销,为通信机制设置一个阈值,表示通信次数和通信量的大小。阈值的设定要符合系统的现状,阈值偏高会增加节点间的通信,降低系统的效率,阈值偏低,造成节点间不能很好地通信。对于一个系统来说,首先保证的是在不影响节点通信的同时尽可能提高系统的效率,而不是为了提高系统的效率而影响节点间的通信。
2 仿真模拟方法设计与实现
在 Swarm 环境的支持下,首先模拟一个市场。市场中有多类智能体( Agent) ,包括消费者、生产者、政府和银行等,通过为每个个体设置初始值( 此值可以是确定的,也可以在一定范围内随机选取) 来设定个体的初始状态和初始资本。Agent 有一定的自主能力,来决定自己的行为,也可以根据周围环境和自身现在的状态进行决策,最终通过个体与个体之间的交互影响市场的总体趋势。由此产生了一个问题: 如何定义市场的大小? 对于较大市场的模拟,能够得到较好的模拟结果,但数据量的增长和个体复杂度的提升会对系统造成一定影响; 对于较小市场的模拟,得出的结果和实际相差较大。现实社会中有多个市场,市场之间有一定联系。用传统的模拟方法对所有市场在单机中进行模拟,然后再汇总计算模拟的结果,并且每台计算机只能处理本地的数据。这样的模拟不仅浪费大量的时间,而且得出的模拟结果并不一定准确。如果使用多台处理器进行模拟,这样虽然能节省时间,但是耗费了大量的资源,工作量也比较大。
本文提出使用 Hadoop 并行计算技术解决经济周期模拟的方法,将多个市场看作是一个完整系统进行模拟。在 Hadoop 集群环境中,每个市场都分配在一个节点中。实际上市场之间是存在交互的,本研究主要是为了体现并行方法对模拟性能的提高,因此不考虑模拟时市场之间的交互,只将各市场的模拟结果进行实时整合,将整合结果展现,得出最终的模拟结果。
在使用 Hadoop 并行计算技术解决经济周期模拟问题时,文件系统 HDFS 将需要模拟的市场环境和个体属性存储到 DataNode 节点,模拟结果以块的形式存储到节点中。Hadoop 中节点间数据块是内容共享的,节点的数据传递到服务器端进行整合,计算出结果。如图 2 所示,HDFS 通过客户端对整个系统进行控制,在每个 DataNode 节点中进行模拟,存储在数据块中,以便对 GDP 和 Gini 系数进行整合,GDP 系数可以用多个市场总和来计算,Gini 系数代表收入差距,用多个市场的的平均值计算。本次模拟的经济市场没有货品交换,但对 GDP 和 Gini系数进行了汇总计算。

MapReduce 中分为 Mapper 法和 Reducer 方法,使用 MapReduce 处理经济模拟仿真数据问题时,Map 和 Reduce 的操作并不困难,关键是对于数据的组织和传输[16].Map 是数据本地化、并行化的关键,对于包含大量 GDP 和 Gini 系数的大文件来说,如何确定仿真数据的起点和终点、如何将 Map 阶段的数据划分成多个子文件、如何协调子文件节点内部数据分发和 Task 调度的配合成为并行化的难点。
通过 MapReduce 模型与 HDFS 的配合与协作,HDFS 按照数据块存储大文件,分解成多个子文件,每个子文件中存储一个经济市场的 GDP 或 Gini 系数。首先获取系统中每个文件的位置,可以是本地数据、也可以是文件系统中其他节点的公共数据,再对数据进行处理[17].
