摘要:为了快速地获取职位信息, 根据“前程无忧”的网页特点, 设计了3种基于Python的爬虫程序, 进行职位相关数据的抓取。通过对关键字的提取, 匹配符合条件的职位信息, 并且抓取相关内容存入Excel文件中, 便于寻找相关职位信息及具体要求。实验结果表明:该程序能够快速且大量地抓取相关职位信息, 针对性强, 简单易读, 有利于对职位信息的进一步挖掘及分析。
关键词:Python; 爬虫; 职位; 前程无忧;
Design on 51-job Data Scraping Program Based on Python
Abstract:In order to obtain job information quickly, according to the characteristics of web pages with“Worry-free Future”, three kinds of Python-based crawler programs are designed to capture job-related data. Through the extraction of the keywords, the job information is matched, and the relevant content is captured in an Excel file, so that the related job information and specific requirements can be easily found. The experimental results show that this program can quickly and massively capture relevant job information, and it is highly targeted and easy to read, which is conducive to further mining and analysis of job information.
Keyword:Python; crawler; position; Worry-free Future;
0、引言
随着互联网时代的高速发展, 大量的数据可以通过互联网来获得, 可以足不出户就能获知世界上的千变万化[1].我们可以在互联网上获取招聘信息, 而不再局限于报纸、杂志等纸质媒介, 这使得求职者可以快速有效地获得心仪的招聘信息。每年的9月和4月都是毕业生找工作的高峰时期, 快速有效地获得招聘信息成为求职过程中关键一步。为此, 本文设计了一款基于python的爬虫程序, 目前国内比较着名的求职软件有“智联招聘”“前程无忧”“58同城”等, 本文主要对“前程无忧”的招聘信息进行抓取并分析。现有的数据抓取程序抓取方式单一, 用户不能选择最快的抓取方法, 该程序针对此问题进行了进一步的优化, 设计3种数据抓取的方法, 用户可自行选择, 并且可以输入关键字, 匹配招聘信息的地点。设计更合理, 则用户使用体验效果会更好[2].
本文提出的程序通过爬虫获取职位信息, 包括:工作名称、标题、地点、公司名称、待遇范围、工作内容、招聘网址以及发布日期。并将获得的信息保存在本地, 以供后续的数据挖掘及分析。本文的爬虫程序包含3种爬虫的方法, 包括Re、XPath、Beatuiful Soup, 用户可以自行选择想要的爬虫方法, 并且输入职位的关键词, 通过关键词匹配, 获得相应的职位信息。
1、相关概念
1.1 Python语言
Python语言语法简单清晰、功能强大, 容易理解。可以在Windows、Linux等操作系统上运行;Python是一种面向对象的语言, 具有效率高、可简单地实现面向对象的编程等优点[3-4].Python是一种脚本语言, 语法简洁且支持动态输入, 使得Python在很多操作系统平台上都是一个比较理想的脚本语言, 尤其适用于快速的应用程序开发[5].Python包括针对网络协议的各个层次进行抽象封装的网络协议标准库, 这使得使用者可以对程序逻辑进行进一步的优化。其次, Python非常擅长处理字节流的各种模式, 具有很快的开发速度[6-7].
1.2 网络爬虫
网络爬虫[8] (Web Crawler) , 是一种按照一定的规则, 自动提取Web网页的应用程序或者脚本, 它是在搜索引擎上完成数据抓取的关键一步, 可以在Internet上下载网站页面。爬虫是为了将Internet上的网页保存到本地, 以供参考[9-10].爬虫是从一个或多个初始页面的URL, 通过分析页面源文件的URL, 抓取新的网页链接, 通过这些网页链接, 再继续寻找新的网页链接[11], 反复循环, 直到抓取和分析所有页面。当然这是理想情况下的执行情况, 根据现在公布的数据, 最好的搜索引擎也只爬取整个互联网不到一半的网页[12].
