摘要:为了提高测试效率,需要筛选出高质量的测试用例,传统聚类算法在计算时会产生误差,易产生多个簇,导致聚类效果不佳。结合测试用例的特点,本文提出一种增量聚类算法T_Single-Pass(Testcase_Single-Pass),首先通过句子的语法结构判断出每个词的词性,选取名词作为计算对象。接着根据词所在用例的位置计算权重值,选取权重值前三的进行向量表示。最后采用曼哈顿公式融入时间因素来计算与当前已有聚类中心对象的相关性。在现有企业所用的安卓系统性能测试用例集上进行验证,比较K-Means、传统Single-Pass以及本文提出的算法,得出本文的方法聚类效果最佳。
关键词:测试用例; 相似度; 增量聚类; 时间因素;
Test Case Oriented Chinese Text Clustering Analysis
LI Jing-wei
School of Computer Science, Nanjing University of Posts and Telecommunications
Abstract:In order to improve the test efficiency, it is necessary to select high-quality test cases, the traditional clustering algorithm will produce errors in calculation, which is easy to produce multiple clusters, resulting in poor clustering effect. Combined with the characteristics of test cases, this paper proposes an incremental clustering algorithm T_Single-Pass(Testcase_Single-Pass),first of all, the part of speech of each word is determined by the syntactic structure of the sentence, and the noun is selected as the calculation object. Then, the weight value is calculated according to the position of the word case, and the top three weight values are selected for vector representation. Finally, the Manhattan formula is used to calculate the correlation with the existing cluster centers. The results show that the clustering effect of this method is the best by comparing K-means, traditional Single-Pass and the algorithm proposed in this paper.
0 引言
测试用例[1]的设计是整个测试工作中最重要的一环,也是整个测试流程中难度最大的部分,往往是在同一时间段对同一对象设计一系列测试用例,通常以中文文本的形式表示。测试用例会随着应用功能的扩展不断完善,并且在不同的领域有不同的用例,相应的侧重点也有所不同。测试用例是由多个人员共同评审出的产物,由于编写习惯不一样,因此在更新用例的过程中难免会有一些相类似的混合在其中。为了提高用例的质量,需要对用例进行去重,然而在实际工作中测试人员往往是通过人工来判断筛选,效率低下。但是如果直接对现有测试用例进行文本分析会造成漏删或误删,为此提出先对测试用例进行聚类分析的想法。