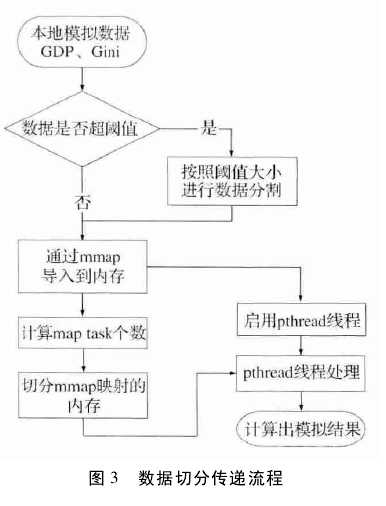
并行计算中数据切分传递的工作流程如图 3 所示,系统需要将各个市场的模拟结果进行实时整合,持续性的将数据传输到服务器。考虑到计算机的运行效率,如果数据逐条传输,将会大大降低系统的运行效率,为此系统为数据传输设置一个阈值,因为数据是实时写入到文本文档中的,当文档中数据到达阈值时,将数据一次性通过 mmap 映射到内存,然后计算 MapTask 的个数,并且按照 mapTask 的个数切分 mmap 映射的内存,分别交给 pthread 线程处理,得出计算结果。
多主体系统 MAS( Mutil-Agent-System) 是由多类主体共同完成经济问题的模拟。根据抽象出的Agent 模型,利用 Swarm 类库,为每类主体设定特有的属性。在二维的市场网络中,每个个体周围有 8个邻居,当邻居的利润大于自己的收益时,主体便会图 3 数据切分传递流程根据周围的邻居的营销策略进行学习,通过改变自身的消费预期值、生产预期值和变异的概率等( 每个生产者可以有一定的概率变异成高效企业或者破产) 来改变自身的状态。
图 4 为个体之间的逻辑展示图。暂时只考虑在二维空间内个体之间的关系,每个个体与周围 8 个相邻的个体进行交互学习。设自身的坐标为( 0,0) ,相邻个体的坐标从( -1,-1) 到( 1,1) ,按照式( 1) 进行学习:
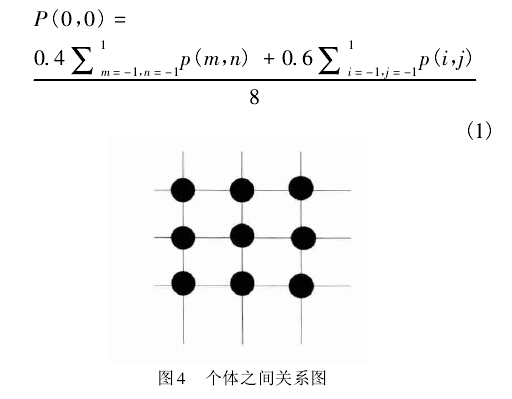
式中,P ( 0,0) 为学习者的消费预期或生产预期值;P( i,j) 为周围相应邻居中大于自身消费预期或生产预期值的个体; P( m,n) 为周围邻居小于自身值的个体,按照一定的权重将高和低的消费额相结合。
通过实验得出,如果高消费和低消费占相同比重,得出的结果不能保证经济的稳定增长,如果高消费比重过高,经济周期的规律性受到影响,此处将高消费的比重设置为 0. 6,低消费的比重设置为 0. 4,既避免了自身值不断增加而使模拟结果与现实差距较大,也使市场的 GDP 缓慢增长,并呈现周期性。

图 5 为经济模拟中 MapReduce 的工作流程,在pthread 线程中首先取得内存中的数据,标记数据块来自的市场。对本地的模拟数据进行保存时,为每个保存的数据添加一个时间戳,Mapper 方法处理<key,value>格式的数据,key 是 value 数据的时间戳,value 是模拟得出的数据,为 GDP 或 Gini 系数。通过 Mapper 处理后,输出以 GDP 或 Gini 系数为组的数据,在同一时刻有几组来自不同市场的数据,他们的 key 值相同,即是在同一时刻得出的模拟数据。
Reducer 方法处理以时间戳为 Key,以 GDP 或 Gini为 value 值的数据,在接收 Mapper 方法处理的数据时,判断如果是 GDP 值,则整合策略是将 key 值相同的 value 作和,如果是 Gini 系数则取平均数,经过Reduce 处理后,便将几个市场的数据进行整合,得出最终结果。
3 并行方法与传统方法的对比
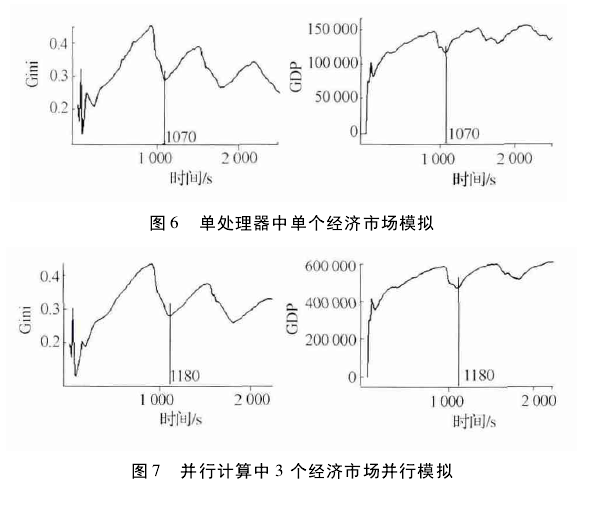
