摘要:研究了聚类分析方法在接触网动态检测数据分析中的应用。选取弓网接触力动态检测特征数据,分别采用传统判别方法、谱系聚类和模糊C均值聚类方法,对动态检测数据进行了聚类分析。研究结果表明,与传统判别方法不同,聚类分析判别接触力缺陷的方法不依赖于接触力的绝对值,通过判别接触力检测数据中的离群点确定缺陷可能存在的位置。通过数据分析,谱系聚类方法不忽略数据极值点,谱系聚类优于模糊C均值聚类方法。采用聚类方法解决了受电弓静态接触力不同、受电弓-接触网结构形式不同引起的接触力缺陷漏判、误判的问题。
关键词:弓网接触力; 动态检测; 聚类分析;
Abstract:This paper studies the application of cluster analysis method for analyzing the catenary dynamic inspection data. The characteristic data is selected for dynamic inspection of pantograph-catenary contact force, and the traditional discrimination method, pedigree clustering method and fuzzy C-means clustering method are used to cluster the dynamic inspection data. The results show that it is different from the traditional methods, the method of cluster analysis does not depend on the absolute value of contact force, and the possible position of defects can be determined by distinguishing outliers in contact force inspection data. Through the data analysis, the pedigree clustering method does not ignore the data extreme points, and the pedigree clustering method is better than the fuzzy C-means clustering method. The clustering method is used to solve the problems of missing judgment and misjudgment of contact force defects caused by different static contact force of pantograph and different structure form of pantograph-catenary.
0 引言