2、程序设计
本文的爬虫程序主要分为5个模块, 首先根据Request URL获取需要爬取数据的页面, 通过Re、XPath、Beautiful Soup三种方法, 利用关键词筛选符合条件的职位信息, 其中包括工作名称、标题、地点、公司名称、待遇范围、工作内容、招聘网址以及发布日期, 并保存在本地, 以便后续的数据挖掘及分析。
2.1 获取网页信息
爬取网页信息之前需要获取网页的信息, 并从中找出需要的信息进行抓取。首先打开Chrome浏览器, 进入前程无忧的网页, 打开开发者选项, 找到其中的network, 获取URL以及请求头中的headers[13].在preview中可以看到当前网页的源代码, 可以从源代码中找到需要爬取的信息, 即工作名称、标题、地点、公司名称、待遇范围、工作内容、招聘网址以及发布日期, 并找出当前页与下一页的offset值, 以便在以下的爬虫设计中使用。
2.2 主程序设计
将Beautiful Soup、XPath、Regex三种方法的文件名打包成字典, 并标上序号, 设计进入程序的页面, 在页面上显示提示信息, 请用户选择一种爬虫方法, 根据用户的选择, 进入对应的程序, 待用户输入需要查询的职位关键词之后启动爬虫程序, 开始抓取数据[14].在抓取完毕之后, 提示用户数据抓取完毕, 以保存至本地文件, 以供用户的使用及分析。
2.3 Re程序设计
正则表达式 (Re) 是对字符串 (包括普通字符 (例如, a~z之间的字母) 和特殊字符 (称为“元字符”) ) 操作的一种逻辑公式, 就是用事先定义好的一些特定字符及这些特定字符的组合, 组成一个“规则字符串”[15], 这个“规则字符串”用来表达对字符串的一种过滤逻辑。正则表达式是一种文本模式, 模式描述在搜索文本时要匹配的一个或多个字符串。
根据上文获取的网页信息, 可以将所需信息的字符串用Re表示出来, 其中:
通过获取的日期, 用户可以了解最新的职位信息。根据职位的详细信息, 求职者可以快速地了解到公司的要求以及职位的相关工作信息。通过上述的正则表达式获取的信息, 存入本地的Excel文件, 方便求职者查看。
2.4 XPath程序设计
XPath即为XML路径语言, 它是一种用来确定XML (标准通用标记语言的子集) 文档中某部分位置的语言[16].XPath基于XML的树状结构, 有不同类型的节点, 包括元素节点、属性节点和文本节点, 提供在数据结构树中找寻节点的能力。起初XPath的提出的初衷是将其作为一个通用的、介于XPointer与XSLT间的语法模型。但是XPath很快地被开发者采用来当作小型查询语言。