将 Hadoop 技术应用到经济模拟中,无论是资源利用率还是系统的整体效率都有很大的提高。在传输数据时,传统的数据处理方法是将所有数据逐条输入,依次经过 Mapper 和 Reducer 进行处理,最后输出结果。使用将数据映射到内存的方法,能够有效避免 map 到 reduce 阶段的网络 IO 和磁盘 IO 的开销。图 6 为在单个处理器上模拟单个市场,当模拟出现第 1 个波谷时所需要的时间为 1070 s; 图 7为使用 Hadoop 在 3 个处理器上并行整合 3 个模拟市场,所用的时间为 1180 s.如果只用 1 台处理器模拟多个市场,所需要的时间是所有模拟时间之和,并且不能整合3 个市场的 GDP 和 Gini 系数,如果只是单纯使用多个处理器进行模拟,只能得出每个市场的模拟结果,并不能将结果进行整合。使用Hadoop 并行技术进行模拟虽然模拟时间多出 110s,但由于是 3 个市场同时进行模拟,比非并行模拟节省了大量的时间,提高了系统的效率和资源利用率。
4 结束语
Hadoop 作为一种新的并行计算技术,应用到经图 6 单处理器中单个经济市场模拟图 7 并行计算中 3 个经济市场并行模拟济仿真模拟领域,拓宽了并行技术的应用领域,不仅能有效提高模拟的效率,增加系统的利用率,并且为拓宽经济模拟的深度和广度提供了一定的基础。如果要增加模拟市场的个数,只需要在之前配置好的并行环境中增加计算节点,将经济市场分别放置到不同的节点进行运算,最后将得出的模拟结果进行整合,得出最终的模拟结果。本文提出的方法未涉及市场间个体的交互,也没有考虑到市场的大小对经济模拟结果造成的影响。下一步工作中,可以通过改进数据整合方法,或改进主体的学习策略,以得到更好的并行模拟结果。
参考文献:
[1]Diebold F X,RudebuschG D. Measuring businesscycles: a modern perspective[R]. MassachusettsCambridge City: National Bureau of Economic Re-search,1994
[2]郝水侠,李凡长。 构建一种多 Agent 并行计算模型[J]. 计算机技术与发展,2006,16( 5) :71-73
[3]曹慕昆,冯玉强。 基于多 Agent 计算机仿真实验平台 Swarm 的综述[J]. 计算机应用研究,2005,28( 9) : 1-3
[4]Fortune S, Wyllie J. Parallelism in randomaccess machines[C]∥ Proceedings of the tenthannual ACM symposium on Theory ofcomputing.ACM,1978: 114-118
[5]Goldschlager L M. A universal interconnectionpattern for parallel computers[J]. Journal of theACM ( JACM) ,1982,29( 4) : 1073-1086
[6]Cole R,Zajicek O. The APRAM: Incorporatingasynchrony into the PRAM model