在数据挖掘中,分类分析是一种监督学习的分类方式,通过构建分类模型,预先定义数据类,将数据按照数据特征分入预定的数据类[1]。聚类分析是一种无监督学习的分类方式,不对数据类进行预先定义,而是根据数据的特征对数据进行划分。
我国高速铁路接触网动态检测一般采用综合检测列车对接触网平顺性和弓网受流性能进行检测和评价,检测中产生了包括弓网接触力、硬点等大量检测数据。目前对弓网性能的评价主要是根据检测数据的极值、均值、方差等,与现有标准数值或标准曲线进行对比,根据检测数据是否超出限值判断是否存在缺陷,这种方法本质上是一种分类的方法[2]。在我国,接触网系统采用不同的结构形式、接触线高度、张力组合,受电弓也采用多种不同型号,如DSA系列、法维莱CX系列等,造成了弓网关系的千差万别,同一列动车组在不同接触线高度的线路上运行,弓网接触力可能存在较大差异,可能存在一条线路检测数据普遍偏大或偏小的情况,导致通过标准对比的分类分析方法会产生很多缺陷误判和漏判。而聚类分析不依赖于接触力的绝对值,通过判别接触力的离群点确定接触力缺陷可能出现的位置,该方法是对接触网检测数据缺陷识别的有益探索。
1 聚类分析理论
聚类分析是一种有效的数据挖掘工具,已经广泛应用在图像识别、网络搜索和生物学等领域。谱系聚类和模糊C均值聚类是应用较为广泛的聚类方法。
1.1 谱系聚类
为了说明谱系聚类的方法,首先定义欧式空间中n个数据对象的p维观测数据:
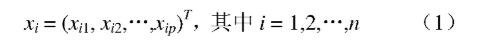
谱系聚类是先将每个数据对象看成一个小类,将与之最相似的样品聚为一个小类,再将小类按照相似性再次聚类,从而得到一个按相似性进行聚合的谱系图。
将n个数据对象作为n个类,即G1={x1},G2={x2},…Gn={xn},计算任意2个类之间的欧式距离,可以得到距离矩阵D。
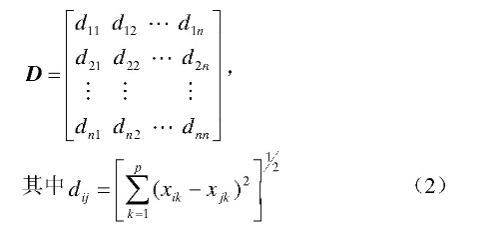
可以看出,D是一个对称矩阵。从非主对角线上找到最小元素,设该元素为dpq,则Gp、Gq合成一个新类Gr=(Gp,Gq),这样在距离矩阵D中可以去掉Gp、Gq所在的2行、2列,并加上一个新的类Gr与其余各类之间的距离,得到n-1阶矩阵D1;重复以上步骤,直到全部数据对象聚成一个类为止。
1.2 模糊C均值聚类
模糊C均值聚类是一种软聚类,是在硬C均值聚类的基础上推广产生的基于概率模型的一种聚类方法。硬聚类划分是指一个数据一定属于某一个特定的类,而软聚类是将一个数据按照一定的概率分属于不同的类。在模糊聚类算法中,模糊C均值聚类算法应用最为广泛,通过优化目标函数得到每个数据点对所有聚类中心的隶属度,从而决定样本点的类属,以达到自动对样本数据进行分类的目的。
设p维观测数据集X=(X1,X2,…,Xn),样本容量为n。按硬聚类方式可将X划分为c类,即X1,X2,…,Xc,表示为
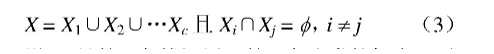
设uij是第j个数据属于第i个聚类的概率,则

U=(uij)是一个c×n阶矩阵,称该矩阵为隶属度矩阵,其中每列元素只有一个为1,其余均为0。