XPath相对于Re简单一些, Re语言容易出错, 导致无法正确地获得需要的信息, 通常可以在Chrome中添加XPath Helper插件, 可以在查看网页源代码是直接复制成XPath的格式, 方便且通常不容易出错。
在XPath程序中, 其中:
通过XPath和Re的代码对比, 可以明显发现, XPath的代码比Re的代码要简洁。
2.5 Beautiful Soup程序设计
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能[16].它是一个工具箱, 通过解析文档为用户提供需要抓取的数据, 因为简单, 所以不需要多少代码就可以写出一个完整的应用程序。Beautiful Soup自动将输入文档转换为Unicode编码, 输出文档转换为utf-8编码。不需要考虑编码方式, 除非文档没有指定一个编码方式, 这时, Beautiful Soup就不能自动识别编码方式了。然后, 仅仅需要说明一下原始编码方式就可以了。
2.5.1 解析库
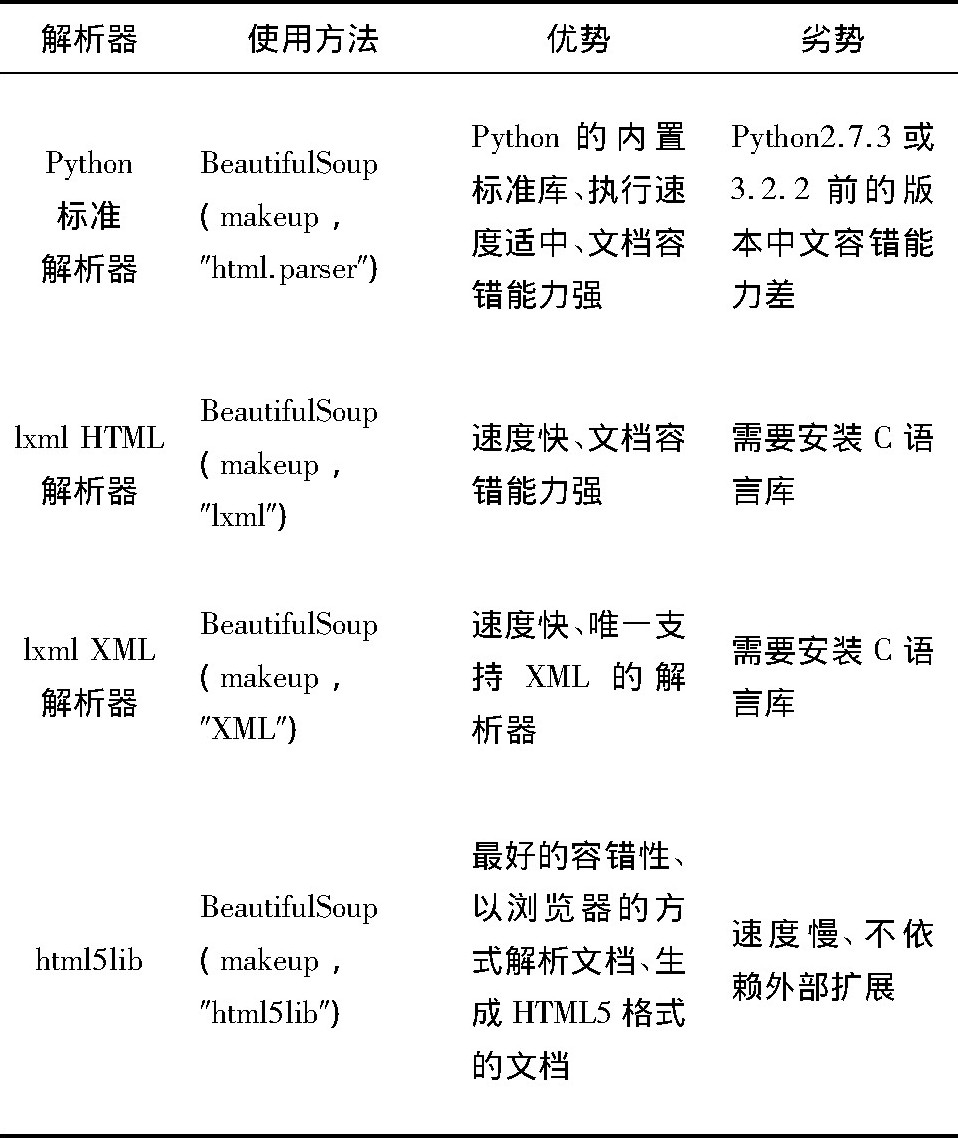
本文介绍几种python解析库, 并作比较, 如表1所示, 本文所用到的解析器是python标准解析器。
2.5.2 标签选择器
标签选择器可以选择元素, 获取名称、属性、内容, 可进行嵌套的选择, 能够获取子节点、子孙节点、父节点、祖先节点等。标签选择器可分为标准选择器和CSS选择器, 标签选择器可以根据标签名、属性、内容查找文档, 有两个常用的函数, 其中, find_all (name, attrs, recursive, text, **kwargs) 用来返回所有符合条件的元素;find (name, attrs, recursive, text, **kwargs) 用来返回第一个符合条件的元素。CSS选择器通过select () 直接传入CSS选择器即可完成元素的选择。
在本文设计的程序中, 选择了CSS选择器, 使用select () 函数完成数据的选择, 其中:‘int (str (soup.select ('div.rt span.dw_c_orange’) [0].next Sibling) ) '#获取当前页数
3、实验结果
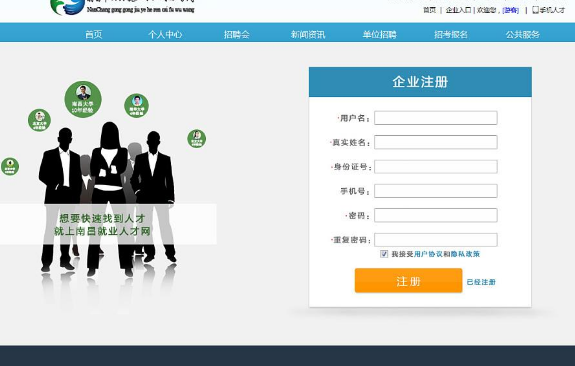
利用本文设计的爬虫程序, 进行了如下实验:首先进入主程序, 点击运行程序, 程序返回如图1的界面。
接着, 如图2所示, 输入数字“2”选择BeautifulSoup解析方式, 并输入关键词python启动爬虫, 程序正常运行。
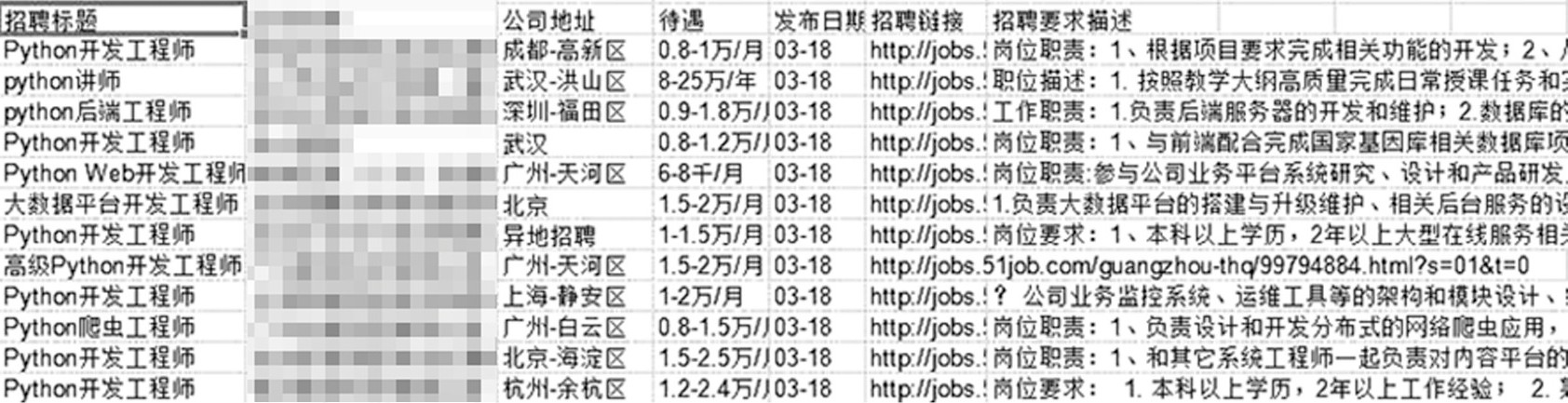
程序运行完毕后, 在本地文件夹中可以找到以“python职位”命名的Excel文件, 打开文件可看到如图3所示的信息。