传统聚类方法一般采用批量处理,即每当有数据增加或更新的时候,必须对整个数据集进行重新操作[2],消耗时间会随着数据的增加而大幅度地增加,同时聚类效果也会有所下降。K-Means[3]聚类方法会计算每个点到质心的距离再去分配实例点,在簇数量设置合理的情况下,不易产生小簇,但是K-Means的簇数量设置的多少会影响得到的簇的大小。增量聚类则是对已有聚类结果的扩充,不仅能够有效地提高聚类性能,还会降低计算时间复杂度,且易于聚类结果的后期维护,具有代表性的是Single-Pass算法[4],只需要直接处理小簇即可计算得到两个词语以上的簇内的词语之间相关性。本文针对测试用例数据稀疏性大、上下文信息不足等特性,对已有聚类算法进行改进,提出一种合适的增量聚类算法T_Single-Pass。
1 相关工作
聚类主要是将离散的数据集依某些特征分别聚集成群,聚类方法大致可分成两类:阶层式与非阶层式[5]。阶层式将数据层层反复地进行分裂或聚合,只需计算每个数据点的距离。当需要某一个特定范围的聚类结果,就必须从头做起,耗时较久。非阶层式通过一套迭代的数学运算法,找出最佳的聚类方式,数据集仅需处理一次,计算效率高且复杂度低[6],不会发生多重隶属的聚类模糊状况,聚类获取出对象与对象之间共同描述的问题,使问题与对象形成父子阶层关系,增量聚类就是非阶层式聚类法。
增量聚类的研究可以分为两类:一类是每次迭代所有数据,一类是利用前一次聚类的结果来划分一个数据并指向现有的簇。陶舒怡等[7]利用词项之间的语义信息,计算新增文本与已有簇之间的相合性实现增量聚类,但此种方法仍有一定比例的错误项,需要对错误的聚类进行再分配。殷风景等[8]先进行初步聚类,再将初步类与已有类进行比较和聚合,避免了聚类结果由于数据顺序不同发生变化,但是需要进行多次聚类,随着数据的增加,消耗的时间成正比增长。Tien等[9]提出了一种基于加权聚类模型的增量在线多标签分类方法,通过每个样本的权值随时间减小的衰退机制来适应数据的变化,但是此种方法在大规模数据下可行度并不高。
通过上述对现有工作的调研发现,现有增量聚类算法依然还有以下挑战:如何有效降低特征维数,加快运行速度,同时不降低聚类的效果,将新增文本高效的分配到最合适的簇中。
2 算法设计与实现
2.1 字词权重计算与选取
为节省系统的运算时间,本文仅取出足够代表文本对象的关键词进行比较判断。测试用例文本由动词、名词和量词等组成,选取名词作为一条用例的对象表示,有的测试用例在进行分词处理后不能很好的判断词性。比如“进入设置,设置页面中的个人信息”,根据语义判断出“设置”既有动词也有名词的词性。结合句子的语法结构进行词性判断,名词与动词搭配的情况有如下几种:名词+动词、名词+名词、动词+名词。测试用例中动词一般都是“打开”“点击”等,这些动词在初始判断时出错的概率几乎为0,围绕动词为中心,观察动词前后字词的词性,如果是名词记为0,动词记为1,其他词性记为2。以上述例子为例,以标点符号为分割线,标记的结果应该是11|102200,通过词性搭配可知第二个词并非是动词而是名词。以此类推,重新判断出每个用例中字词的词性。
考虑特征词与出现该词的用例数之间的关系,计算特征词在整个用例集中出现的频率。由于性能用例中多条用例都会涉及到“时间”等字眼,但这些名词并不能代表用例的核心对象,为此对不同位置的对象赋予不同的加权值。将用例中的名词特征项分别用k1、k2、…、kn表示,di=(wi1,wi2,wi3,…,win)表示文本Di中的第i条测试用例,win表示特征项kn在文本Di中的权重,结合TF-IDF[10]的计算思想,提出适合用例特征的计算方法,计算公式如(1)所示:
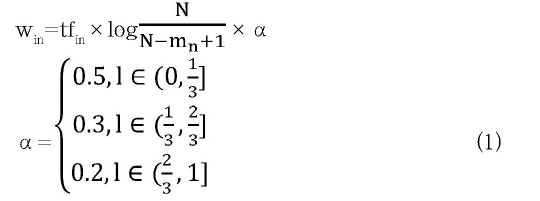
其中,tfin表示在文本Di中特征项kn出现的频率,N表示所有用例的数量,mn表示存在特征项kn的用例数,α表示用例不同位置对应的加权值,l表示从左至右划分的用例长度占总长度的比例,分别表示用例的开始、中间、结束三部分,如果一个词被拆分成两部分,以左边的为准进行权值计算。将计算的结果进行降序排序,选取排名前三的名词特征项。