如果按一定的目标函数计算,将隶属度矩阵定义为,且uij≥0,此时的聚类称为模糊C均值聚类。模糊C均值聚类的优化目标函数为[3]
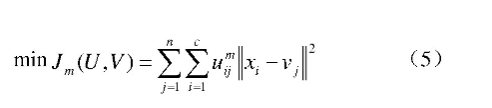
其中:V={v1,v2,v3,…,vc}?R,1<c<n,为聚类中心;m为加权指数,m>1,m的取值将影响聚类的效果。
当目标函数Jm(U,V)取得最小值时,模糊C均值聚类取得最优结果。
聚类中心和聚类隶属度通过以下方法求解:
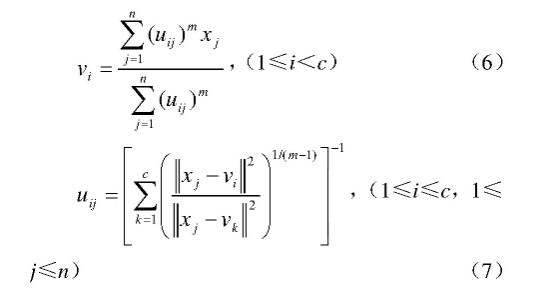
通过不断迭代求解,直至目标函数计算结果在控制误差范围之内。具体求解可通过计算机程序完成,计算步骤如下:
第1步:给定分类数c、加权指数m、误差值ε,初始化隶属度矩阵U=(uij);
第2步:计算聚类中心vi;
第3步:计算隶属度uij;
第4步:判断目标函数Jm(U,V)是否小于给定误差值ε,若小于,则聚类结束,否则重复第2步至第4步,直到目标函数Jm(U,V)小于给定误差值ε。
2 弓网接触力动态检测数据分析
2.1 传统数据分析方法
根据现有检测标准TB 10761-2013《高速铁路工程动态验收技术规范》,弓网接触力动态检测数据的评判标准为[4]

式中:Fm为弓网接触力平均值,N;v为检测速度,km/h。
从现有评判标准公式中可以看出,弓网接触力的标准值仅与速度相关,与其他因素无关。在我国铁路现有实际运行状态下,存在多种不同型号受电弓与不同结构、不同高度、不同张力组合的接触网相互匹配运行的情况。如设计速度300 km/h以上的高速铁路,多在用弹性链形悬挂、接触线高度5 300 mm的参数,而200 km/h及以下速度等级铁路常采用简单链形悬挂,接触线高度有5 300、5 500、6 450 mm等多种参数。同一型号受电弓在不同结构、不同高度的接触网下运行,表现的性能不尽相同,不同型号受电弓跨交路运行,更会出现不同特性的弓网关系。因此仅以弓网接触力公式(8)对弓网接触力缺陷进行评价是不够完善的,会造成误判或漏判。如某种运行工况下,弓网接触力整体偏小,按照式(8)进行评判,其结果可能是全部满足标准要求,而可能的缺陷点会被漏判;又如在某种工况下,弓网接触力整体偏大,按照式(8)可能会评判出多处接触力缺陷点,而这些缺陷点多是由于在该工况下接触力整体偏大造成的,并非接触网缺陷点,造成弓网接触力缺陷点误判。
选取70跨弓网接触力动态检测数据,检测速度(260±3) km/h,采用传统的方法,按照式(8)对接触力进行评价,传统方法可以看作是一种分类方法,将数据按照接触力标准限值曲线分成2类。检测数据如图1所示,包括弓网接触力、接触力标准差、燃弧时间等检测数据,同时绘制了接触力限值曲线。图1中横坐标为数据点数,接触力、标准偏差、接触力限值的纵坐标单位为N,燃弧时间的纵坐标单位为ms。采用传统方法,可以得出接触力超限点,如表1所示,共有超限数据12个。
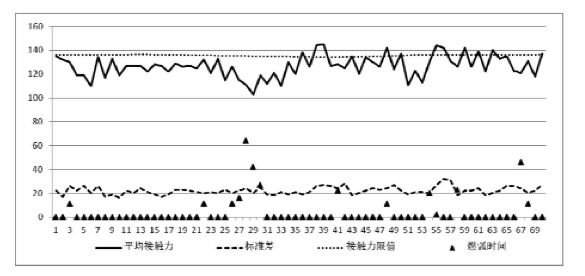
图1 接触网动态检测数据
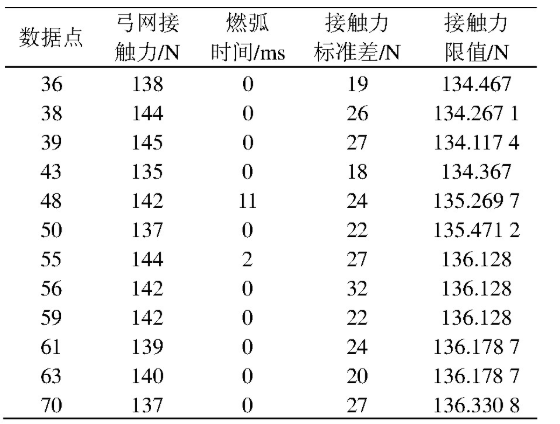
表1 接触力超限点
2.2 谱系聚类分析