4、结束语
本文根据Python语言简洁易读的特性设计了3种方法的爬虫程序, 用户可以自行选择数据解析的方法, 并输入需要查询的关键词, 即可从庞大的职位数据中提取出需要的数据, 方便快捷。本程序通过职位的关键词、工作地点等信息的匹配, 在一定程度上为使用者提供了便利。提取出的详细的职业信息描述, 可进行进一步的分词, 并统计词频, 观察单词出现的频率, 可更加快速地了解公司及相应职位的要求, 找到符合求职者的招聘信息。
参考文献
[1]房瑾堂。基于网络爬虫的在线教育平台设计与实现[D].北京:北京交通大学, 2016.
[2]王碧瑶。基于Python的网络爬虫技术研究[J].数字技术与应用, 2017 (5) :76-76.
[3]周中华, 张惠然, 谢江。基于Python的新浪微博数据爬虫[J].计算机应用, 2014, 34 (11) :3131-3134.
[4]涂小琴。基于Python爬虫的电影评论情感倾向性分析[J].现代计算机, 2017 (35) :52-55.
[5]郭丽蓉。基于Python的网络爬虫程序设计[J].电子技术与软件工程, 2017 (23) :248-249.
[6]Lutz M.Learning Python[M].北京:机械工业出版社, 2009.
[7]刘志凯, 张太红, 刘磊。基于Web的Python3编程环境[J].计算机系统应用, 2015, 24 (7) :236-239.
[8]王大伟。基于Python的Web API自动化测试方法研究[J].电子科学技术, 2015, 2 (5) :573-581.
[9]Hetland M L.Python基础教程[M].北京:人民邮电出版社, 2014:243-245.
[10]涂辉, 王锋, 商庆伟。Python3编程实现网络图片爬虫[J].电脑编程技巧与维护, 2017 (23) :21-22.
[11]高森。Python网络编程基础[M].北京:电子工业出版社, 2007.
[12]周立柱, 林玲。聚焦爬虫技术研究综述[J].计算机应用, 2005, 25 (9) :1965-1969.
[13]姜杉彪, 黄凯林, 卢昱江, 等。基于Python的专业网络爬虫的设计与实现[J].企业科技与发展, 2016 (8) :17-19.
[14]陈琳, 任芳。基于Python的新浪微博数据爬虫程序设计[J].信息系统工程, 2016 (9) :97-99.
[15]刘娜。Python正则表达式高级特性研究[J].电脑编程技巧与维护, 2015 (22) :12-13.
[16]齐鹏, 李隐峰, 宋玉伟。基于Python的Web数据采集技术[J].电子科技, 2012, 25 (11) :118-120.