2.2 相似度计算与聚类
由于在增量聚类的过程中需要反复计算与已有簇的相似度,为了减少计算过程中取近似值产生的误差,本文采用相对简单且可以在较大范围内求取最优解的曼哈顿距离公式来计算,将第一条测试用例中字词权重值最高的特征向量作为第一个簇,并以其为簇的中心。假设第X条测试用例文本特征项对应的特征向量为Xi=(xi1,xi2,xi3,…,xin),(i=1,2,3),已产生的簇中心所在第Y条测试用例特征项对应的特征向量为Y=(y1,y2,y3,…,yn),特征向量中每个值表示测试用例中每个选出的特征项在所有词中所占的权值,把未出现的词设置为0。通过特征向量中特征项的权重来计算与已有簇之间的距离,计算公式如(2)所示:

测试用例具有阶段性,即用例在创建的时候,同一时间段编写的用例中出现同一对象的可能性较高。结合用例的这一特性,为了提高划分到对应聚类类别的准确度,在计算新增测试用例与各已知对象群集的相似度时,融入创建时间顺序这个要素来计算相似度。具体公式如(3)所示:
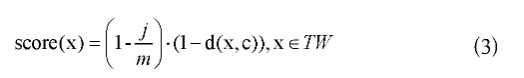
其中x代表新增用例,c代表已经产生的一个簇中心对应的测试用例,j表示介于x以及c对应的簇中最新的一条测试用例之间所增加的用例数,前提是最新的一条测试用例要属于TW,如果不属于TW,j的值设为0,TW表示时间区间,时间区间指的是同时上传用例所在的时间范围,m为现有用例集中所有的用例数。在此,score(x)若大于门槛值,则标定新增测试用例x存在旧对象;反之用例中存在新对象。由公式(3)可知在一个群集中最新加入的用例与要新增的用例之间增加的用例总数越多,新增测试用例与该测试对象群集越疏离、越不相关。
2.3 算法流程
本文提出的T_Single-Pass算法主要包含了文本预处理(分词、词性划分)、文本降维、特征选取、相似度计算等方面。具体步骤如下:
步骤一:采用hanlp对文本进行分词,通过隐马尔可夫模型对词性进行标注,结合句子的语法结构进行分析,对判断错误的词性重新标注。选取名词作为最终的测试对象集合,通过公式(1)计算出名词在用例中的权重并降序排序,选择排名前三的词作为特征词。
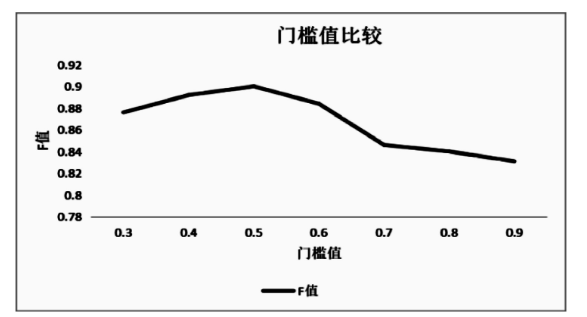
图1 门槛值选取比较
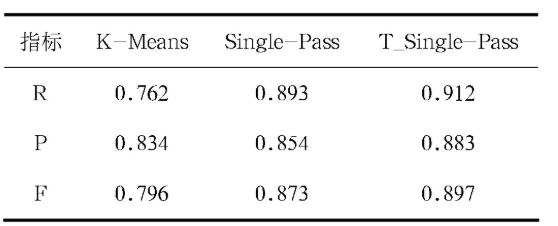
表1 几种算法的评测结果
步骤二:读取已有测试用例集中第一条测试用例D1,根据步骤一计算结果选取第一条用例中权值最高的特征词当作群集C1。
步骤三:当用例并非已有用例集中第一条或是属于新增测试用例时,所有测试用例文本Di一一与现有的所有群集Ci作相似度的计算,根据计算结果,判断与已有对象群集的相关性。如果与现有群集有相关的,分析结束,将其划分到最高相似度对应群集中。如果不相关,重新调整用例的群集向量进行计算,否则该用例形成一个新的群集。
步骤四:重复步骤三,直到没有新的用例。
3 实验与分析
3.1 评测数据
本实验所用数据集是从现有公司获取的面向安卓系统的性能测试用例集,其中包含1080条测试用例,包含响应时间、启动时间、滑动流畅度、内存泄露等方面。用Excel表格进行文本表示,文本中每一行代表一个测试用例,按照创建时间顺序依次排列,本文的测试用例由具有代表性的测试步骤组成。
3.2 评测指标

3.3 评测环境
系统环境:Windows 10;CPU:AMD Ryzen 5 2500U;内存:8G;系统类型:64位;编程语言:Java;开发环境:Eclipse。
3.4 重要参数选择
在计算文本相似度时门槛值的设置也是十分关键的,设置太高或太低都有可能直接影响最后的聚类效果,太高会导致聚类类别过细,太低会导致聚类类别精确度不高,为了得到更好的相似度计算结果,设置不同的门槛值进行比较,实验数据如图1所示。
由图1可知,当门槛值小于或大于0.5时,F值均不是最优解,所以综合考虑本文选择门槛值为0.5进行实验。
3.5 评测结果