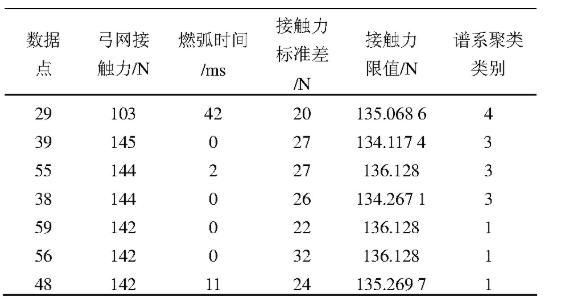
采用谱系聚类的方法,同样对以上70跨检测数据进行聚类分析,可以得到如图2所示聚类结果,其横坐标表示数据点数,纵坐标表示数据间的欧式空间距离,无量纲。可以根据谱系聚类图的聚类距离将数据分成4类,表2中所示数据点类别为1、3、4类,其余数据点分类均为2类,表2所示接触力的数据为离群点。1、3两类数据点均包含在表1超限点数据表中。数据点29分类为4类,不在表1中。数据点29接触力为103 N,燃弧时间为42 ms,在图1中亦可发现数据点29附近燃弧较大,接触力较小,可以判断该数据点存在缺陷可能性较大。
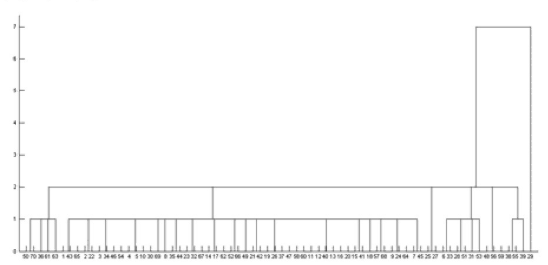
图2 检测数据谱系聚类示意图
表2 谱系聚类分析结果
2.3 模糊C均值聚类分析
采用模糊C均值聚类分析方法对以上弓网接触力动态检测数据进行处理,仍将数据分为4类,可得到4类数据的聚类中心:第1类129.133;第2类111.112;第3类140.312;第4类120.914。可以看出,第2、3类为距离接触力检测均值较远的聚类中心,接触力离群点均可能在此两类中出现,如图3所示。
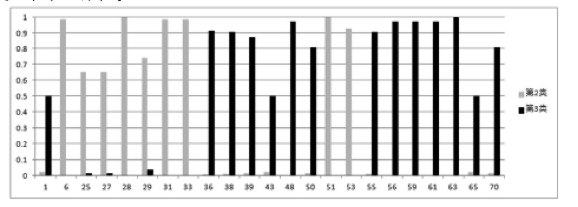
图3 第2类、第3类数据隶属度柱状图
根据隶属度矩阵,以隶属度大于0.95为标准,得到第2类和第3类中隶属度大于0.95的数据点,如表3所示。
表3 模糊C均值聚类数据点
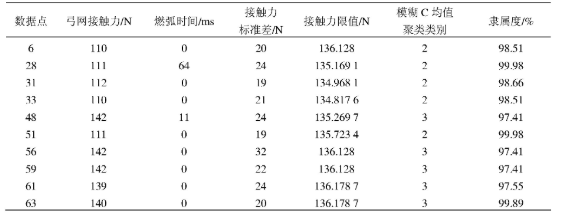
由表3可以看出,与谱系聚类分析方法相比,模糊C均值聚类分析得出的数据点缺少数据点29、38、55等极值点,这是因为模糊C均值聚类是根据聚类中心确定各数据点的隶属度,极值点对数据中心隶属度不高,所以极值点存在被忽略的情况。由此可以看出,谱系聚类的方法优于模糊C均值聚类。
3 结论
传统的接触力缺陷判别方法依赖于接触力的绝对值与标准值对比,在实际工况中,不同接触线高度的弓网接触力数值存在较大差异,而且运用动车组受电弓静态接触力不是固定值,多按70~90 N调整,检测出的弓网接触力动态值会存在显着差异,这些因素都会对弓网接触力缺陷判别产生较大影响。而采用聚类分析的方法,接触力缺陷点的判别不依赖于接触力的绝对值,而是通过欧氏距离、聚类中心对接触力进行分类,判断出接触力检测数据中的离群点,离群点即为较大可能存在缺陷的位置。与模糊C均值聚类相比,谱系聚类不会丢失极值点,谱系聚类方法更优。与传统的接触力缺陷判别相比,谱系聚类方法的优点较为明显。
参考文献
[1](美)韩家炜(Han.J).数据挖掘:概念与技术[M].北京:机械工业出版社,2012:10-15.
[2]王志良,田亮.高速铁路接触网质量综合评价指标研究及应用[J].电气化铁道,2019,30(s1):144-146.
[3]李柏年,吴礼斌. MATLAB数据分析方法[M].北京:机械工业出版社,2012:141-150.
[4] 中华人民共和国铁道部. TB 10761-2013高速铁路工程动态验收技术规范[S].北京:中国铁道出版社,2013.