本文选取K-Means、Single-Pass、T_Single-Pass三种方法进行比较。在保证所有条件比如用例数量、大小等一致的前提下,首先选取前800条测试用例进行聚类,接着将剩余的280条用例分成7份,依次在不同的时间段内上传用例文本,对新增文本聚类。得出对应的R、P、F指标结果如表1所示。
从实验数据上看,所有的方法都具有不错的聚类分析结果,Si n gl e-P a ss算法明显优于K-M ea n s,但是T_Single-Pass具有更好的准确度。与此同时,通过K-Means算法产生13个簇,Single-Pass算法产生15个簇,本文采用的方法最终产生13个簇。综合考虑,本文的改进方法在聚类准确性和簇划分个数判断效果最佳。
4 总结
在聚类时由于测试用例依赖传输顺序、词性有歧义等特点,需要对新增用例重复比较、判断、分析,进而影响聚类效果。本文在Single-Pass算法基础上对数据进行预处理,选取对计算结果有意义的词,结合时间概念与曼哈顿距离进行文本相似度计算。实验表明本文改进的方法相比较K-means、Single-Pass等方法在效率和准确率上有所提升。在之后的应用中改变以往的人工筛选用例的方式,能在减少人力消耗的同时提高测试用例的筛选效率和准确率。然而现阶段在文本聚类分析中仍有一些问题亟待解决,比如如何对新增文本进行数据分配,以提高聚类性能等。
参考文献
[1] TIAN T,GONG D W.Evolutionary generation approach of test data for multiple paths coverage of Test Data for Multiple Paths Coverage of Message-passing Parallel Programs[J].Chinese Journal of Electronics,2014,23(2):291-296.
[2]刘欣,佘贤栋,唐永旺.基于特征词向量的短文本聚类算法[J].数据采集与处理,2017(5):1052-1060.
[3] P S Xiang.A Cloud Detection Algorithm for MODIS Images Combining Kmeans Clustering and Otsu Method,2018,392(6):392-396.
[4] Michael J.Klaiber,Donald G.Bailey,Sven Simon.Comparative Study and Proof of Single-Pass Connected Components Algorithms,2019,61(8):1112-1134.
[5]刘宏哲,须德.基于本体的语义相似度和相关度计算研究综述[J].计算机科学,2012(2):8-13.
[6] Junpeng Bao,Wenqing Wang,Tianshe Yang,et al.An incremental clustering method based on the boundary profile,2018,13(4):13-16.
[7]陶舒怡,王明文,万剑怡,等.一种基于簇相合性的文本增量聚类算法[J].计算机工程,2014(6):195-200.
[8]殷风景,肖卫东,葛斌,等.一种面向网络话题发现的增量文本聚类算法[J].计算机应用研究,2011(1):54-57.
[9] Tien Thanh Nguyen,Manh Truong Dang,Anh Vu Luong,Alan WeeChung Liew,Tiancai Liang,John McCall.Multi-label classification via incremental clustering on an evolving data stream[J].Pattern Recognition,2019,95(6):96-113.
[10]周丽杰,于伟海.基于改进的TF-IDF方法的文本相似度算法研究[J].泰山学院学报,2015(3):18-22.





